こんにちは。エンジニアリンググループゼネラルマネジャー & 機械学習エンジニアの大垣です。
さて、私が機械学習エンジニアとして仕事をしているAI・機械学習チームでは、今年一年で28個のプロダクトをリリースしました。月に2つくらいは新規プロダクトが出てる計算ですね。なかなか高速にリリースできているのではないでしょうか。 なお、この1年で5名のメンバーが新規に加わり、チームが12人から17人になったので、来年は更に加速していきたいです!*1
これらのプロダクトを簡単にお見せしつつ、エムスリーという医療xWebの企業でMLのチームはどういう仕事をしているのか、というのをお届けできればと思います!

年間15個以上のプロダクトをリリースするAIチームを入社したてのフレッシュな目線で紹介する - エムスリーテックブログ
- 2024年に立ち上げられたAI・機械学習プロジェクト一覧
- レコメンド
- ユーザー向けアプリケーション
- 情報提供のオートメーション
- 臨床AI
- 他のMLプロダクトに提供するための内部エンジンプロダクト
- MLインフラ
- We are hiring !!
2024年に立ち上げられたAI・機械学習プロジェクト一覧
AIチームでは、テーマに沿ったA~Zの名前をプロダクトにつけており、2024年は、2024年1月に作られた川の名前シリーズ後半のV(Volga、コンテンツにLLMで識別的タグ付け)から始まり、酒の名前シリーズもほぼ一周周り、V(Vermouth、動画の書き起こしとチャプター生成)が2024年12月に最後にリリースされました。 酒の名前シリーズでA-Zが4週目なので、AI・機械学習チーム発足以来で言うと、ざっくりいまは100個程度のプロダクトがあることになります。
数だけ話してもどうしようもないので、AI・機械学習チームで2024年に立ち上げられたプロダクトの名前と一言まとめを大公開します!
| Volga タグ付け |
Wulik 画像変換 |
Xingu 協調フィルタリング |
Yodogawa アンケート項目の構造化 |
| Zambezi 画像生成 |
Asti 外部広告支援 |
Brandy ユーザー活動の可視化 |
Chita 時系列成長テーブルデータ |
| Dunkel 疾患時系列予測モデル |
Eiswein カルテの構造化 |
Fizz マーケティングデータ連携 |
Gin 前日行動によるレコメンド |
| Hoegaarden データ中心PWAスマホアプリ |
Iichiko オンラインレコメンド |
Jura 名寄せ |
Kir クロスサービスレコメンド1 |
| Lazzaroni プロダクト名カルタ |
Mojito ステップ配信 |
No.6 皮膚疾患の診断AI |
Orion PVデータのモデリングエンジン |
| Pisco モデル出力提供ミドルウェア |
Queen プッシュ通知レコメンド |
Rum 求人レコメンド |
Sauvignon クロスサービスレコメンド2 |
| Tokaji 求人レコメンド2 |
Underberg クロスサービスレコメンド3 |
Vermouth 動画の書き起こし・構造化 |
Whiskey 記事中の病院のタグ付け |
具体的なサービスはあかせないのでレコメンド1,2...みたいになってしまっているものもありますが、雰囲気掴んでいただけたのではないでしょうか。
この後の章では、更に分野ごとにざっくりどういうことやってるかの紹介をします。
レコメンド
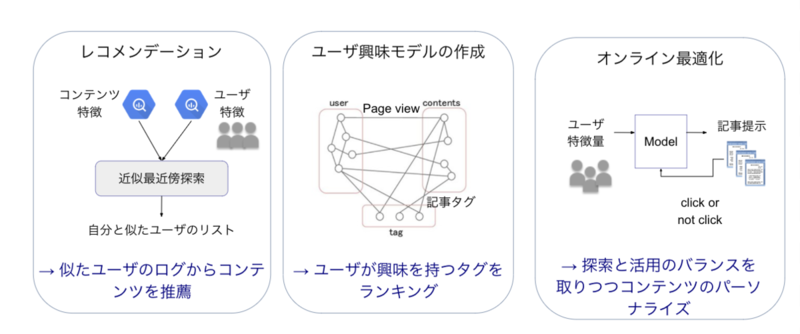
2024年の開発リストを見てもわかると思いますが、やはりwebサービスの会社でMLチームが最も力を発揮する分野の一つはレコメンデーションです。
コンテンツの回遊
例えば医師コミュニティ内のコンテンツだったりで、次から次へといろんな投稿を読みたい、みたいなサービスがあります。それらのサービスでは記事ごとに、次はこの記事がオススメなので読んでみて下さい、という形で、サービス内の回遊を促すレコメンドがユーザー体験に協力に効きます。論文のようなストック型のコンテンツでは協調フィルタリングベースだったり、ニュースのようなフロー型のコンテンツではオンライン学習ベースだったり、一口に回遊レコメンドと言ってもコンテンツの質ごとにモデルは多岐にわたります。
