この記事はエムスリーAdvent Calendar 2020 20日目の記事です。
エンジニアリンググループ AI・機械学習チームの李です。弊社では記事に対して疾患薬剤などのタグを付与するシステムGaussと、記事についたタグとユーザーのPV情報を利用してユーザーに興味のあるタグを紐づけるシステムMaxwellが存在します。Maxwellで使う特徴量を増やしたいというモチベーションがあるのですが、1つ考えられるのは記事についたタグに対して感情分析の結果を追加で利用することです。そこで、感情分析タスクをBERTで解く論文「Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence」 (Sun et al., 2019) を弊社のサービスで提供される医療記事に適用してみました。

感情分析タスク
感情分析は自然言語処理タスクの1つであり、人間に書かれたテキストに含まれた意見がポジティブか、ネガティブか、それともニュートラルかを判断する分類問題です。例えば「ワクチンAはインフルエンザの予防にとても効果が良い」「開発されて間も無いワクチンAはリスクが高い」「新しく開発されたワクチンAの接種が昨日から始まった」の3つの文はそれぞれポジティブ・ネガティブ・ニュートラルの意見を述べています。
しかし実世界の文章では、必ずしもこのような、一個の対象(ワクチンA)の1つの観点(効果/リスク)に対する感情ばかりではありません。仮に上の3つの文が1つの文章である場合に、ポジティブ・ネガティブ・ニュートラルから一個だけ振り分けるようなナイーブな感情分析の問題設定では「何」に対する感情なのかが変わらず、文に含まれた情報を取り損ねてしまうのです。これを解決するための感情分析問題設定の変種が存在します(それぞれの例を上の図に示しています)。
- Aspected-Base Sentiment Analysis: 同じ対象に対して、複数観点(aspect)からの感情分析。同じ文にある対象の異なる側面から記述する場合に、対象の「何」についての感情なのかを答えられる問題設定です。
- Target Aspected-Base Sentiment Analysis: 複数対象(target)の複数観点からの感情分析。複数の対象が同じ文書で述べられた場合に、「どの対象」の「何」に対する感情かをそれぞれ出せる問題設定です
BERTで感情分析タスクを解く
