エムスリーエンジニアリンググループ AI・機械学習チームでソフトウェアエンジニアをしている中村(@po3rin) です。 好きな言語はGo。仕事では主に検索周りを担当しています。
Overview
医師に質問ができるサービスであるAskDoctorsではユーザーが質問を検索できる機能があり、今回は検索改善タスクのために検索ログデータ分析基盤を構築したお話をします。これにより改善サイクルを回せるようになったり、検索ログを使った各種アルゴリズムが利用可能になりました。
データ基盤構築では他チームとの連携が必要不可欠であり、コミュニケーションで工夫した点などもお話できればと思います。
- Overview
- なぜ検索ログデータ分析基盤が必要なのか
- データアーキテクチャを書き出す
- イベントとデータスキーマを定義する
- Google Analytics の BigQuery Exportの設定
- BigQuery Exportのスキーマ
- データレイクからデータマートへ
- 検索品質ダッシュボードの作成
- データ基盤構築のためのチーム連携
- 直近の検索改善の動き
- まとめ
なぜ検索ログデータ分析基盤が必要なのか
モチベーションは主に3点です。
- 検索を監視して改善サイクルを回せるようにしたい
- 各種アルゴリズムに利用できるデータを取得したい
- データ分析に利用したい
検索を監視して改善サイクルを回したい
検索システムは作ったら終わりではなく、ユーザーの検索行動を監視して、より良い検索品質を改善していけるような体制を作る必要があります。今回はBigQueryとRedashを使って、検索ログ収集を行い、検索改善に必要な項目を確認できるダッシュボードを作成しました。
各種アルゴリズムに利用できるデータを取得したい
Query Understanding分野ではクエリ拡張、クエリセグメンテーション、クエリサジェストなどで検索ログを使う手法が提案されています。また推薦アルゴリズムでも、クエリからユーザーの志向を特徴量として利用できるようになります。下記の本がQuery Understandingについて詳しいので興味ある方はぜひ読んでみてください。僕も今ちょうど読んでいる途中。
")
データ分析に利用したい