求人の最適化
エムスリーのサイトの中には、医師、薬剤師、医療従事者の皆様のための求人情報を提供しているサービスがあります。 現在の居住地から無理なく通える範囲で自分にあった求人があるか、というのは非常に重要なパーソナライズですので、もちろんエムスリーではこの求人パーソナライズを開発しています。
クロスサービス
エムスリーのような複数サービスを持つ会社にとって、あるサービスは使ってるけど、他のサービスはそこまでではない、というユーザーの方は、まだ気づいてもらっていない良さがある、という意味でもったいないわけです。このサービスでこういう行動をしている人にはこっちのサービスも刺さるんじゃないか?などの観測を通して、ユーザーの皆様が気づいていないサービスへの動線を提供するのもレコメンドの一つです。
内部広告枠
内部で広告ってどういうこと?と感じるかもしれませんが、これは前項のクロスサービスをより抽象化した枠となります。 例えば、論文を読みに来た先生に薬剤の情報を提供したり、という形です。 ここを広告枠と考えている理由は、広告の仕組みと同様に、各サービスが枠を提供して、そこにユーザーごとに最適なコンテンツを、具体的にはCTR/CVRを予測して抽選し、出す仕組みにしているからです。
その特性上エムスリーのレコメンド領域でもかなり自由度が高い、かつ、コンテクストを活かしたレコメンドが期待される領域で、正直まだまだやりきれてないんですが、特に今年は、深いコンバージョン(クリックだけじゃなくその後コンテンツをしっかり見る)、レコメンド自体のパフォーマンスが落ちないように候補を早めに足切りする、等のサブアルゴリズムを追加しました。
ユーザー向けアプリケーション
AI・機械学習チームでは、実はフロントエンドも含めたアプリケーションも作成しています。データ・機械学習をもとにエムスリーのすべてを向上させるのがミッションなので、ないサービスは自分で作る、というのもミッションに含まれるわけです。
EBHS
健康診断の結果って漫然と観てしまうことありますよね。エムスリーでは健康診断の結果をもとに、健康寿命にどれくらい影響を及ぼすのか、どう改善したらいいのか、というのを個人レベル・企業レベルで提供するEBHSというサービスを運営しています。このサービスの中の予測モデルはもちろん、データ連携・認証・フロントエンドもふくめてまるっとAI・機械学習チームのエンジニアが開発しています。
製薬業界の方向けPWAアプリケーション
疾患のデータや、多様なコンテンツのクロスレコメンドを扱うAI・機械学習チームとして、実はそれらのデータを活かした、スマホでアクセスするためのPWAアプリケーションも開発したりしています。 いま最も重要な疾患やニュースの情報をプッシュ通知で届けたりなど、スマホの体験を最大に活かして業界内の活動を支援しています。 もちろんデザイングループや他チームのプロダクトマネージャーと協力してUIの磨き込みも行います。
情報提供のオートメーション
レコメンドのようなブラックボックス寄りな最適化も良いのですが、"こういう人にこういうタイミングでこんな情報届けられれば喜んでもらえるのにな"という具体的な課題を、施策開発者と協力して実現していくのもデータ・MLの重要な役割です。
時系列での興味モデリング
ユーザーの皆様にとって、最も興味が高いタイミングで面白い記事が配信されてほしいわけです。この、興味というのは連続的に変化するものなので、誰が・何に興味があるだけではなく、いつ、興味があるかのモデリングも非常に重要な分野です。
自動配信
モデリングできるだけでは不足なのでさらにそこから、適切な人に適切に情報を届ける、というシステム化もMLチームで取り組んでいます。
外部広告
エムスリーでも、他媒体の外部広告は利用することがあります。その際に、うるさい広告にならないように、刺さりそうな人に刺さりそうな内容だけを出したい。 そのためには、社内でターゲティングのレコメンドエンジンを動かしたり、最適な文言を生成したり、動かしたレコメンドエンジンを元に入稿したりと割と様々な最適化をする必要があります。
ダッシュボード
