こんにちは、エンジニアリンググループデータ基盤チームの木田です。先日公開されたCTO兼VPoP山崎の記事にある通りゼネラルマネージャーを拝命しまして、データ活用の観点だけではなくそれ以外の側面でも組織全体を支える立場となりました。クリスマスが過ぎ、すっかり街は年末モードになりましたね。毎年この変わり身の速さに驚くとともに、新年の足音を感じる時期でもあります。

エムスリーのデータ基盤利用者は今年も順調に増えまして、システム (サービスアカウント)も含めると倍々で増加しております。それに呼応する形でBigQuery上のクエリやユースケースの多様性 (そして料金も) 増しております。データ基盤の開発・運用を手がけるデータ基盤チームでは、今年の活動としてdbtやdataformの利用拡大によるデータパイプラインの品質強化や、クライアント企業へのタイムリーなレポーティングニーズに対応するためDatastream による基幹データベースからのニアリアルタイムデータ連携を始めました。Datastreamの導入・運用を夏頃から始めて約半年が経ち、本記事では導入時の検討事項やその後の運用について振り返ります。
CDCとは
CDC(Change Data Capture)はデータソース (主にOracleやPostgreSQLなどのリレーショナルデータベース)からの変更イベントを検知し、それらの変更をリアルタイムでキャプチャして他のシステムとのデータ連携を可能にする技術です。動作原理としてはRDBのトランザクションログを監視し、変更イベントを検知、宛先のデータベースに同期する方式が多いです。
CDCを実現するクラウドサービスとしてGoogle CloudであればDatastream, AWSには DMS があります。FivetranやAirbyteも同様の仕組みによるデータ連携の機能を有しています。
CDCの使い所
弊社ではデータウェアハウスとして用いているBigQueryとの親和性なども踏まえDatastreamを選択してデータ連携を実装しました。Datastreamのようなサービスを利用する際はコスト面とのバランスも重要です。バッチ連携の方が安価かつ手軽に実装できるケースも多いため闇雲に全テーブルのニアリアルタイム連携を目指すのではなく、必要に迫られたテーブルから順次対応を進めるのが合理的だと考えます。それ以外に、物理削除があったり更新差分の特定が困難などの理由で差分連携が難しいテーブルを連携する場合、データサイズが大きく更新頻度の低いテーブルを連携する場合においても有効な手段です。
次節以降ではDatastreamを導入した際の検討事項や運用していて遭遇したトラブルについてご紹介します。Datastreamに限らずCDC全般で当てはまることも多いはずなので今後導入する際の参考になれば幸いです。
CDC導入の事前準備と設計
ソースDBにロギングの設定を追加する
DatastreamはデータソースのRDBMSのトランザクションログを監視して変更を検知するという仕組み上データソースに対する準備、例えばPostgreSQLであればWALのレベルをLogicalに設定したり、Oracleの場合はサプリメンタルロギングの有効化が事前に必要となります。データソース側の状況次第では負荷やストレージに影響することも考えられるので検証しつつ慎重に進めたいところです。また、DBごとに必要となる設定項目や制約が多数あるためデータソースごとの制約事項には必ず事前に目を通すことをお勧めします。
ネットワーク経路を確認する
Datastreamにはプライベート接続の機能があり、Google CloudのVPCとPeeringすることで内部IPアドレスでの通信が可能です。しかし推移的なPeeringはできないので所定のVPCに配置されていないDB (例えばAWSやオンプレミスに配置されたDB) との間の同期のためにはリバースプロキシインスタンスの配置が必要です。図上で (中略)とされている箇所ですが、AWS, GCP, オンプレミスをVPNで相互接続1するような構造になっています。
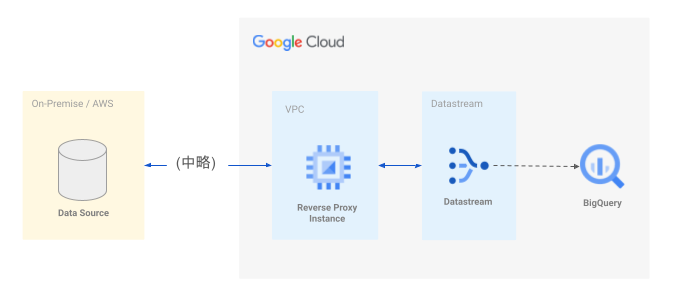
BigQueryのデータセットを用意する
CDCで連携されたデータが直接書き込まれるデータセットとデータ基盤利用者が実際にクエリするデータセットを分離しました。
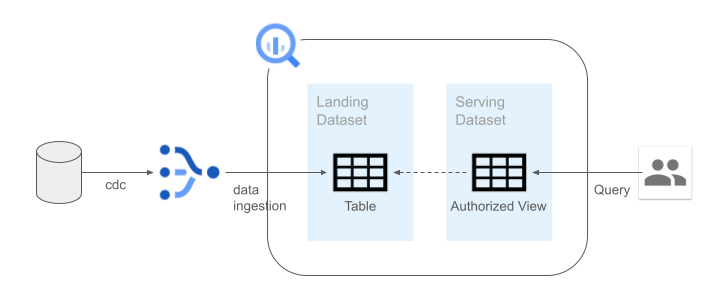
連携されたテーブルによっては全社の利用者に公開したくないケースが考えられます (例えば、氏名やメールアドレスなどのような個人情報など)。ストリームの設定によりテーブル単位・カラム単位で除外設定も可能ですが、用途によっては適宜マスクした状態で利用する等のケースも考えられるため、CDCの過程では除外せずに一度BigQuery上の非公開データセットに連携し、承認済みビューの形で公開領域に配置するという設計にしました。
最後に、連携元データベースのインフラ担当者やDBAとは密に連携を取る必要があるため早めに巻き込んでおくことが重要です。私たちは定期的にSREチーム所属の担当者と定例を持って双方のタスクを確認しながら準備しました2。
運用開始後のトラブルシューティングあれこれ
運用を開始してからいくつかデータ同期の問題に遭遇し、都度解決を図ってきました。事例集的に記載しますので何かの参考になれば幸いです。
BigQuery上で更新反映されない問題