AskDoctorsはサブスクリプションサービスであり、会員になってもらうこと、継続利用してもらうことが大切です。そこで検索ログを利用して検索と関連する退会率、入会率の分析なども行えれば最高です。
データアーキテクチャを書き出す
まずはデータアーキテクチャを図に書き出します。どこからデータを取って、どこに保存して、どこで使うのかを図で表現します。特に複数チームでデータ基盤を構築するためにはこのようなデータアーキテクチャを作成し、チーム間でイメージを共有しておくことが重要です。弊社ではデータウェアハウスとしてBigQueryを採用しているのでBigQueryを中心としたアーキテクチャになります。
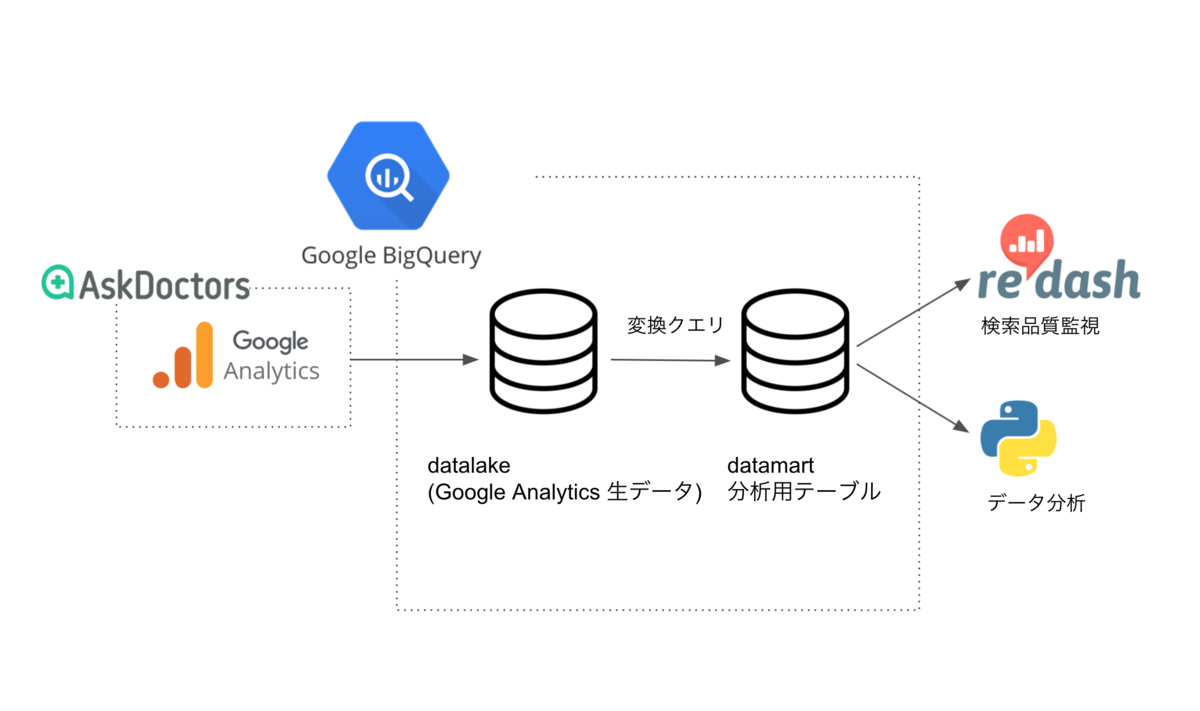
今回はGoogle Analyticsに送ったトラッキングデータをBigQueryに自動で同期してくれるGoogle AnalyticsのBigQuery Exportという機能を使います。BigQuery Exportはgoogle analytics 4 property(略称: GA4)の機能であり、この機会にGA4にアップデートを行いました。
BigQuery Exportで自動でBigQuery内に作成されるテーブルをデータレイクとし、検索に関わるデータだけを抽出し、検索ログ分析用のスキーマに変換します。後から説明しますがBigQuery Exportで作成されるテーブルはかなり特殊な構造になっているのでデータ利用促進のためにも、データマートとして使いやすい形に変換しておくことが非常に重要でした。
イベントとデータスキーマを定義する
検索に関連するイベントをGoogle Analyticsのイベントトラッキングで送信してもらう必要があります。一口に検索に関連するイベントと言ってもその種類は多岐にわたり、検索に関わるイベントを全てリストアップする必要があります。
- 初回の検索
- 検索結果の表示
- 検索結果のクリック
- 検索結果ページに遷移した後の「戻る」
- 検索結果ページに戻った後の再検索
- 検索結果ページに戻った後の別記事のクリック
- 検索結果ページからの離脱
- クエリを修正して再検索
- ページング
- 関連キーワード機能の利用
- 検索結果がゼロ件だった
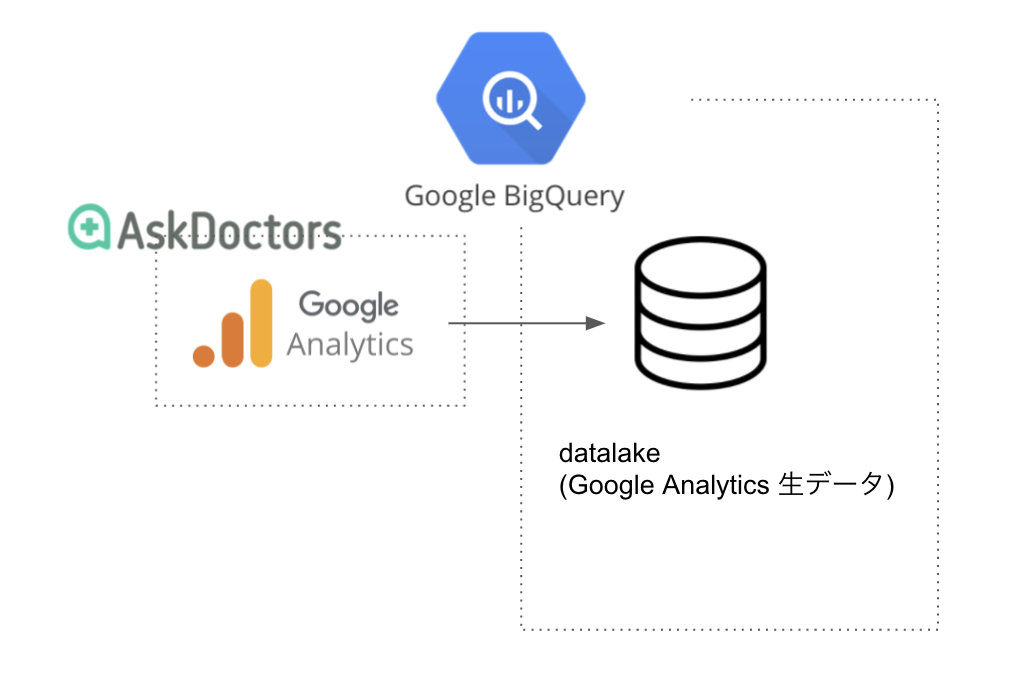
