この記事はエムスリーAdvent Calendar 2022の23日目の記事です。 AI・機械学習チームの北川(@kitagry)です。
GitHubに慣れきった人 (過去の僕) にはMRとはなんぞやと言う感じだと思いますが、MRはMerge Requestの略称です。 GitHubでいうところのPR (Pull Request) にあたります。
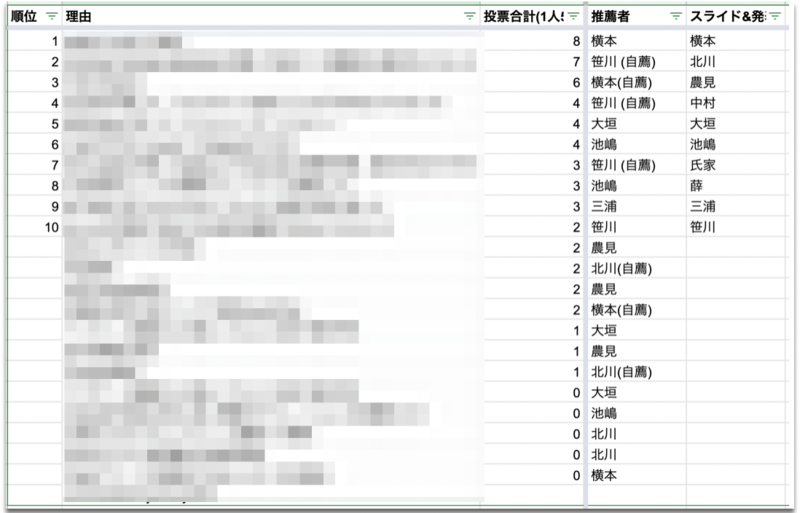
この記事ではAI・機械学習チームが毎年恒例で行なっているベストMRのトップ10について発表します。 このベストMRはチーム内でこれはよかったというMRをノミネートしていき、その中で決選投票をしてベスト10を決めました。
では、10位からご覧ください。
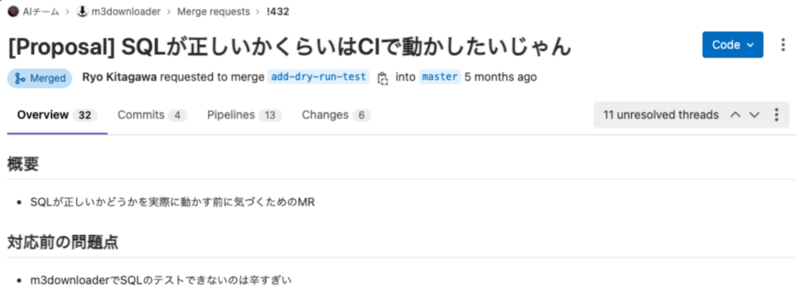
第10位 SQLの文法的な正しさをチェックするテストの導入
- 紹介者: 笹川
- 実装者: 北川
BigQueryから定型的なデータを取得するためのライブラリであるm3downloaderには、BigQueryがローカルで動作するemulatorを提供していないため、SQLの正当性をチェックする自動テストができない問題がありました。 一方、BigQueryにはdry-run の機能があり、実行すると課金されない状態で、SQLが正しいかどうかや、scan量などを知ることができます。 今回の変更では、このdry-runエンドポイントに注目し、downloader起動時に内部的にdry-runを呼ぶモードを実装し、実際のBigQueryへ発行してクエリの正しさを検証する自動テストを書けるようになりました。 また、CIで実際のBigQueryのAPIを呼ぶようになったため僅かにCIの実行時間が伸びたのですが、合わせて並列でテストを回す変更も実施したことで、その問題も解決しています。 チームのほとんど全てのプロダクトで利用されるライブラリの信頼性が大きく向上するとても重要な変更でした。
なお、本件については、bigquery-emulatorの登場と、それを利用するクライアントライブラリを作成してくれたインターン生の後藤さんの活躍で、ローカルでもテストが可能になりつつあります。
第9位 M1 Mac用の環境構築用のドキュメント

- 紹介者: 三浦
- 実装者: 農見
AI・機械学習チームでは全員がMacBookを利用していますが、Apple Silicon(いわゆるM1チップ)搭載モデルへの置き換えが進んでいます。Intel Macからの移行に苦労したメンバーが「M1Macで苦しむ人をこれ以上作ってはいけない」という意思のもと、環境構築の手順やハマりやすいポイントをドキュメントとしてまとめてくれました。このドキュメントのおかげで、開発機を乗り換えたメンバーやインターン生がスムーズに開発環境を整え、本質的な作業に集中できるようになりました。今年度からチームではドキュメンテーションの強化に挑戦し、繰り返し長く使えるノウハウやデザインドキュメントをGitLab上に集積し始めました。そのような背景からも、本MRは今年度のチームを象徴するMRのひとつと言えそうです。
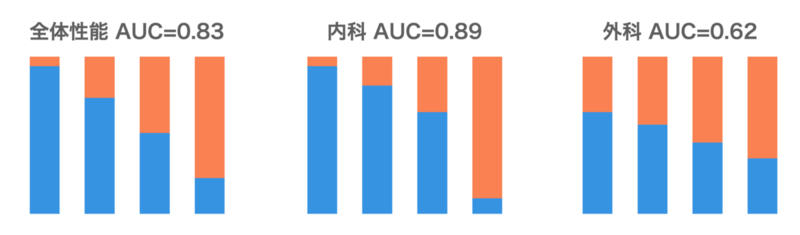
第8位 機械学習モデルの全性能グラフを表示
