初めまして、2024年3月後半にエムスリーのAI・機械学習チームで10日間インターンに参加させていただいた東(@azuma_alvin)です。
もしタイトルが何かに似ていると感じた方がいれば、只者ではないと思われます。

この記事では、KubernetesのCronJobでOOM(Out Of Memory)が発生した時に「いい感じ」にメモリ制限を増加させてくれるbroomの開発経緯とその実装についてお話しします。
また、インターン期間で感じたエムスリーという「ギーク集団」の中で開発する楽しさについてもお伝えできればと思います。
2週間でゼロ(nil)から開発したbroomは、OSSとしてGitHubで公開しているのでコントリビュートお待ちしております!
CronJobのOOMとは
そもそもCronJobとは、マニフェストで指定されたスケジュールに基づいてJobを定期的に実行するリソースです。そのJobはさらにPodを作成するため、CronJobをオーナーとするPodがOOM(Out Of Memory)によって異常終了してしまうことを本記事では「CronJobのOOM」と呼びます。
私がJoinしたAI・機械学習チームでは大量(250以上!)のCronJobを使用してバッチ処理を行っています。驚くべきことに、その運用・保守は10名程度のチームメンバーが開発業務と並行で行っていました。
一般的なCronJobでもOOMは発生しますが、特にAI・機械学習チームで扱うようなMLバッチはモデルサイズが大きく、データの増加によって容易にOOMが発生してしまいます。
CronJobのOOMは完璧に防げるか
CronJobのOOMを防ぐための解決策として最初に思い付くのは2通りの方法です。
まず1つ目は、最初からメモリ制限を大きい値に設定する方法です。設定次第ではOOMが発生しなくなりますが、Podに無駄なメモリが割り当てられる可能性が高くノード課金額が増加してしまいます。
2つ目は、OOMの兆候が出てからメモリ制限を緩和する方法です。こちらは無駄な課金を抑えることができますが、エンジニアの対応が遅れるとバッチ処理の失敗によってユーザー体験を損なってしまいます。また、障害対応のコストも高くなってしまいます。
私が調べた限りでは、この課題を解決する完璧な方法は見つかりませんでした。 例えばKubernetesのDeploymentであれば、Vertical Pod AutoscalerがCPU・メモリ使用量に基づいてリソース制限・リクエストを自動的にスケールしてくれます。似たような「いい感じ」のスケールをCronJobでも実現するため、KubernetesのCustom Controllerとしてbroom*1を開発しました。
broomのアイデアと実装
broomの役割である、
- コストを削減するためにメモリ制限を動的に変更すること
- 変更されたバッチの再実行によって障害対応を減らすこと
の2つをKubernetesのCustom Controllerに落とし込んで実装します。
一般的にCustom Controller内では、Reconciliation Loopと呼ばれる、あるべき状態と実際の状態の差分を埋める処理が実行されます。
ここでは、broomがどのようなReconcile処理を行っているかを簡単に紹介します。
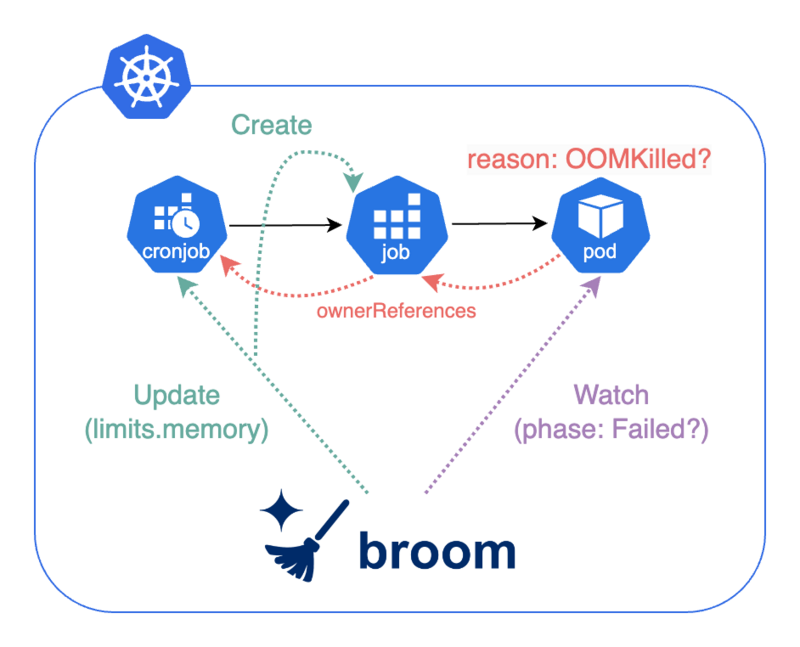
Reconciliation LoopはPodのphase: Failedイベントを起因に実行されます*2。
reason: OOMKilledで異常終了したPodが特定されると、PodからJob、JobからCronJobへとownerReferencesを辿ります。その後、CronJobのスペック定義のメモリ制限(spec.jobTemplate.spec.containers[].resources.limits.memory)を増加させて更新します。
さらにオプションとして、broomは失敗したJobを更新後のメモリ制限で再び実行できます。一般的にML系のバッチは中間結果をキャッシュしておくので、再実行時にはOOMが起きた場所から処理を再開できることが多いです。
最後に、Slackに次のような通知を送信します。
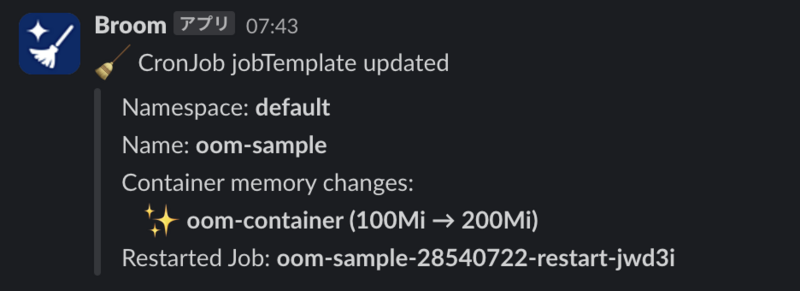
Custom Controllerは、Broom Custom Resourceによってユーザーが詳細に設定できるようになっています。
