
AI・機械学習チームの(中村@po3rin)です。
今年もこの季節がやってきました。エムスリーAI・機械学習チームの最強MR決定戦のお時間です。
MRとはMerge Requestの略称です。 GitHubでいうところのPR (Pull Request) にあたります。
この記事ではAI・機械学習チームが毎年恒例で行なっているベストMRのトップ10について発表します。 このベストMRはチーム内でこれは最高だった!というMRをノミネートしていき、その中で決選投票をしてベスト10を決めました。 今年も熾烈な闘いを勝ち上がった至極のMRがノミネートされました。
では、10位からご覧ください。と、言いたいところですが、今年は同票のため11位から紹介します。 このブログの内容は、投票した人の中から紹介者を決めて、実装者のやったMRを紹介するスタイルで書かれました。
- 第11位 CronJobの監視シート記入漏れを事前警告する
- 第10位 機械学習モデルのアンサンブルを高速化
- 第9位 社内ライブラリにpanderaを導入
- 第8位 Cruftの導入
- 第7位 不定期な依頼ベースの実行をslackワークフロー化
- 第6位 スクリプト1発で、ユーザーグループ毎に予測モデルを最適化
- 第5位 Prometheusを利用して、カスタムエラー通知を作成する
- 第4位 ChatGPT連携SlackBotの爆速爆誕
- 第3位 可能な限り公式PyPIを使う
- 第2位 社内ライブラリの負債を一気に解消
- 第1位 poetry lock を高速化するための制約を追加
- まとめ: MLエンジンを高速リリースするための基礎開発とは
- We are hiring!!!
第11位 CronJobの監視シート記入漏れを事前警告する
- 紹介者: 高田
- 実装者: 三浦
AI・機械学習チームでは数多くのプロダクトでBatchやAPIをGKE上で運用しています。特にBatchについてはスケジューリング実行にCronJobを採用しており、 CronJobが想定の時間内に終わったかをモニタリングするSLO監視も内製しています。
SLO監視の手順として次の2ステップが必要になります。
- CronJobを作成する
- スプレッドシートにSLO基準の終了時刻を記入する
しかし1で満足してしまい2を忘れてしまうケースが定期的に発生していました。仮に正常にJobが終了していても、2を忘れるとslackのエラー通知チャンネルに通知が飛んで寿命が縮む思いをしてしまいます。
そこで本MRでは、チームの通常業務用チャンネルに警告の意味合いで記入漏れを通知することでスプレッドシートへの記入を促し、エラー通知チャンネルへの通知という一発レッドカードを回避することが可能になりました。
各メンバーが多くのプロダクト開発を担当するAI・機械学習チームにとって、運用負荷を下げたことが評価され入賞しました。
第10位 機械学習モデルのアンサンブルを高速化

- 紹介者: 氏家
- 実装者: 池嶋
AI・機械学習チームでは多くの機械学習モデルを開発、運用しています。その中で、精度が高くなるようにいくつかのモデルを組み合わせる(アンサンブル)ことが頻繁に起こります。 n個のモデルのm個の組み合わせを考慮するためにはnCm通りの計算が必要であり、当初は愚直に全探索する実装だったためにmが大きくなるにつれて膨大な時間がかかっていました。 このMRでは、そのアンサンブルを行列積としてリファクタリングすることで計算を効率化し、結果として数分かかっていたアンサンブルが数秒まで短縮されました。 非効率な実装をアルゴリズム力で効率化しているというAIチームらしさから堂々の10位入賞となりました。
第9位 社内ライブラリにpanderaを導入
- 紹介者: 農見
- 実装者: 池嶋
今までも独自のラッパーを作成して、型チェックは行ってたのですが、nullがないか、数値が0以上か等の確認はできてませんでした。そこでpanderaを導入して全てのカラムを色んな条件で型チェックできるようにしました。panderaはデータフレームのバリデーションをするのに、とても便利なのでおすすめです。
第8位 Cruftの導入
- 紹介者: 池嶋
- 実装者: 中村
cruftというツールを導入して、最新cookiecutter templateへの追従を楽にできるようにしました。 最新cookiecutter templateに追従してない場合、警告してくれるようにCIを設定し、templateを更新するだけで、他プロジェクトにその更新を促せるようになりました。これに関してはブログも公開しています。