Bidirectional Encoder Representations from Transformers (BERT)というのは、2018年提案された大量データで事前学習した言語モデルを転移学習でいろんなタスクへ転用し、SOTAを刷新した強い手法です。最近自然言語処理の分野ではベースラインとして扱うことが多くなってきて、紹介する優秀な記事がたくさんあるためここは詳細を省きますが、BERTによるTABSAを解く手法だけを紹介したいと思います。
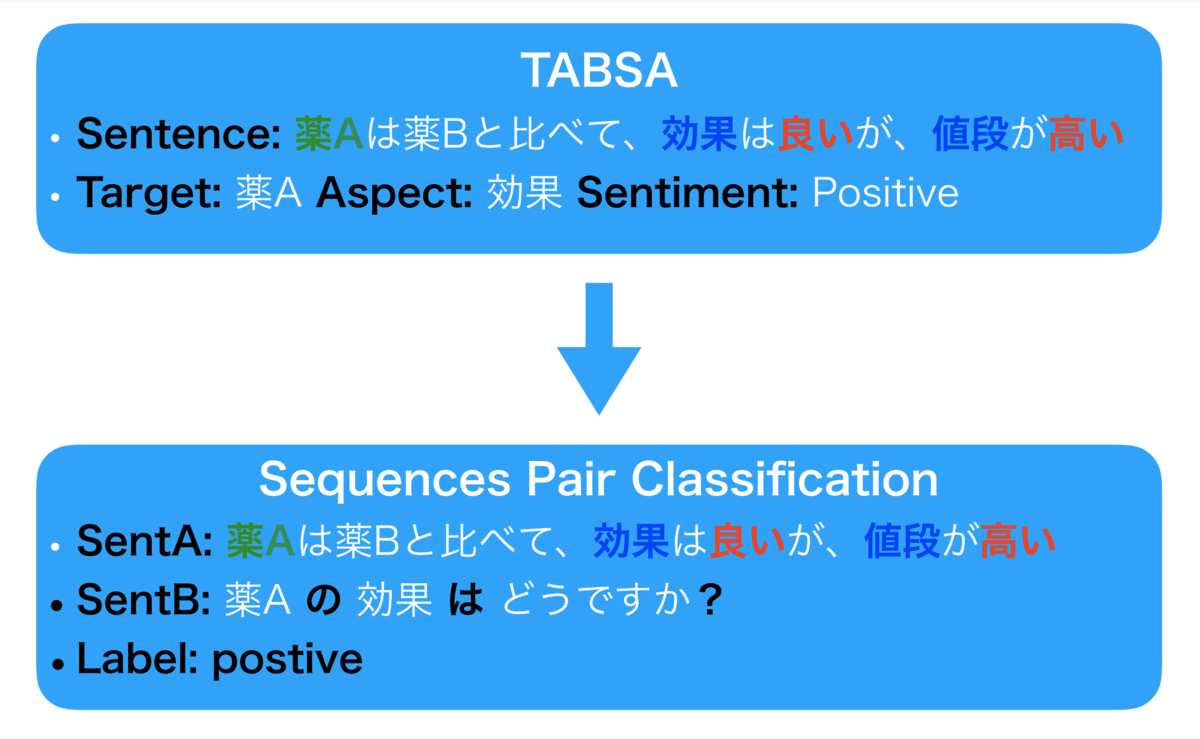
1つの文を1つの感情ラベルを振るナイーブの感情分析問題設定はテキスト分類問題に当てはまるので、簡単にBERTを適用できるのですが、TABSAでは一文の中にある複数の対象にラベルを付与しないといけないため、BERTで解くにはちょっと工夫が必要になります。[Sun et al., 2019] で提案されたのは、「対象」「観点」と「感情ラベル」の3つの要素から新しい文を生成し、元の文とペアを組んでBERTの文ペア分類タスクを解く枠組みを使うやり方です。例えば下の図に示した例ですが、「薬Aは薬Bと比べて、効果は良いが、値段が高い」のうち、「薬A」(対象)の「効果」(観点)に対して感情分析を行う場合に、「薬Aの効果はどうですか?」のような文を生成し、元の文とのペアのラベルが「ポジティブ」になるような正解データが作られます。
この文の生成方法ですが、上で示した例では疑問形式な正しい日本語文章になっていますが、元論文では「薬A - 効果」みたいに文法に合わないような文の生成方法も提案されました。彼らの実験ではちゃんとした文章の方がやや正解率が高いという結果が示されたので、今回もその設定のみで実験を行いました。
医療記事に入ってる薬剤名に対して分析してみる
データ
日本語の医療記事に特化したTABSAデータセットは存在しないのですが、幸いにTIS株式会社さんが経済記事のデータセット「chABSA-dataset」 を公開しています。230記事分7000以上ある「対象-観点-感情」のペアを学習データ6960、検証データ762に分けてTABSAモデルを学習しました(一般的にテストデータも必要ですが最終的に医療記事に試したいのでここで用意しなかった)。また今回は時間の都合上特にドメイン適応を行えず、ドメイン外の経済記事データセットで学習したモデル(BERTの汎用性に期待して)そのまま医療記事で適応してみました。ベースのモデルに使ったのは京都大学黒橋研究室が公開した日本語に特化したBERTです。
結果
まずは「chABSA-dataset」でのパフォーマンスです。検証データでの結果になりますが、ハイパーパラメータを全部元論文の設定のままで1エポックで95%、3エポックで96%の正解率を達成できました。ドメイン適応一切行ってないので、経済記事に過学習してしまい医療記事で全く使えるものにならないことを防ぐため、医療記事でテストした時は1エポックのみ学習したモデルを使いました。
