エンジニアリンググループ、データ基盤チームの鳥山(@to_lz1)です。
私は過去何度かデータ基盤に関連する記事を出していますが、データ基盤チームという肩書を付けるのは今回が初めてとなります。それもそのはず、エムスリーでは2023年4月に新たにデータ基盤チームを新設したからです*1。

そこでこの記事では、チーム創設の背景や立ち上げ期に行ったこと、そして今取り組んでいることについて紹介させて頂きます。
データ基盤のみならず、エムスリーエンジニアリンググループの雰囲気を知る一助になれば幸いです。ということで、この記事は
【データ基盤チーム ブログリレー1日目】です。
チーム創設の背景
エムスリーでは兼ねてからBigQueryを中心としたデータ基盤を整備してきましたが、これらの管理は各チームのデータエンジニアに任されていました。
BigQueryの利用に関しては最小限のガイドラインを定めるに留めており、例えばアップロード対象テーブルの追加は今も各チームがマージリクエストを出すことで成り立つことが多いです。
各チームの独立性を高く保っていたのは「それぞれのプロダクト・サービスに最適なデータ活用をスピード感を持って進めて欲しかったから」だと聞いています。個人的にもこの目論見は当たっていたと感じています。私がメンバーとして関わった範囲でも、多数のデータマートが各ユニット主導で開発され、社内分析やクライアント提供に広く活用されています。
ならばそうした状態でなぜ今チームを作るのか? というと、 「データ活用が進んだからこそより高次元の課題・要望が出てきた」 ということに尽きます。
ここで言う「高次元の課題・要望」には例えば以下のようなものがあります。
データの品質担保
データを用いて社内外に価値を届けるプロダクトは、エムスリーではここ最近いくつも生まれています。これまでの開発では
- 設計工程にビジネスサイドのメンバーを巻き込んでデータ定義を固める
- なるだけ本番に近いQA環境を用意する
といった工夫ベースで品質を確保していくことが多かったですが、正直に言って限界はあります。
気づけば、多大なQA工数を掛けて全データパターンを人手でチェックしている...といったことにならないように、必要に応じて自動テストを入れたり、データの出処を分かりやすくする仕組みを構築したりすべき、そんなフェーズに差し掛かってきたと思っています。
データの品質担保、データリネージュの可視化といった話題は様々な組織で上がるようになっており、例えば Dataform や dbt といったツールはエムスリーでも導入余地があると思います。実際に一部チームではDataformの試験的な導入が始まっています。
リアルタイムのデータ連携
BigQueryへのデータ転送処理は、現在その多くが日次のバッチとして稼働しています。
この状態でも出来ることはたくさんありますが、リアルタイムにデータを処理することで向上できる提供価値もあります。
例えば、お昼休みの行動データを用いて生成した最新のレコメンドを終業後の夕方に届けることが出来れば、ユーザーである医療従事者の方々にもより良質な体験を届けることができ、サイトとしての価値も向上する、かもしれません。
また、クライアント向けのレポーティング基盤なども恩恵を受け得ます。日次バッチの完了を待たずにレポート生成を開始できれば、データ提供のサービスレベルを底上げすることに繋がるでしょう。
既にいくつかのログデータはストリーミング処理を実装済みなのでニアリアルタイムでBigQueryに連携されますが、これに加えて事業DBのデータをニアリアルタイムで連携出来ればその意義は大きいです。変更データキャプチャリング(CDC)を導入してこうした世界を実現しに行くことも今後の課題になり得ると考えています。
より大規模・複雑なデータ活用
BiqQueryに上げたデータでシュッと機械学習モデルを構築する、といった案件であれば、弊社ではAI・機械学習チームメンバーがデータエンジニアリングまで含め完結させる場合が多いです。