上記のアクション全てでイベント送信の有無、イベント送信するならどのようなデータを送るかを決める必要があります。今回はイベント全てに対して下図のようなイメージ図を作成しチーム間で仕様をすり合わせました。
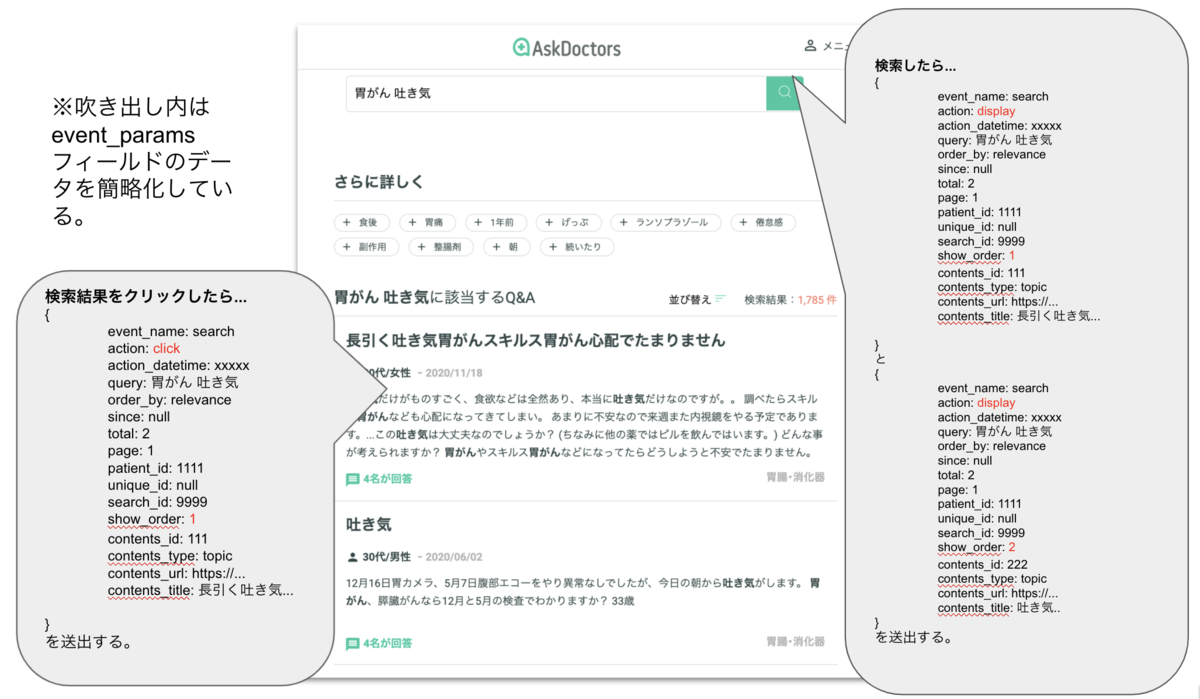
今回は検索結果のアイテムごとにイベントを送信するという姿勢をとっています。例えば20件の検索結果があった場合は、そのアイテムのデータとランキングとクエリが紐づいた20件のデータを送信します。
クリックされた記事は別途イベントを送信します。このようにアイテム1つに注目してデータ送信すると、 検索結果の各アイテムのランキングが取得でき、後から検索エンジンの評価がしやすくなるというメリットがあります。
過去に検索エンジンの評価手法としてsDCG*1を紹介しましたが、このように「検索結果の何番目が表示されたか」を利用するような評価手法が利用できるようになるのでランキングはデータとして取れるようにしておきましょう。 www.m3tech.blog
「戻る」の扱い
実は「戻る」の扱いは重要です。ブラウザバックで戻った後にもう一度検索結果表示のイベントを発火してしまうと検索イベントを2重に取得することになります。もちろんブラウザバックでの表示もカウントしたい場合もありますが、我々のアプリケーションでは記事の表示回数よりも、1回の検索結果で何番目の記事がクリックされたかが重要だったため、今回は「戻る」で表示した検索結果のイベントは送信しないと決めました。
検索セッションの定義
検索セッションとは、1人のユーザーの同じ検索意図が続く一連のアクションを指し、どこまでを1セッションと定義するかは検索アプリケーションによって変わります。
検索セッションIDなどを振っておくことでユーザーの一連の検索行動を紐付けて分析することが容易になります。例えばクエリ修正やページングなどは1つの検索意図を満たすための行動なので、これらを検索セッションIDで紐づけておくことで、ユーザーがどんな経路でゴールまでたどり着いたか、または諦めたかを後から追うことができるようになります。
検索セッションの定義には色々ありますが、我々の定義では下記以外のアクション(例えばトップページに戻るなど)は全て検索セッションIDをリセットすることにしました。
- 再検索
- 検索した記事のクリック
- 検索した記事からの「戻る」
- ページネーション
