こんにちは、エムスリー エンジニアリンググループ / 製薬企業向けプラットフォームチームの鳥山 (@to_lz1)です。
これは エムスリー Advent Calendar 2020 の19日目の記事です。
エムスリーでは現在、各システムのオンプレ環境からクラウドへの移行を急ピッチで進めているところです(勉強会の配信アーカイブをYouTubeでもご覧いただけます。公式テックチャンネルのご登録、ぜひお願いします!)
これに関連して私のチームでも最近「データ基盤(Digdag + Embulk)のクラウド移行」を行ったため、そのときに考えたことや移行して良かったことを共有したいと思います。

エムスリーのデータ基盤について
データ基盤の定義は諸々あろうかと思いますが、概ね
- 複数のシステムにあるデータを統合するもの
- データの収集・蓄積・加工・可視化といった機能を持つもの
と整理出来るかなと思います。また、これらの機能を実現するためのジョブ実行管理も欠かせない要素です。
これらのデータ基盤の各機能を、エムスリーでは以下のようなツールの組み合わせで実現しています。
| 機能 | 対応するサービス・ツール |
|---|---|
| 収集 | Fluentd / Embulk など |
| 蓄積・加工 | BigQuery |
| 可視化 | BIツール群(Tableau, Redash, Data Studio, etc.) |
| ジョブ実行管理 | Digdag など |
これらをどう連携させ、活用しているかという点に関しては以前に実施したイベントでもお話しさせて頂きました。
基本的にはほとんどの部分がモダナイズされていて、運用管理の負担も大きくなかったのですが、唯一と言っていいペインポイントが今回お話する Digdag + Embulkの部分でした。歴史的な経緯もあってこの部分はオンプレミスの仮想環境に残っていたのです。
それまでの構成
オンプレミスとは言っても、このDigdagはサーバ2台のHA(High Availability)構成 + Ansibleでの構成管理が実現されていました。
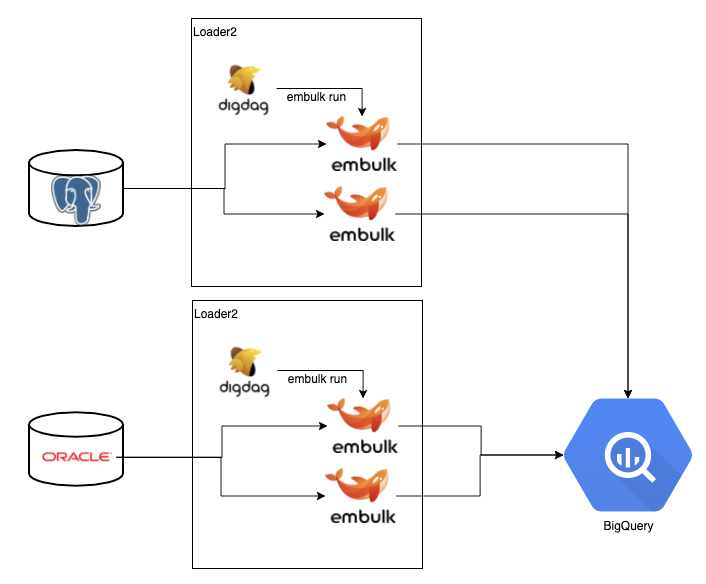
Digdag はもともとHA構成に対応しているため、どちらのサーバがどのタスクを担当するかをその時のリソース状況でよしなに判断してくれます。
なのでこれはこれで理想的な構成に見えるのですが、実は大きな弱点を孕んでいます。それは「DigdagとEmbulkが同じサーバに同居していること」です。
サーバの負荷がなんらかの理由で高くなると、Digdagのサーバ内でEmbulkのデータ転送タスクが詰まってしまいます。それでも次のジョブの時間はやってきてしまうため、また新たな Embulkプロセスが起動し、結果どんどんサーバのLoad Averageが高くなる、という悪循環に陥るのです。*1
また、データソースとなるシステムがオンプレミスに多くあった頃はETLサーバがオンプレミスにあることにも一定の意味があったのですが、クラウド化の機運が高まってくるとそうも言っていられません。データソースだけがクラウド移行した場合、データの流れとしては「クラウド(元システム) => オンプレ(Embulk) => クラウド(BigQuery)」となってしまい、効率が良いとは言いがたい状況になります。
こうした課題を解決するため、今回Digdag + EmbulkをAWSへと移行することにしました。*2
クラウド環境でのアーキテクチャ
オンプレミス環境での反省を活かし、クラウド化に当たってはいくつかアーキテクチャの変更を行いました。
DigdagとEmbulkの分離
まずはDigdagとEmbulkのコンテナの分離です。DigdagにはEmbulkのECS Taskのキックだけに集中してもらい、Embulk自身も「1テーブルの連携 = 1コンテナ」の粒度となるように設計しました。
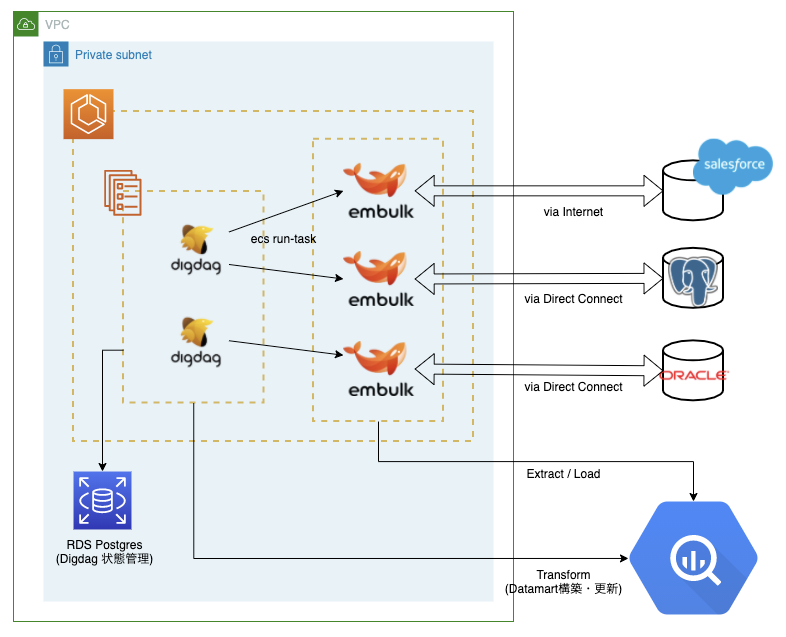
また、EmbulkのDockerイメージは複数に分け、Embulkだけインストールした共通のベースイメージに各データソース用のレイヤーを加える構成にしました。具体的には例えば、
- Oracle用: Base + Oracle用のpluginをinstall + yml.liquidをCopy
- Salesforce用: Base + Salesforce用のpluginをinstall + yml.liquidをCopy
といった形でbuildされます。これにより、プラグインや連携対象テーブルを増やした時に影響範囲を小さく変更リリースできるようになりました。また、こうした工夫により1コンテナにかかる負荷も大幅に軽減され、高いレベルのスケールアウトが行えるようになりました。*3
Digdag on AWSからBigQueryを操作する
Digdagにはデータの転送のみならず、転送後のデータマート構築もやってもらっています。これはDigdagからBigQueryに直接クエリを発行することで実施しています。計算自体はBigQueryの基盤で行われるため、Digdagにとっては大きな負荷要因にもなりません。なのでこの方式はクラウド移行後も踏襲することにしました。
