【デジカルチーム ブログリレー 2 日目】
クラウド型電子カルテデジカルチームの井上 (@wtr_in) です。
言いたいことはタイトルでほぼ言い切ってしまいましたが、先日 BigQuery 上のデータをうっかり消してしまいそうになる事件がありました。原因はテーブルコピーに関する細かい仕様の勘違いだったのですが、もしかすると今後同じようにハマる人もいるかもしれないので、せっかくなので書き残しておきます。
続きを読む【デジカルチーム ブログリレー1日目】エムスリーエンジニアリンググループ、デジカルチームの安江です。Scalaとマミさんが好きです。
双子が生まれ、1年間の育休を取りました。育休中に新しいチャレンジについて打診があり、自分でも希望してデジカルチームへ異動。この春に復帰したのですが、想像以上のギャップが待っていました。
この記事では「1年間のブランクからどう復帰したか」にテーマを絞って書きます。これから育休を考えている方、長期の離脱からの復帰に不安を感じている方の参考になれば幸いです。
【マルチデバイスチーム ブログリレー6日目】
エンジニアリンググループ マルチデバイスチームの藤原です。
私たちのチームでは10近いiOSアプリを開発しています。各アプリには専任の開発者がおり、プロビジョニングプロファイルは fastlane match を使ってGitリポジトリで管理しています。
しかし、アプリごとに fastlane match の運用環境が独立していたため、テストデバイスの追加や証明書更新のたびに各担当者へ作業を依頼する必要がありました。さらに、スクリプトの配置や実行手順がアプリ間で微妙に異なることから、担当者以外が対応するには認知負荷が高いという課題を抱えていました。
本記事では、既存の fastlane match の仕組みを活かしつつ、トイル(手作業の繰り返し)となっていたデバイス追加運用を「誰でも簡単に対応できる」体制へと改善したプロセスをご紹介します。
【マルチデバイスチーム ブログリレー5日目】
マルチデバイスチームの小林(@bakobox)です。
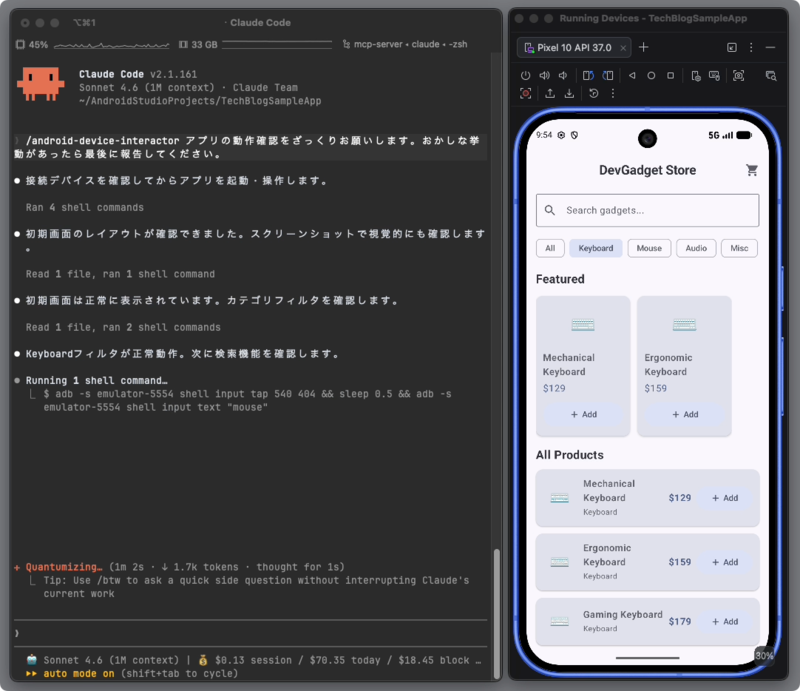
2026年4月に Android CLI が公開されました。プロジェクトの作成から実機デバイス / エミュレータの操作までを行える CLI で、AI エージェントによるアプリ開発の操作を容易にすることを目的に開発されています。
この Android CLI と、昔からある ADB コマンドの使い方を AI エージェントに教えるだけで、公式ツールのみで Android 実機 / エミュレータを操作できます。
本記事では、Android CLI と ADB を使って Android 実機 / エミュレータを操作するエージェントスキルを、実際のコマンドとあわせて紹介します。
【マルチデバイスチーム ブログリレー4日目】
こんにちは、マルチデバイスチームでモバイルアプリエンジニアをやっている八箇です。
2025年9月にエムスリーに転職して9ヶ月が経ちました。開発環境や文化の違いにもようやく慣れてきたところです。 昨年(2025年)はモバイルアプリの開発業務以外にも、iOSDC, DroidKaigi, FlutterKaigi, およびKotlin Festの4つのカンファレンスで弊社ブースのお手伝いをさせていただきました。