また、検索してタブを開きっぱなしで別の検索意図で再検索もあり得るので、30分が経過した場合も検索セッションIDをリセットしています。
Google Analytics の BigQuery Exportの設定
設定方法はドキュメントに書いてあるのでそちらを参考に設定しました。
新しく作ったサービスアカウントにはプロジェクト編集者権限というかなり強い権限が必要になるので注意してください。
BigQuery Exportのスキーマ
ドキュメントを見ればわかる通り、実はBigQuery Exportで作成されるテーブルはかなり特殊な形をしています。
event_paramsという列名あたりを見るとわかる通り、event_paramsがRECORD型であり、さらにevent_params.keyもRECORD型で、各値は型それぞれ列が定義されています。BigQueryのプレビューっぽく表にすればこんな形になります。
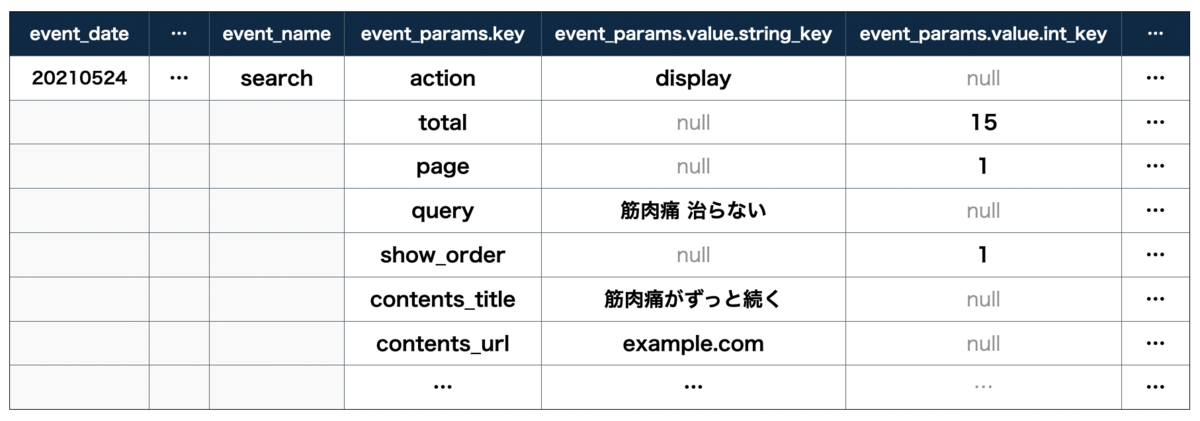
valueが複数型あるkey-valueをこのように表現しているのは中々面白いですね。しかし、データ分析する際には少し困ります。
データレイクからデータマートへ
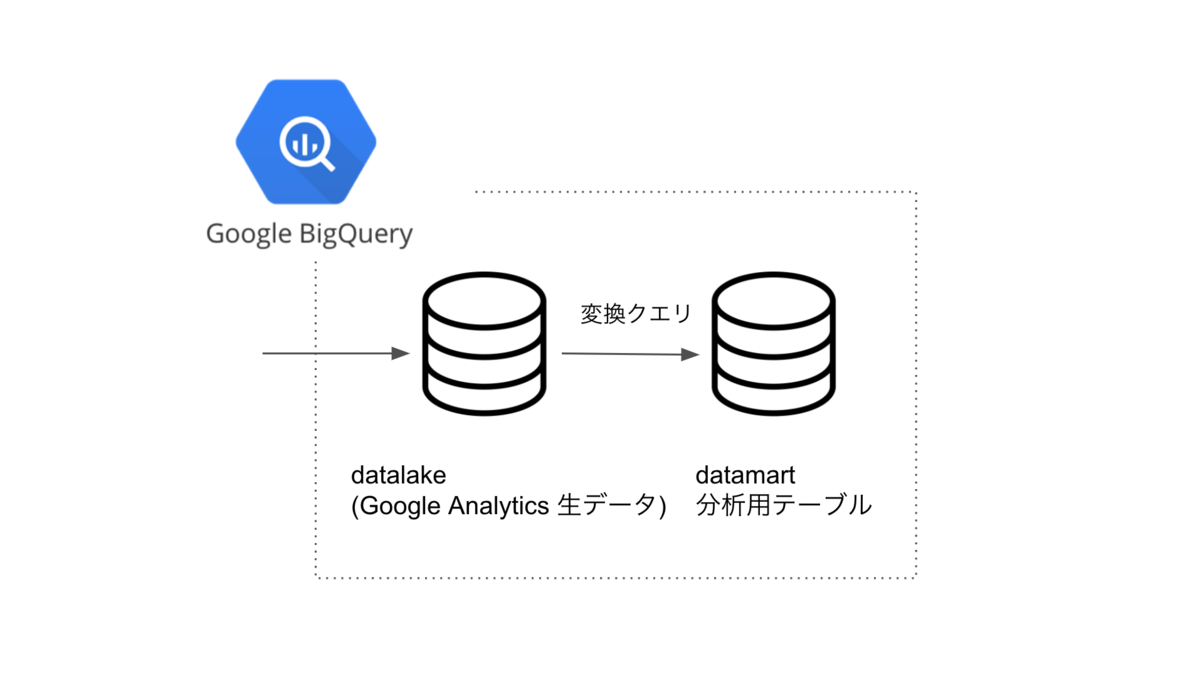
event_paramsがRECORD型で、型ごとに格納されるカラムが違うとなるとデータマートの出番です。データマートでは集計や分析がしやすい形にデータをまとめておきます。データレイクからデータマートへのデータ変換はワークフローエンジンDigdagでスケジューリングしています。
変換用SQLは少し苦戦したので簡単なExampleクエリを貼っておきます。
WITH with_row_num AS ( SELECT ROW_NUMBER() OVER() as row_num, user_id, event_timestamp, event_params FROM datalake ) SELECT MAX(if(param.key = "search_id", param.value.string_value, NULL)) AS search_id, MAX(if(param.key = "query", param.value.string_value, NULL)) AS