テストデータは1ヶ月分のニュース記事で、感情分析の対象はそれらの記事に付与された薬剤Gaussタグです。「chABSA-dataset」では「全体的」の観点以外に、「売上」「利益」などの経済記事で注目される観点が入ってますが、医療ニュースの場合はそれらの観点への関心が低いため、テスト時は「全体的」という観点のみを使用しました。
Gaussの方で付けられた薬剤タグがたくさん存在しますが、今回はわかりやすくポジティブ・ネガティブ両方になりうるようなタグ「アルコール」と「酸素」で具体例をみてみました。下の図で示したように、アルコールに関して、「死亡率が高い」などの表現が含まれた場合はネガティブに、「水分補給が大事」みたいな表現がある場合はポジティブに分類されていることがわかります。

定量分析
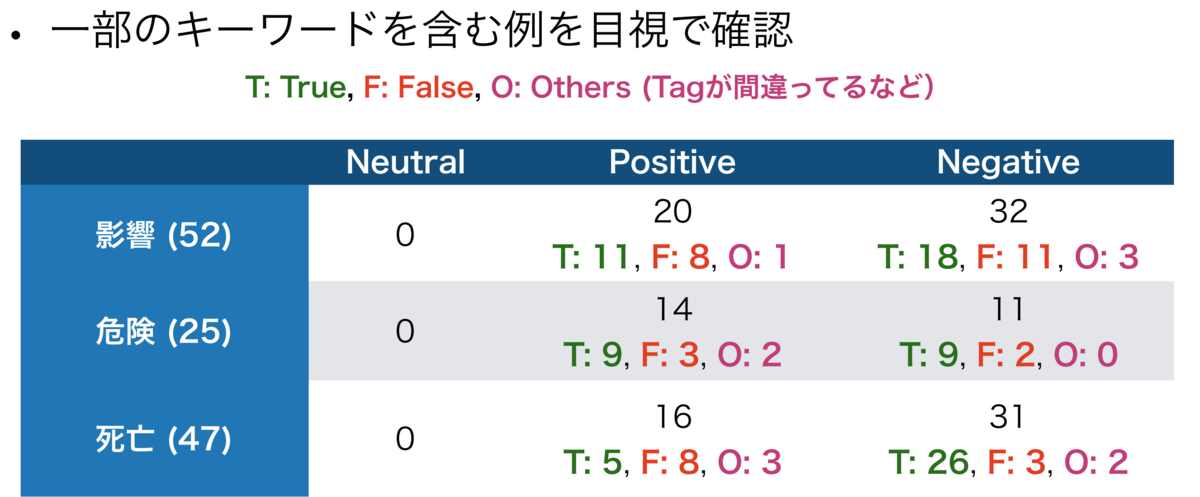
医療記事での正解データが存在しないため定量分析が難しいですが、1824件ある記事中から、「影響」「危険」「死亡」の単語を含む記事たけを選びその結果を目視で確認し、感情分析の結果が正しいかどうかを統計してみました(かなり主観の要素が入ってしまうので、数字は参考程度です)。
下の図で示したように、この3つの単語にそもそもネガティブな意味合いが含まれているからか、それらの単語の入った記事をネガティブに分類した場合の正解率が高い反面に、ポジティブに分類された場合の正解率がかなり下がってしまったのです。特に「死亡」に関してはTrue PostiveはFalse Postiveより少ない結果になりました。
まとめ
今回は、経済記事のTABSAデータセットで学習したモデルを医療記事へ適応する試みを紹介しました。「アルコール」や「酸素」の例のようにうまく感情分析できたケースもあるのですが、定量分析で示した数字から見ると、ドメイン外の医療記事で出せた正解率は経済記事ドメイン内のデータでの結果と比べてまだまだ低いことがわかりました。使えるような精度を出すためにこれらの論文で提案された方法でドメイン適応を取り込む必要がありそうです。
[1904.12848] Unsupervised Data Augmentation for Consistency Training
We are hiring!
この記事に出てきたGaussやMaxwellなどのシステムを含め、エムスリーでは自然言語処理が活躍できる場面はたくさんあるので、興味のある方はぜひ応募してみてください!