第7位 不定期な依頼ベースの実行をslackワークフロー化
- 紹介者: 池嶋
- 実装者: 須藤
AIチームではビジネスサイドとの連携が密接になっており、依頼ベースでの不定期な機械学習バッチが多数存在しています。 これらはKubernetes上へバッチのデプロイが必要だったため、AIチームのエンジニアによってデプロイが行われていました。 しかし、依頼が増えるに連れ、段々と対応の工数が増えて来る問題が発生していました。
そこで、これらのバッチの一部をslackワークフローと連携させることで、エンジニアでなくても簡単にKubernetesへのバッチデプロイを可能にしました。 依頼が多数重なり、AIチームのエンジニアが対応に追われる、なんてケースはもうなくなりました。 また、ビジネスサイドのメンバーが設定を多少調整して試行錯誤することも可能なので、AIチームとビジネスサイドの間の相談に起因するリードタイムも大幅に短くすることができました。
第6位 スクリプト1発で、ユーザーグループ毎に予測モデルを最適化
- 紹介者: 謝
- 実装者: 池嶋
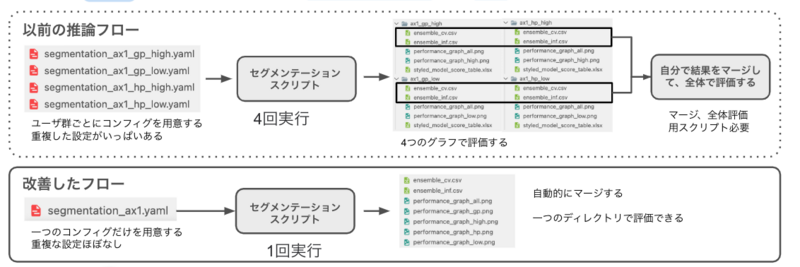
ユーザーの興味にあったコンテンツを予測するために、ユーザーのクラスタリングスコアのセグメンテーションが必要です。ユーザグループごとに異なるセグメンテーションの閾値を決定することが必要なので、セグメンテーションは恐らく分析プロセスで最も時間がかかる部分です。過去には、AIチームのエンジニアは以下の手順が必要でした:
- ユーザーグループごとにセグメンテーションコンフィグを用意します。
- ユーザーグループごとにセグメンテーションスクリプト一つずつを実行します。
- 各グループの出力ディレクトリの性能グラフをチェックします。
- 各グループの結果を結合するためのカスタムスクリプトを作成、実行します。
以上の作業手順を減らすために、このMRではセグメンテーションのワークフローを改善しています。今では、1つのコンフィグを用意するだけで済み、スクリプトを1回だけ実行すればよいようになりました。結果は自動的に結合され、すべての性能グラフは1つのディレクトリにまとめられます。これにより効率が二倍以上大幅に向上し、コンフィグの作成や結果の結合時に発生する手動ミスも防止できます。
第5位 Prometheusを利用して、カスタムエラー通知を作成する
- 紹介者: 浮田
- 実装者: 北川
このMRが対象としたプロダクトでは、ビジネスサイドに入力してもらったデータをDBに投入し、そのDBをAPIから叩くというアーキテクチャになっています。その際、誤って不正なデータが入力されてしまうことがあり、その場合APIのリクエストに失敗するので、何かしら不正を検知して通知をすることが必要になります (今回はSlack通知を使用)。
単純にDBと整合していないAPIリクエストが来たときにSlack通知をするようにしてしまうと、リクエスト数ぶんの通知が飛んできてしまい、通知が見にくくなってしまいます。
そこでこのMRでは、PrometheusとGoogle Cloud Monitoringを使ってカスタムエラー通知を作ることで、そのような通知を実現しています。チームで新しいツールを導入して問題を解決したという点も良く、堂々の5位入賞となりました。
第4位 ChatGPT連携SlackBotの爆速爆誕
- 紹介者: 横本
- 実装者: 北川
ChatGPTは言わずもがな生産性を大きく高めてくれるサービスで、エムスリーでも最初期から導入が検討されました。 現在ではChatGPT Enterpriseなどの整備が進んでいるChatGPTですが、サービス開始当初の(特にWeb UI版の)利用規約はエムスリーでそのまま導入するにはハードルの高いものとなっていました。そこで、ガバナンスを担保しつつChatGPTを利用できる方法としてSlack Botを間に挟むことにしました。
という方針が決まって「誰かつくらない?」と話が出た翌日には稼働開始という爆速っぷりで開発されたMR(というかリポジトリ)が第4位に選ばれました。
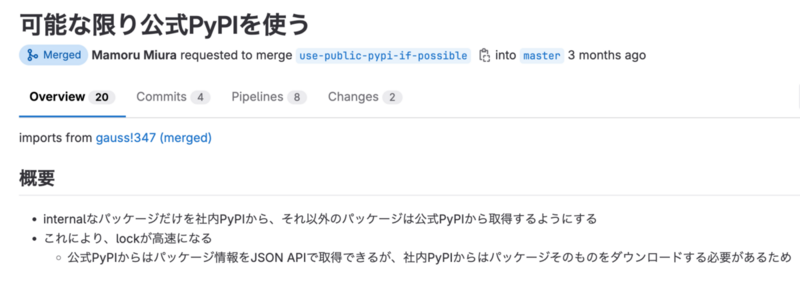
第3位 可能な限り公式PyPIを使う
- 紹介者: 須藤
- 実装者: 三浦