apiVersion: ai.m3.com/v1alpha1 kind: Broom metadata: name: broom-sample spec: target: name: oom-sample labels: m3.com/use-broom: "true" namespace: broom adjustment: type: Mul value: "2" restartPolicy: "OnOOM" slackWebhook: secret: namespace: default name: broom key: SLACK_WEBHOOK_URL channel: "#alert"
broomでは、Name、Namespace、Labelsによって柔軟な条件でCronJobをターゲットに指定できます。
また、メモリの増やし方については足し算Add(e.g., +20Mi)と掛け算Mul(e.g., ×2)の2種類から選択可能です。
その他の設定項目についてはGitHubのREADMEをご覧ください。
未実装の課題
broomはOSSとしてGitHubに公開されていますが、改善すべき点はまだまだ見つかっています。
そのうちのいくつかをピックアップして紹介すると、
- 際限なくメモリが増加するのを防ぐためのメモリ制限の上限を指定
- nodeSelectorを指定している場合に、メモリ制限の増加に合わせてnodeSelectorを変更可能に
- 更なるコスト削減を目的とした、過去のOOM回数やメモリ使用量に基づいたスケールアップ/ダウン
- 複数の
BroomCustom Resourceによる、CronJobスペック更新の競合解決
などが挙げられます。 これらは引き続きbroomの開発を継続していく中でIssue化して解決したいと考えています。
また、皆さまのコントリビュートもお待ちしております!
インターンを振り返って
10日間という短い期間でしたが、学びと刺激が多く楽しいインターンでした。
私が実際にどのようなスケジュールで、どのようにタスクを進めたかを簡単に紹介します。
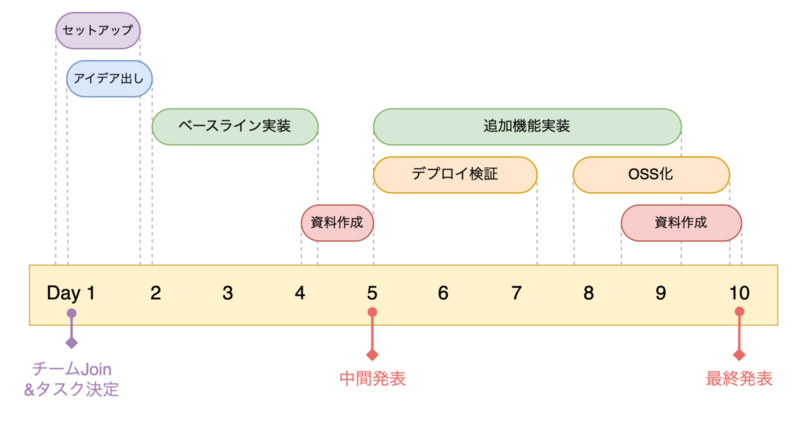
取り組むタスクはインターン初日に決定しました。AI・機械学習チームのインターンでは、タスクの候補がたくさん用意されていて、興味関心の強いタスクに積極的に取り組むことができます。私は以前からKubernetesに興味があったので、メンターさんと相談して本記事のタスクを選ぶことができました。
とはいえ私は有力な解決策であるKubernetesのCustom Controllerについて微塵も知らなかったので、少し背伸びをしたつもりで開発をスタートさせました。実際に与えられたのは「バッチがよくOOMを起こす」という課題感のみで、具体的な実装方針はメンターさんに壁打ちをしていただく中で徐々に固めていきました。また、最初に「10日間でOSS化までできたら最高だね」という話もあったので、最終的に目標を達成できて嬉しかったです。
この成果は、エムスリーというギークな集団に囲まれていたからこそ得られたものだと思います。 エンジニアの皆さんの技術力の高さ、そして課題に向き合う姿勢にたくさん刺激を受けた10日間でした。
アイデアの壁打ちから実装のアドバイス、コードレビューまで圧倒的安心感でサポートしてくださったWメンターの横本さん(@yokomotod)・北川さん(@kitagry)、それからAI・機械学習チームの皆さんには本当に感謝しています。ありがとうございました。
おわりに
CronJobでOOM発生時に「いい感じ」にメモリ制限を増加させるbroomの実装と、インターンに参加した感想についてお話ししました。
この記事を読んで少しでも興味を持ってくださった学生の方は、ぜひインターンに応募してみてください!
MLOpsインターンはもちろん、間違いなく他の職種でもエムスリーのギークでスマートな文化を体感できると思います。
インターン応募はこちら!
エンジニア採用情報はこちら!
*1:broomには「箒(ほうき)」という意味がありますが、Batch Resolve OOMの頭文字でもあります。
*2:CronJobのイベントを監視しなかったのは、status: Failedフィールドを持つSawCompletedJobイベントがあるタイミングから発行されなくなるためです。EventCorrelateメソッドによってイベントのアグリゲーションとスパムフィルタリングが行われています。