- 紹介者: 薛
- 実装者: 氏家
Yuleは、ユーザーの嗜好を推計する機械学習基盤システムです。 Yuleチームではメンバーが各自に作業し、チームで納品物の品質を担保していますが、プロジェクトごとで顧客の事情とニーズが異なるため、contextualな説明をレビュアーにしなければなりません。今まで必要情報の共有不足で何度も誤解や重複作業が発生していましたが、遂に、殆どの必要情報が詰まった評価用の基本の図ができました。 学習データの分布、その学習データでできたモデルの性能、そのモデルの予測で顧客に提供するデータの構成を全部一目で分かる上、学習群と推論群の乖離があるか、予測の結果は顧客に価値提供できるかの判断、問題に対する解決がどこにあるのかの議論も非常に円滑にできるようになりました。この標準化によって、モデルの品質レビューが低コストかつ漏れのないようになりました。
第7位 tfcmtの導入
- 紹介者: 氏家
- 実装者: 笹川
AI・機械学習チームでは基本的にTerraformでインフラを管理しています。TerraformのplanやapplyはCI上で行っていますが、Terraformのplanの結果をわざわざCIのログまで見に行かなければならず、Terraform planの内容も可読性が高いわけではないという問題がありました。 そこで、Terraformのplanやapplyの内容をGitHubのコメントとして通知し、リソースの変更内容によってラベルを付与してくれるtfcmtを導入してくれました。また弊社はGitLabを使用しているため、GitLab対応を行ったtfcmt-gitlabをOSSとして公開しています。 これにより、リソース変更を簡単に確認できるだけでなく、リソースの削除やwarningなども視覚的に強調されるようになり、Terraform周りの開発体験が大きく向上しています!
第6位 アドホックなバッチを整理してデプロイの自動化

- 紹介者: 池嶋
- 実装者: 福林
AIチームではユーザーの嗜好を推計する機械学習モデルYuleを開発しています。 Yuleの詳細説明は以下のスライドが詳しいです: https://speakerdeck.com/mski_iksm/gao-su-hua-bing-lie-hua-biao-zhun-hua-de-sukerusurumlyu-ce-sisutemufalsekai-fa
YuleはKubernetes上で学習・推論を行うのですが、企画や他チームからの依頼に合わせてモデルを作るため毎回設定が大きく異なっていました。柔軟な対応を可能にするため、JobのデプロイはローカルのPCから直接kubectl applyで実施していました。 使用データの都合上、本番環境で実行されていたのですが、これだと各開発メンバーに過剰な権限を与えなくてはならず、セキュリティ上の課題になっていました。
このMRではデプロイをGItLab CIから行えるようにしたものです。 GitLabのlabコマンドを使って、学習に必要な設定をパラメータとしてCIに渡すことで、手元から直接本番環境にデプロイすることがなくなりました。 また、「アドホックだから〜」とか「いろんな種類のJobがあるから〜」とか言って放置されてきたデプロイスクリプトをリファクタし、シンプルにもなりました!
