こんにちは、AI・機械学習チームの浮田 (id:uKita) です。この記事は エムスリー Advent Calendar 2022 の16日目の記事です。
私達のチームでは、推薦システムなどWebサービスの他に、臨床現場で使われるAIの開発にも取り組んでいます。ちょうど最近、この領域で行っていたプロジェクトが論文誌に掲載され、プレスリリースとして公開されたので、このプロジェクトについて前半で紹介します。後半では、これまで様々な医療データを扱ってきた中で筆者が実感した技術的な難しさについて紹介します。
間質性肺疾患診断AIの開発
エムスリーでは以前から、間質性肺疾患などの肺疾患に対するAIに取り組んできました (以前のプレスリリース)。今回その取り組みの一部が、European Respiratory Journalという雑誌に掲載されました。論文のリンクはこちらです。
この論文で行ったことは主に以下の3点です。
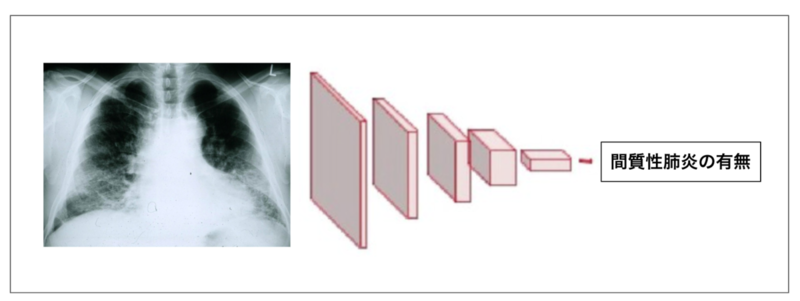
- 計1159枚の胸部X線 (レントゲン) 画像を用意。各画像には「線維化を伴う間質性肺疾患」(以下、間質性肺疾患) の有無がラベル付けされている。
- このデータをもとに深層学習で分類器を学習した。
- 複数の観点から性能を評価した。
これらについて以下解説します。
{kind=link}
データセットと学習方法
計1159データのうち、positive (間質性肺疾患あり)が653例、negative (間質性肺疾患なし)が506例です。胸部X線画像は一般的に縦横それぞれ2000ピクセル以上の解像度を持つこともありますが、ここでは876ピクセル x 876ピクセルにdownsampleして解析に使用しました。
学習では、DenseNetベースの分類器を用いています。
評価方法
まずhold-outデータにおけるROC-AUCは0.979と非常に高い結果でした。
この論文ではまた、モデルの精度と医師の精度を比較しました。具体的には、同一のhold-outデータを用いて、医師が間質性肺疾患の有無を判定する精度とモデルの精度を比較しました。結果、モデルの精度は医師の精度と比べて謙遜ない (非劣性である) 結果でした*1。
さらにまた、全く別のデータセットを用いて再度モデルの精度も検証しています。その際にも、ROC-AUCは0.910~0.970と高い結果でした。
これらの結果から、医師にも劣らない精度で本モデルは胸部X線画像上の間質性肺疾患の兆候の有無を分類できることが分かりました。
医療画像を扱う技術的な難しさ (面白さ)
私達のチームでは、上記間質性肺疾患のプロジェクト以外にも様々な医療データを使ったタスクに取り組んでいます。間質性肺疾患のプロジェクトでは高い精度が出ていますが、他のタスクではさらに工夫が必要な場合もあります。ここでは、筆者がこれまで様々な医療データ、特に医療画像を扱ってきた中での難しさ、言い換えれば面白さについて、いくつか紹介します。
データが少ない
機械学習、特に深層学習においては一般的に多くのデータが必要ですが、Webサービスなどと比べると臨床現場において収集できるデータ量はやはり少ないことが多いです。この背景には
- データを取得する機会が少ない:例えばWebサービスにおけるユーザのアクティビティ (例:購入やクリックログ) と比較すると、臨床現場におけるアクティビティ (例:胸部X線の撮影、患者の来院イベント) は当然頻度が少ない。
- 複数の医療機関からデータを収集するコストが大きい。
- 古いデータまでさかのぼろうとすると、解像度などの撮影条件が違いすぎたり、そもそもデジタルデータが存在しなかったりする。
- 過去のデータを後向きに収集すると、leakが発生することもある:「皮膚がんの画像を撮影する時には定規を入れて撮影するため、定規の有無だけで皮膚がんかどうかを判定できてしまう」というleakの例がよく知られており、*2 こういったleakを含むデータを学習に使うのは厳しい。
などがあります。少ないデータで学習するためには工夫が必要です。
訓練データとテストデータに区切る時にはK-fold cross validation (CV) を丁寧に行う
元々少ないデータを訓練データとテストデータにsplitすると、評価用データはさらに少なくなります。(特にstratified) K-fold CVを行うことで、精度は評価用データのノイズに対してロバストになることが期待できます。
事前学習を工夫する
データが少ない場合には事前学習が有効です。特に、本来解きたいタスクと近いタスクでの事前学習が有効と考えられています。*3 このことから、医療データにおいては医療画像の大規模データセットでの事前学習が効果的だと期待できます。*4