Pythonのパッケージ管理は、開発プロセスにおいて欠かせない要素です。AI・機械学習チームでは、Pythonのパッケージ管理にPoetryを利用していますが、lock(パッケージ間の依存関係の解決)に非常に時間がかかっていたことが問題でした。その原因の1つは、すべてのパッケージを社内のPyPIから取得していたことでした。公式のPyPIからパッケージを取得する際は、JSON APIを使ってパッケージ情報を取得できるのですが、社内のPyPIでは、パッケージ情報を取得するためにパッケージそのものをダウンロードする必要があるためです。この問題を解決するために、社内で利用するパッケージに関しては社内のPyPIから取得し、それ以外のパッケージについては公式のPyPIから取得するように変更しました。この変更により、lockの実行が劇的に高速化されました。AI・機械学習チームでは、ほぼすべてのプロジェクトでPythonが使用されているため、チームの生産性向上に大きく貢献しました。
第2位 社内ライブラリの負債を一気に解消
- 紹介者: 北川
- 実装者: 三浦, 農見, 横本, 謝, 高田, 池嶋, 北川
AI・機械学習チームでは特徴量を作成する部分を共通ライブラリ化しています。このライブラリも歴史が長く、Gitのログを見ると西場さんが2018年に作成したようです。 現在チームでは30前後のプロダクトを運用していますが、共通ライブラリの欠点として互換性をどこまで担保するかなど様々な問題があります。 例えば、このライブラリ作成当時はBigQueryのStorage APIが存在しないため、巨大なデータをロードする場合は一度GCSにデータをcsvを圧縮した状態で送り、そこからデータをダウンロードする必要がありました。csvは悪名高い通り、型がめちゃくちゃになることがあります。 このMRでは当時の取得方法からStorage API経由で取得するなど互換性を保つことが出来ない様々な変更を、痛みを一度で受け入れようとチーム一丸で行った変更になっており、おそらくチーム史上最も関係者が多かったMRになっていました。
実際どのように変更を本番に取り込んでいくかはかなり議論が行われ、影響はほとんど出さずにマージされました。 そして、チーム内ライブラリは初めてメジャーバージョンが1になりました!
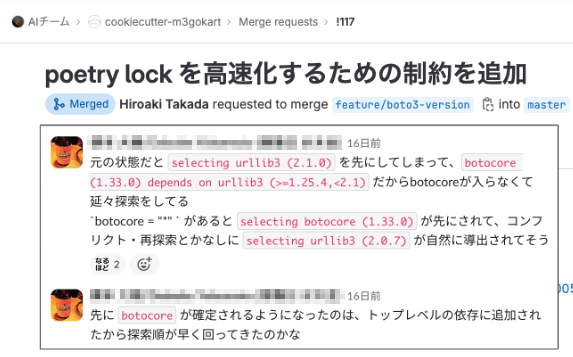
第1位 poetry lock を高速化するための制約を追加
- 紹介者: 三浦
- 実装者: 高田・農見
AI・機械学習チームではPythonのパッケージ管理にPoetryを利用していますが、管理するパッケージの量や組み合わせによってしばしばlock(パッケージ間の依存関係の解決)に時間がかかってしまうことが問題でした。ログを調査したところ、ある孫依存のパッケージについて許容できるバージョンの範囲がかなり狭いことが原因だと判明しました。さらに、同パッケージへの依存を明記すると探索順が入れ替わることを発見し、結果としてlockにかかる時間を大幅に短縮できました*1。チーム全員の待ち時間を減らし生産性を向上するという効果はもちろんのこと、仕組みの調査や解法はまさにソフトウェアエンジニアリング、MR提出者が病欠になるや他のメンバーが即座に巻き取るというチームワークと、三拍子揃ったMRということで多くの票を集めました。
まとめ: MLエンジンを高速リリースするための基礎開発とは
改めて顔ぶれを眺めてみます

このベストMRは全チームメンバーからの投票制なので、チームから多く感謝されたMRはどのようなものかと言うのがわかります。 とくに今回上位に来た改善は以下の2パターンに思います。
- サービスレベルを高めるもの(エラー監視[5]、SLA監視[11]、型[9])
- 開発者体験を高めるもの(lockの高速化[1,3]、共通ライブラリ[2,8])
AI・機械学習チームはエムスリーのサービスの中で使われるMLエンジンを開発することがミッションで、今年も20以上のプロダクトをリリースしてきました。 ですので、基盤づくりはそのための手段であり、基盤を作る事自体は担当者が居るのものではないです。 にも関わらずベストMRではむしろ監視や生産性に寄与するMRが中心となっていることは、いかにプロダクト開発の品質・速度のために基盤整備が重要だと皆が認識しているかを表しているかなと思います。
We are hiring!!!
エムスリーAI・機械学習チームでは「こんなMRはヌルい!俺こそが来年のベストMRを出すぜ!」というエンジニアを募集しています! 以下のURLからカジュアル面談お待ちしています!
*1:ここで興味深いのは、本来はこのパッケージに依存することを宣言する必要がない一方で、特にバージョンを制約しなくても(つまり package = "*" と書いても)十分に高速化できたことです