query, MAX(if(param.key = "total", param.value.int_value, NULL)) AS total, MAX(if(param.key = "page", param.value.int_value, NULL)) AS page, MAX(if(param.key = "show_order", param.value.int_value, NULL)) AS show_order, MAX(if(param.key = "contents_title", param.value.string_value, NULL)) AS contents_title, // ...(省略) FROM ( SELECT row_num, user_id, event_timestamp, param FROM with_row_num, UNNEST(event_params) AS param ) GROUP BY user_id, event_timestamp, row_num
UNNESTしたものをGROUP BYしてMAXとIFで型ごとに列名を指定して値を引っ張ってきます。こちらの方法は下記の記事を大いに参考にしました。
上の記事のようにevent_timestampでデータが一意になれば良いのですが、今回は検索結果表示時に表示された記事の数だけevent_timestampが同じものが飛んできているので、user_idとevent_timestampだけではデータがユニークになりません。代わりに前処理として、ROW_NUMBER() OVER()を使って全てのデータに一意なIDを振っています。これで複雑なスキーマを平らにできます。(もっといい方法あれば僕のTwitterアカウントからDMください)
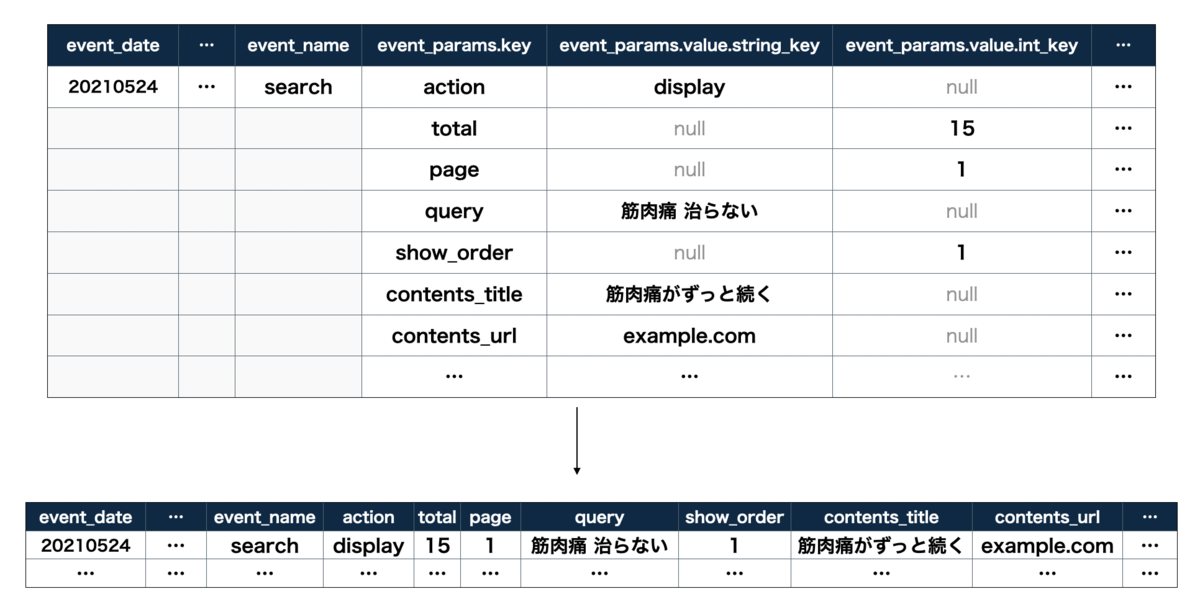
これで集計や分析がしやすくなりました。この過程は非常に重要で、データ基盤構築の最終目標であるデータ活用を促進するための重要な処理です。
検索品質ダッシュボードの作成
最後の成果物としてRedashを使った検索品質監視ダッシュボードを作成しました。実際に作った表やグラフはお見せできませんが主に下記のような項目をダッシュボードですぐに確認できるようにしました。
- 非会員と会員の検索セッション数