第5位 PythonライブラリのMonorepo化
- 紹介者: 大垣
- 実装者: 横本
開発を高速にするために、社内共通ライブラリとして、m3mushroom(gokart Task集)とm3downloader(BQ等のデータのETLライブラリ) という2つのPythonのライブラリを作っており、各PJ -> m3mushroom -> m3downloader -> BQのtableという依存があるのですが、新しいデータを使う際に2つのライブラリのリリースをする必要があり、MRとレビューが分散して見にくいという問題がありました。 このMRでは、ライブラリ同士のリリースの独立性は保ったまま(2つのライブラリのまま)、単一のレポジトリで開発するように変更しました。難しい点としては、gitlab-CIによる継続的リリースフローをとっているのですが、依存のあるライブラリをなるべく複雑じゃなくリリースする仕組みでした(リリースフローの中で依存書き換えが必要)。 結果として、Monorepoにしてもライブラリの独立性は失われず、リリースフローもなんとか複雑になりすぎず、開発者体験が大きく向上しました。
第4位 bqvalidの導入によるフルスキャンの防止
- 紹介者: 中村
- 実装者: 笹川
こちらはAIチームの笹川がGoogle standard SQL用のLinterを作成してチームに初めて導入したMRです。元々の問題として、定数式ではない条件を含む _TABLE_SUFFIX のフィルタではスキャンされるテーブルの数は制限されないというBQの仕様のため、意図せず大量のスキャンを行ってしまいBigQueryの料金が跳ね上がってしまう可能性がありました。そこで、そのようなフルスキャンをSQLから事前に検知するようにLinterを作成しました。これによりやってしまいがちなSQL上のミスをCIの段階で防げるようになりました。
bqvalidはOSSで公開しているので是非使ってみてください。 github.com
第3位 Code Searchの導入によりリポジトリ横断検索が可能に
![]()
- 紹介者: 農見
- 実装者: 横本
AI・機械学習チームではバージョン管理システムとしてGitLabを使用しています。しかしながら、フリーバージョンのGitLabではレポジトリ内でのコード検索機能しかなく、過去に書かれたコードを見つけるのが困難でした。そこでCloud Source RepositoriesにGitLabのコードを連携しました。これにより全レポジトリ横断検索が出来るようになり、コードの再利用が進みコーディング時間短縮に繋がりました。あまりに便利だったので全社的にも導入しました。
第2位 Workload Identity Federationの導入
- 紹介者: 北川
- 実装者: 笹川
今までAI・機械学習チームではCI/CDを通して、デプロイやIaCなど行なってきていました。そのため、CIで動かすサービスアカウントにはかなり強い権限をつけていました。しかし、サービスアカウントを利用するに当たってはJSONキーによる認証を行なっており、悪意のある人がコードの書き換えを行って秘密情報を抜き出すことも可能ではありました(もちろん社内の人間にしか触ることは出来ませんが)。このMRではそのセキュリティの懸念を払拭するためにWorkload Identity Federation(以降WIF)を利用し、GitLab Runnerからのみサービスアカウントの利用ができるような変更を行いました。また、各リポジトリに散らばっているDeployについてもWIFを用いてリリースするようにするために、GitLabのテンプレートを用意して簡単に移行できました。
こちらについてはブログにもなっているので是非読んでみてください。
第1位 GitLab CIテンプレート用リポジトリの作成
- 紹介者: 横本
- 実装者: 中村
CI/CDの定義時にincludeして使える共通YAML集レポジトリの発足が2022年でもっとも多くの投票を獲得しました。(CIのメンテナンスはみんな辛い思いをしていたのが伺えます) AI・機械学習チームでは各所に提供しているレコメンデーションや検索などの機能ごとにプロジェクトを分けてGitLabレポジトリも個別に管理しており、アクティブなレポジトリだけでも数十個に登ります。それらのCI/CDの定義を.gitlab-ci.ymlに記述しているのですが、そこにはプロジェクトによらずお決まりの定形処理が各所に個別に書いてある状況でした。
そこで .gitlab-ci.ymlにはGitLabレポジトリをまたいで別の場所のymlをincludeする機能があることに着目し、その機能を活用するための定形処理集としてこのレポジトリが生まれました。
現在は「GKEデプロイ」「CI完了のSlack通知」「パッケージの publish」「脆弱性チェック」など各種の共通処理がスニペットとしてコミットされ、継続して追加されています。
DRYを避けてこのレポジトリからincludeすることで、
- コピペしたけどうまく動作せずCIを繰り返しデバッグする辛い時間
- より良いチームベストプラクティスに追随できておらず古い書き方のままのレポジトリ
などをなくすことができました。 例えば、2位のWorkload Identity Federationの導入の際は「GKEデプロイスニペット」を修正しただけで、includeしている各レポジトリでは認証方法の変化を意識せず導入することができています。
過去にこれに関する記事も書いているので是非読んでみてください。
まとめ
ということで今年の第一位は中村さん(po3rin)でした! また、最多ベスト10入りは笹川さんで3回でした! また、他のチームメンバーも素晴らしいMRを出してくれました。
このような取り組みはチーム内のモチベーションにもなってとても良いと思います。 他の会社のベストMRのブログもお待ちしています。 是非読みたいです!
We are hiring!!!
弊社では俺こそが来年のベストMRを出すぜ!というエンジニアを募集しています! 以下のURLからカジュアル面談お待ちしています!