しかし直近では、
- BIツールと統合して、エンドユーザが触れるプロダクトにダッシュボードを埋め込みたい
- 複数チームのデータを横断して整理し、より大局的な分析をしたい
など、技術的・ビジネス的な複雑度の高いデータ活用案件も増えてきました。MLエンジニアが少人数で案件をこなす風景が中心だった頃と比べると、データエンジニアリングの介在余地は確実に増えて来ています。豊富なデータ資産があるからこそマネタイズの機会も多くあり、事業的にも重要度の高い領域になりつつあります。
こうした様々な新しい課題には、それを乗り越えるための新しい体制が必要、ということで今回新たにデータ基盤チームを発足させた次第です。
立ち上げ期にやったこと
以下では、チーム立ち上げ期(発足直前 ~ 5月ごろ)までの活動をいくつか紹介します。
ミッションの策定
チーム立ち上げに伴って、このチームで改めて何をすべきかを関係メンバーとディスカッションしました。
ディスカッションに当たっては、各人が感じている具体的な課題を書き出し、ボトムアップで抽象化していくアプローチを取りました。
こうして作った叩き台のドキュメントを元にグループリーダーやCTOとも議論し、最終的にこのチームのミッションを
「エムスリーのデータエンジニアリングを強化して、ビジネスインパクトを直接創出するとともに、他チームの利益創出を支援すること」
と位置づけました。
CTOの山崎からは「究極的にはプロダクトのDB設計, データストアの選定を支援するような動きも期待している」という趣旨のフィードバックがあり、「データエンジニアリングを強化する」という表現にはそうしたニュアンスが込められています。
チームトポロジー*2的に言い換えれば、単にプラットフォームチームであるに留まらず、イネイブリングチームとしても動ける組織を目指そう、ということだと個人的には解釈しています。
他チームとの連携強化
ミッションを定めたは良いものの、例えば他チームのビジネス支援といった仕事は我々だけでは成り立たず、隣接諸組織との連携が欠かせません。これに関しては愚直に以下のような動きで関係強化を図りました。
- PdMへのヒアリング
- 事前に自分たちが想定・想像したデータに関する課題を持っているか?
- 直近立ち上がりそうなプロジェクトへの介在余地はあるか?
- そのステークホルダーは誰か?
- 個別案件のアーキテクチャ検討
- 複数チームのエンジニアを交えてのAsIs-ToBeの整理
- 実装方針・移行方針の策定
- 費用最適化に悩むチームへの支援
- BigQueryに関する技術調査
- 対策の立案と選定
- 手を動かしての実装
工程を選り好みせず、その時々で最も必要とされる部分に取り組めたのは良かったと思います。これについては、それまでの自分のタスクを巻き取って立ち上げに専念できるようにしてくれた方々、そして課題解決に向けて協力してくれた各チームにも本当に感謝しています。
オンボーディングプロセスの整備
6月に新メンバーがjoinすることが決まっていたため、初日のタスクリストやドキュメントの整備を急ぐ必要がありました。主には以下のような活動をしています。
- Confluenceのスペース作成
- システム構成図の整備
- First Issueに向いていそうなチケットの選定
他チームのオンボーディングドキュメントも参考にしつつ、最低限のものは揃えられたかな...と思いますが、何分まだ手探りです。ここはメンバーとともに継続改善していきたいポイントです。
今やっていること
今現在、データ基盤チームでは例えば以下のような活動をしています。
プロダクトチームのバックエンド開発
製薬企業向けプラットフォームチーム(Unit1)はその名の通り製薬企業のクライアント向けのサービスを複数持つチームです。
このチームが持つプロダクトの中に、BigQuery上のデータをユーザー向けのダッシュボードとして表出する機能があります。いわゆるReverse ETLですね。