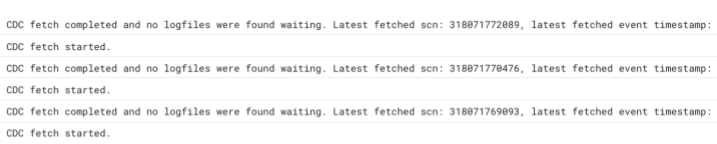
Datastream上で正常にログ出力されているにもかかわらずBigQueryへのデータ同期がされていないように見える事象がありました。これには2つの要因がありました。データソース側・宛先テーブルの側双方の要因が考えられるのでCloud Logging上のDatastreamのログを参照して切り分けることになります。
データソース側のログアーカイブ待ちによるもの
この時のデータソースはOracleだったのですが、REDOログがアーカイブされるまでの間変更は流れてこないという制約によるものでした。Datastreamのログ上はOracleのSCNは追えているが変更イベントは流れてこないという状況でした3。
BigQuery側のstalenessの設定によるもの
stalenessの詳細はリンク先のドキュメントに譲りますが、ざっくはCDCの更新イベントが到達してからBigQueryのクエリ結果として確認できるようになるまでの最大タイムラグです。max_stalenessの値を小さくすることでよりリアルタイムに近いデータ同期が実現できますが、BigQueryへの書き込み時のクエリ料金が増すというトレードオフがあるので注意が必要です。データ鮮度要求に応じて無理ない値を設定すべきでしょう。
Backfillしたらレコードが重複
データソース側で移行作業があり、テスト環境で接続設定変更を行ないデータの再同期 (Backfill) を実行したところレコードの重複が発生しました。これはデータソース側のテーブルに主キーが設定されていなかったことで発生しました (ユニーク索引は定義されていたがDDL上でPrimary Keyと明示されていなかった)。
Oracleの場合主キー指定のないテーブルに対してDatastreamはRowIDをキーと見なして同期を行うため、export/importなどでデータの物理配置が変わってRowIDが変更されると別レコードとして扱われてしまっていました。なお、PostgreSQLの場合はPrimaryKeyやREPLICA IDENTITY を指定しておく必要があります。この辺りもDBMSごとに挙動の違いがあるので把握しておく必要があります。
Datastream導入の振り返り
導入・運用をしてみて改めて良いと感じた点や難しいと感じた点がありました。
良かった点
比較的簡単な設定と現実的な費用でニアリアルタイムのデータ同期が実現できました。サーバーレスのサービスであるため、実行環境などのインフラを整える必要もなく、少人数のチームでも運用できています。
データソース側のスキーマ変更や物理削除に対する追随も可能。 特にデータソース側でカラム追加などがあった際にも特に運用対応をせずともBigQueryのテーブルに変更が反映されました。スキーマドリフトへの対応がスムーズにできたのは良いサプライズでした。
難しかった点
データソースと密結合にならざるを得ない。データソースとなるDBごとに細かい制約4があったり、ソースDBのメンテナンス時はCDCも足並みを揃える必要があり、データソースのDBに対する依存が発生します。この点はアーキテクチャ上の制約として受容する必要があります。
事前の費用見積りの難しさ。連携対象のテーブルのサイズや更新頻度の情報からおおまかなCDC費用を試算してスタートしたものの、全体としてはデータ転送・プロキシインスタンスの費用・CDCの料金・BigQuery料金と複数の費目を想定する必要があり一筋縄ではいきませんでした。実際に一定規模、かつ無償枠には収まらない程度に小規模なワークロードを動かしてみて想定外の見落としがないかチェックするのが良いと感じました。
まとめ
CDC (Change Data Capture)はデータソースとなるDBごとの制約や内部挙動の複雑さがある一方、簡易な設定でデータ同期ができる強力なソリューションです。弊社でもDatastreamを実際に導入、運用をしてみて良い点・課題点ありますが今のところ総じて安定した運用ができています。今後は利用範囲の拡大だけではなく費用の最適化やデータ欠損の検知なども強化していきたいと考えています。
また、来たる2025年に向けてはニアリアルタイムデータだけではなく、セキュリティ上考慮が必要なデータソースやそれらを扱うユースケースも増えそうなのでデータ保護の枠組みも一段とバージョンアップしてきたいと思っております。それではお体に気をつけて良いお年をお迎えください!
We are hiring !!
エムスリーのデータ基盤活用範囲は年々広がっております。コストパフォーマンスの良いデータ基盤の構築・運用やデータを活用したアプリケーション開発で活躍の場がたくさんあります。もしご興味ありましたらこちらのページからどうぞ。 カジュアル面談・ご応募お待ちしております!
- 詳しくはぜひこちらをお読みください AWS・オンプレと GCP を VPN で相互接続する際の勘所 - エムスリーテックブログ↩
- 実際のところは上述程周到な計画を立ててスタートしたわけではなく、試行錯誤しながら導入を進めました。ここではその内容を振り返って後知恵的にまとめています。↩
- テスト環境でトランザクション量が少なかったため発生していました。REDOログのサイズ次第ではレプリケーション遅延の要因になるので設定を確認して対応しました。↩
- 落とし穴が色々とあり、落ちながら学びました。公式のドキュメントもどんどん充実しているような気がします。↩