上記プロダクトたち、例えば自動配信を試作開発メンバーに提供した後に、実際それがユーザーにとって良かったものになってるか。もっと伸ばせるところはないか、という可視化があってこそ施策を磨けるわけです。AIによる出力と施策が噛み合っているか、などをダッシュボードを通じて把握できるようにするのももちろん仕事の一環になります。
一方で、ダッシュボードの乱造は、それはそれで仕事のための仕事になるので気をつけています。シンプルな仕組みでダッシュボードを作れるようにしたり、slack通知で完結する部分はslackに閉じる、インタフェースがスプレッドシートで十分なものはスプレッドシートからのBigquery連携とする、など、ダッシュボードを目的としない仕事の仕方をしています。
臨床AI
医療の分野でMLというと、画像診断などはイメージ湧きやすいかもしれません。エムスリーのMLチームでも臨床現場で使われるAIの開発に取り組んでいます。
線維化ILDの早期診断のためのBMAXがリリースされました
PAHの診断の研究がリリースれました
その他まだ開発中のもの
ウェアラブルデバイス、病理画像、もちろん胸部その他X線・CTなど様々なモダリティのモデルを作成しています
他のMLプロダクトに提供するための内部エンジンプロダクト
LLMによる記事の構造化
AI・機械学習チームでのLLMのもっとも重要な利用は、既存の資産を(オンデマンドで)構造化する部分となります。 例えば、血液のがんについて情報が必要なユーザーが居るときに、そもそもどの記事が血液のがんに関連するものであるかがわかってないとレコメンドの精度も落ちるわけですよね。
もちろん基本的にはこういう構造化も専用モデルを作ればいいわけですが、LLMで構造化することによって、より特化した施策を短期間で立ち上げられることが非常に便利です。
動画データの文字起こし・構造化
もちろん構造化はテキストの記事だけではありません。動画・画像・医用画像・健康診断データ・その他医療データなど、記事以外にも構造化することで利用価値が開けるデータは非常に多くあります。直近のプロダクトでは、動画を元に、文字起こししつつ構造化する、というのをインターンの2週間でリリースしました。
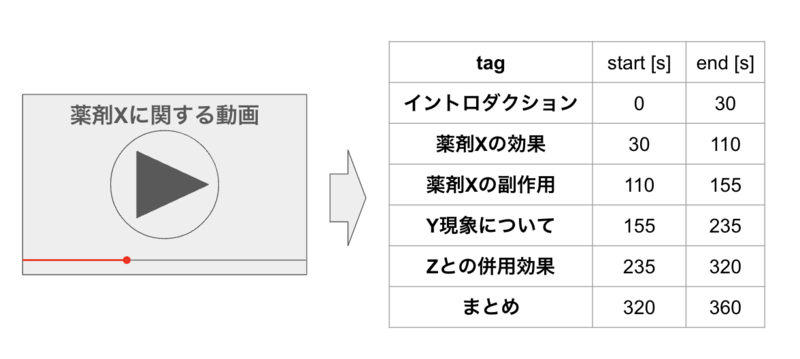
インターンではじめてのプロダクト開発を経験した話【ソフトウェアエンジニアインターン参戦記】 - エムスリーテックブログ
文章をいい感じの場所で区切る
ここまで紹介したわかりやすいもの以外に、ちょっと面白いプロダクトを紹介すると、ある長い文章を、適切な改行をして、例えば三行でまとめる。 というものも1プロダクトとして動いていたりします。 なんでこれがほしいかと言うと、外部・内部の広告だったり、メールマガジンだったりでコンテンツを紹介するときに、どうしても紹介文が複数行に鳴ってしまうわけですが、その時の見栄えはユーザーの理解に非常に影響が強いからです。 このように、汎用的であるがゆえに突き詰めると非常に重要な問題になるプロダクト、というのも内部連携ではよくあります。
MLインフラ
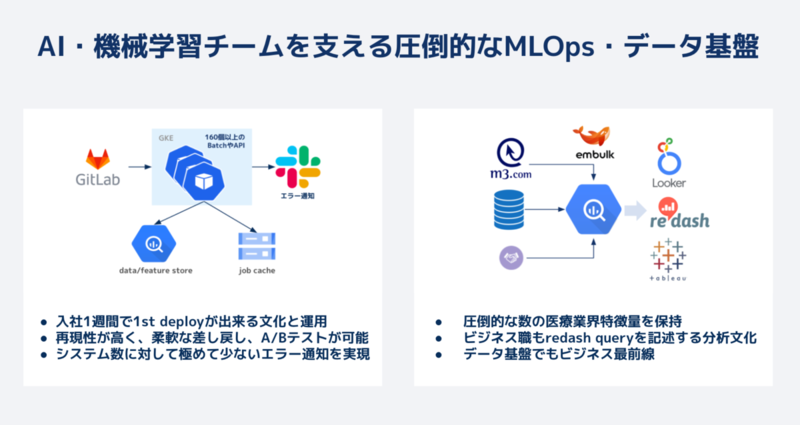
27のプロダクト名にはなってないけど、チームの開発速度が向上するための施策もめちゃめちゃやってます。
特に面白いところは、インフラ担当がいるとかではなく、MLエンジニア・ソフトウェアエンジニア・MLOpsエンジニアが各自自分の気になるところをガンガン快適にしていった結果インフラが整っているところです。
内製機械学習パイプラインgokartに強力な型サポートを導入する
チーム内linter
We are hiring !!
エムスリー AI・機械学習チーム紹介資料 / Introduction of M3 AI Team - Speaker Deck
エムスリーでは、MLを専門としているチームでありつつも、"なんでもやって成果を出す"を楽しめるエンジニアを募集しています。
当該チームでのMLエンジニア・ソフトウェアエンジニア・MLOpsエンジニアを始めとし、その他多様なチームでの働き方に興味がありましたらぜひカジュアル面談ご応募下さい!
エンジニア採用ページはこちら
カジュアル面談もお気軽にどうぞ
インターンも常時募集しています
*1: プロダクトカルタのブログにあるように、今年はじめ時点では年間15くらいだったので、今年も開発速度が1.5倍以上になってます