- 人気のクエリとクリック率
- 検索結果がゼロ件のクエリ
- 何ページ目がクリックされているか
- etc ...
まだ初期段階なので簡単な項目しかありませんが、ビジネスインパクトの大きそうな項目や検索改善に役立ちそうな項目をどんどん追加していきたいと思います。
データ基盤構築のためのチーム連携
このようなデータ基盤を作るときは他のチームとの協調が必要であるため、いつもより丁寧に仕事を進める必要がありました。そのため、これまでに紹介したデータアーキテクチャ図や、イベントに対するイメージ図を作成しておくとチーム間でズレが少なくなるのでオススメです。
また、今回のように複数チームでデータ基盤開発に取り掛かる場合は、互いのチームのデータ基盤構築の優先度を高めることも重要です。今回はデータアーキテクチャで得られるビジネス価値を書き出すことで、互いのチームの「やろう!」を高めることに成功し、すぐに開発に取り掛かることができました。
直近の検索改善の動き
早速ですが「検索結果のヒット数とサイト利用の相関」があることが分かっているので、直近の検索改善の打ち手として検索ヒット数が少ないクエリを分析して検索改善を行う動きがあります。
今回の検索ログ分析基盤を使ってクエリにひもづくヒット数が簡単に取得できるので、どのように検索アルゴリズムを修正すればいいかをすぐに検討することができます。
このように検索ログ分析基盤があると次の打ち手を考えるハードルが下がるので、ビジネスにとっても非常に便利です。
まとめ
今回はGoogle AnalyticsのBigQuery Exportを使って検索ログデータ分析基盤を構築した話をしました。今後は検索ログを使ってアルゴリズムの改善やデータ分析に利用していき、より多くのユーザーにこのサービスを届けることができれば最高です。
今回参考にした本
データ基盤を作る際にはこちらのデータマネジメントに関する本[2]が非常に勉強になりました。データマネジメントを体系的に学んだことがなかった私のような方には非常にオススメです。

We're hiring !!!
エムスリーでは検索&推薦基盤の開発&改善を通して医療を前進させるエンジニアを募集しています! 社内では情報検索論文輪読会が発足し、日々検索や推薦についての議論も活発です。
「ちょっと話を聞いてみたいかも」という人はこちらから! jobs.m3.com