入社直後だったためサポートを受けながらではありましたが、入社前の客観的な視点と、入社後実際に目にしたチームの様子、その両方を交えて社外の方にエムスリーのアプリ開発についてお話しできたのは、非常に良い経験になりました。 その際に、社外の方々とお話しする中で、多くの方がエムスリーに対して入社前の私と同じイメージを持っていると感じました。
本記事では、私が入社前に抱いていた不安と実際、そして入社してから気がついたエムスリーで働く上での魅力についてまとめています。 エムスリーに興味を持っている方の参考になれば幸いです。
続きを読む【マルチデバイスチーム ブログリレー3日目】
エンジニアリンググループ マルチデバイスチーム(iOS/Androidアプリの開発を担当)の渡辺です。
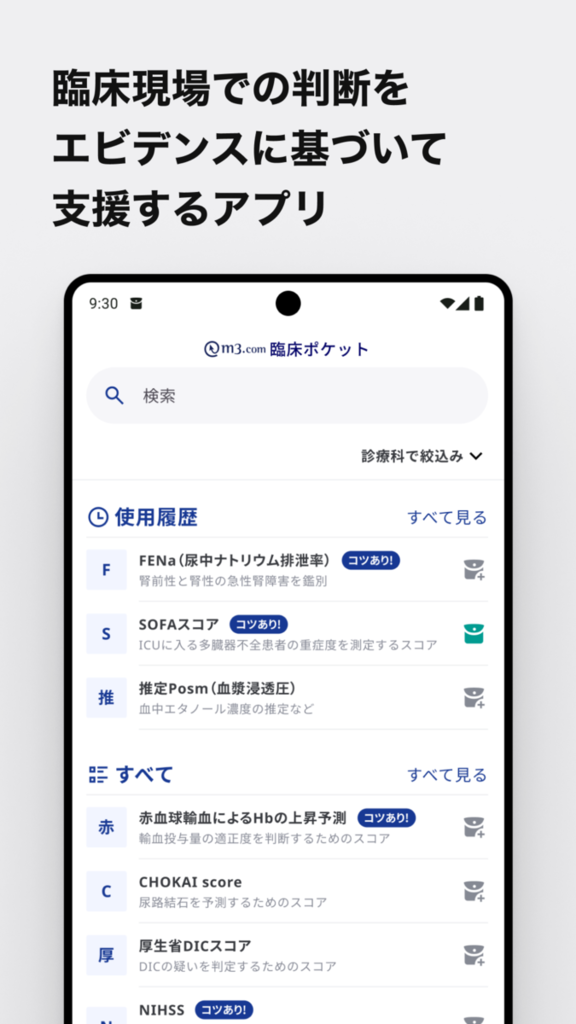
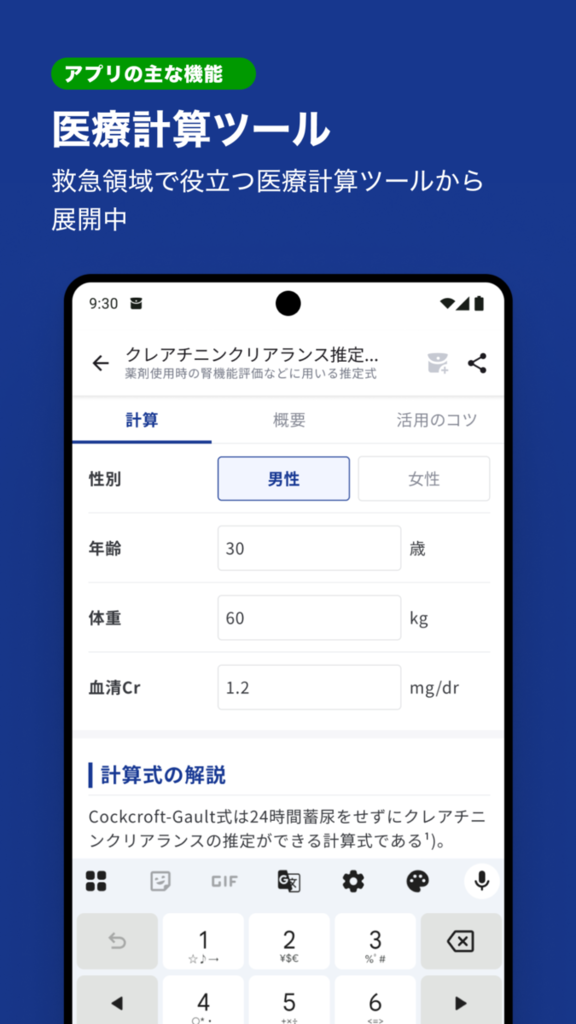
マルチデバイスチームで開発している「臨床ポケット」アプリは、医師が臨床現場で行う判断をエビデンスに基づいて支援するアプリです。 実際の医療現場ではスマホの通信状況が芳しくないことも多く、インターネットに接続できる前提だといざというときに利用ができない場合があります。 臨床ポケットではあらかじめ必要なデータをアプリにバンドルしておくことで、オフラインでの利用を可能にしました。
iOSアプリの開発時は何も問題なくアプリをリリースできましたが、AndroidアプリはGoogle Play ConsoleでApp Bundleのアップロード時にエラーが出ました。
この記事では、ファイルサイズの大きなAndroidアプリを配信するために実施した対応を紹介します。

【マルチデバイスチーム ブログリレー2日目】 エンジニアリンググループ マルチデバイスチームの田根です。

私は主に IntelliJ IDEA を使って開発しているので、AIエージェントは JetBrains Junie をメインで使っています。 Claude Code も IntelliJ IDEA のプラグイン Claude Code [Beta] - IntelliJ IDEs Plugin | Marketplace があり、IntelliJ IDEA 上で動かせます。 今回は、この両者を実際の開発プロジェクトでガッツリ使い倒して分かった「リアルな違い」を、率直に比較レビューします。 Junieの自律思考とClaude Codeの馬力、どちらがどんな場面で活きるのか? 使い分けのヒントをお届けします。
※本記事では、Junieは最も安価な Gemini 3 Flash Previewモデル、Claude Codeは最新モデルを使用して比較しています。
続きを読む