このバックエンドのデータパイプラインの改修をデータ基盤チームの方で担当しています。
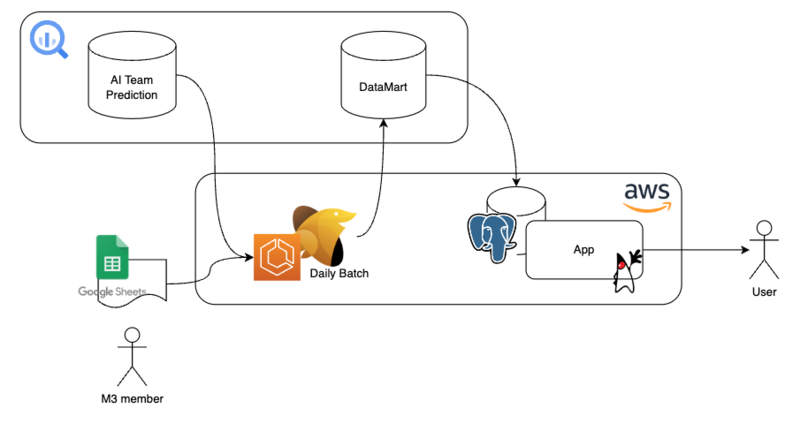
パイプラインを通して組み上がったテーブルを元アプリケーションからそのまま取り込むことで、プロダクト側ではパイプラインの詳細を感知せずにデータを利用できます。改修に当たっては、
- データ項目の追加やカスタマイズが容易な設計にしたい
- 現在PoC的に導入頂いているクライアントもおり、そのデータは変わらず維持したい
といった要件もあり、こうした条件を満たしつつ持続可能なパイプラインを目指しています。主な利用技術はDigdag, SQL, Terraform(Google Platform Provider)等です。
運用効率化
BigQueryの利用普及に当たっては、利用者の権限申請などいくつかの定型業務をSlackワークフロー化しており、チーム発足以前から効率的に回せている業務も多いです。
しかしながら、新たな課題というのは出てきます。例えば使わなくなったテーブルの削除作業です。エムスリーでは各日ごとに変更があったデータをそれぞれ別テーブルとして連携しているケースがあります。例えば5年間貯めたテーブルが1,800テーブルを超える、といったことも起きています。
これらのテーブルを使わなくなりました、という場合に1,800回の削除作業を手で行うのは非現実的です。bq rmコマンドを利用するにしても、いちいちスクリプトを書いていてはミスの可能性が否定できません。
そこで、最近BigQueryのテーブルを掃除するためのCLIツールを自作し、OSSとして公開しました。Go言語製です。
bqsweeper --project [BIGQUERY_PROJECT_ID] invalidate my_dataset 'old_table.*' 20230731
などのコマンドで、正規表現に合致する全テーブルに一括で有効期限を設定することが出来ます(なおエムスリーでは、業務に関連するものであれば業務時間をこうしたOSSの開発にも充てられます)。コントリビュートもお待ちしています!
レガシーからの脱却
2000年創業のエムスリー、古くから伝わり維持困難なデータ加工処理や、モノリシックなオンプレミスDBを間借りした加工テーブルも(だいぶ減りましたが)存在します。これらを廃止することも直近の取り組みの1つです。
古いデータソースやシステムを廃止し、利用者への周知も行って移行を進めていくことには、例えば以下のビジネス価値があると考えています。
- モノリシックなDB脱却による費用削減
- データ基盤の運用保守工数の低減
- データの品質や可用性が上がることによる分析価値の向上
これはデータ基盤に限った話ではないですが、レガシーの存在を前提として諦めるのではなく、真っ向から技術力で立ち向かうのがエムスリーの文化の1つだと思っており、個人的に好きなところでもあります。
もちろんリソースは有限なので、他のさまざまな開発とバランスをとる必要はあります。しかし、先に挙げたビジネス価値と天秤にかけ、やる価値があるならやる。ということで、必要と決めた部分には粛々とメスを入れています。
We are Hiring!!
以上、チーム立ち上げの背景と、活動内容について紹介させて頂きました。
一口にデータ基盤と言ってもやることは多岐に渡っています。Looker(LookML)などここで紹介しきれなかった技術も多数扱っていますし、新たなツールも必要性があれば導入することになるでしょう。
目指す世界の実現に向けてはまだまだ手が足りていないです、ということで、他チームの例に漏れずデータ基盤チームでもメンバーを絶賛募集中です!
「エムスリーのデータエンジニアリングを強化して、ビジネスインパクトを直接創出するとともに、他チームの利益創出を支援すること」というミッションに共感頂けるデータエンジニアの方を求めています。
少しでもご興味を持った方は、以下ページよりカジュアル面談等に申し込み頂ければと思います!