医療画像の大規模データセットを使わない場合には、ImageNetのような自然画像のデータセットを使うことが多いと思いますが、さらに他のデータセットを使った例もあります。例えば、CT画像 (xyzの3次元) からのクラス分類タスクにおいて、YouTubeのような動画 (xytの3次元) を使った事前学習が効果的だったという面白い話があります。*5 今後はもしかすると、フラクタル画像を用いた事前学習なども有効かもしれません。*6
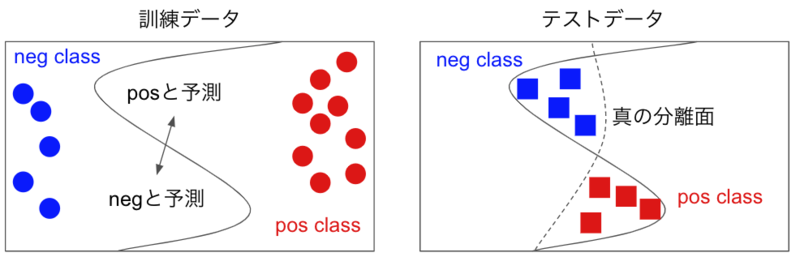
医療機関ごとのデータの性質の違い
例えばA病院のデータで学習したモデルがB病院のデータには精度が悪い、ということがしばしば起きます。この原因としては、上記の間質性肺疾患診断を例に考えると、
- A病院とB病院では撮影に使用する装置のメーカーや画像の解像度、撮影方法などが異なり、画像の性質が異なる *7
- A病院には「肺がん」の画像が存在しなかったが、B病院には「肺がん」の画像 (つまり正常のようなきれいな肺ではない画像) が多く存在し、それらがfalse positiveになってしまう
- A病院には重症の間質性肺疾患患者しかいなかったが、B病院にはより軽症 (つまり病変が明らかではなく、正常に近い) の患者が多く、それらがfalse negativeになってしまう
などがあり得ます。これらの問題に対しては、できるだけ多様なデータを収集する、data augmentationなどで多様なデータを生成する、などの対策が考えられます。また、iterativeにモデルを改善できる状況なら、false positiveとfalse negativeのどちらが多いのか、どういったデータが苦手なのかといった分析をもとに改善していくことも不可欠です。
自然画像と医療画像の微妙な違い
例えば自然画像分類におけるdata augmentationの際は、vertical flipやhorizontal flipなどの手法を取り入れることが一般的かと思います。一方、例えば胸部X線画像は、基本的に上下の向きは決まっていますし、心臓の左右も決まっています。*8 このような場合にvertical flipやhorizontal flipを使うことが本当に最適なのかは、自然画像分類とは異なるかもしれません。私達のチームではdata augmentationの際にはAlbumentationsを使用していますが、変換後の画像を目で確認して、明らかに本来とは異なる画像が出来ていないかを確認するなどを心がけています。
またこの問題については、実際に色々なaugmentationを試す以外にも、Autoaugmentのような自動的に最適なaugmentationを探索する方法を取り入れた例もあります。*9
このように、自然画像において広く使われている方法が医療画像ドメインにおいても本当に最適かどうかは分からないため、試行錯誤や工夫のしがいがあります。
まとめ
本記事では、私達のチームが実際に行った事例と、筆者が実感している医療データの特徴について紹介しました。なお、本記事の後半では主に問題の解き方について書きましたが、本分野での問題の設定の仕方については、以前チームの大垣がまとめた記事に詳しいです。
また、これらの開発を加速するための取り組みについては、以前発表した資料にまとめてあります。
We are hiring!!
エムスリーでは、このような医療画像はもちろん、様々な複雑な課題を技術的に解決できるメンバーを募集しています! 以下のURLからカジュアル面談お待ちしています!
*1:この医師の精度は、医師 (放射線科医と呼吸器内科医) が胸部X線画像だけから判定した時の精度です。教師ラベル付けにはCTなど胸部X線画像以外の情報も使っているため、医師の精度も100%になるとは限らない設定になっています。
*2:https://www.ben-evans.com/benedictevans/2019/4/15/notes-on-ai-bias
*3:https://openaccess.thecvf.com/content_cvpr_2018/html/Zamir_Taskonomy_Disentangling_Task_CVPR_2018_paper.html
*4:実際に複数の事前学習方法を比較した例:https://academic.oup.com/brain/article/143/7/2312/5863667, https://www.thelancet.com/journals/landig/article/PIIS2589-7500(21)00056-X/fulltext
*5:https://www.nature.com/articles/s41598-020-61055-6
*6:https://link.springer.com/article/10.1007/s11263-021-01555-8
*7:https://dl.acm.org/doi/fullHtml/10.1145/3313831.3376718
*8:もちろん右胸心の場合は別ですが