Digdagには標準で bq>: オペレータがあるのですが、これは自分のチームの基盤では使用していません。主な目的としてはBQの最新機能に追随したいためです。このため、DigdagのDockerイメージにgcloud CLIを直接インストールして使っています。
GCPへの認証のためにはサービスアカウントのJSONが必要となります。秘密情報の保持のために、Digdagにはsecretsという機能があり、オンプレミスではこれを使っていました。
Command reference — Digdag 0.10.5 documentation
Digdag provides basic secret management that can be used to securely provide e.g. passwords and api keys etc to operators.
が、今回はDigdag secretsもあえて使用しませんでした。
これは、コンテナ起動後にprojectの数だけdigdag secretsコマンドを叩く必要があるなど、設定作業がやや面倒と感じたためです。これを機にいっそコマンドを叩くオペレーション自体を全廃できないかと考えました。
最終的には、Dockerイメージに以下のようなエントリポイントを仕込んでコンテナ起動時にactivateすることで解決できました。
#!/bin/bash # Digdag起動前にgcloudをactivate export GOOGLE_APPLICATION_CREDENTIALS=/etc/gcp_credential.json echo $GOOGLE_APPLICATION_CREDENTIALS_JSON >> $GOOGLE_APPLICATION_CREDENTIALS gcloud auth activate-service-account --key-file $GOOGLE_APPLICATION_CREDENTIALS # render configuration files using environment variables envsubst < /etc/server.properties.template > /etc/server.properties envsubst < /etc/.bigqueryrc.template > /root/.bigqueryrc /usr/local/bin/digdag server \ -c /etc/server.properties \ "$@"
JSON文字列の保管にはAWS SSMを利用し、ECS Serviceの起動時に与えるようにしています。
これにより、「Fargateサービスが立ち上がったらsecrets設定なしで即awsコマンドとbqコマンドが両方使える」という状態を実現出来ました。「新しいDigdag projectを作ったけどsecretsの設定を忘れたから本番だけ失敗した」のような事態が起きる可能性もゼロではないので、こうしたエラーを未然に撲滅できたのは良かったなと思います。
併せて行った改善(Sentryでの障害検知)
クラウド化それ自体もデータ基盤の安定稼働に大きく貢献したのですが、それと並行していくつかの改善を入れました。その中で特に運用しやすさが向上したと思ったのがエラー通知周りの改善です。
それまで、基本的に処理の成否通知はSlackで実施していました。Digdagの通知用pluginがあり、弊社でも愛用されています。
大体のユースケースはこれ1つで事足りるのですが、細かい面での課題も生じていました。例えば、
- 失敗通知が成功通知に埋もれがち
- エラーの履歴を把握することが難しい
などです。解決手段はいくつかあると思うのですが、弊社ではエラーの通知基盤にSentryを利用していたため、DigdagとSentryとの統合が出来ないか調べてみることにしました。
.digファイルでSentry通知を書く
Sentryには色々な言語でのSDKが用意されていますが、それらのSDKがしていることは煎じ詰めればSentryのエンドポイントへのPOSTリクエストです。この辺りはSentryのSDK開発者ドキュメントを読むと非常にわかりやすく書いてあり、参考になります。
Overview | Sentry Developer Documentation
最初はDigdagプラグイン開発の機運か!? と思っていたのですが、よく考えてみればHTTPリクエストを送るだけであればDigdag標準のオペレータで実現可能です。そこで、http>: オペレータでの実現を模索したところ、以下のような .dig ファイルを作ることでSentry通知を送れることが分かりました。
+generate_event_id: py>: helpers.sentry.generate_event_id +capture: http>: https://sentry.io/api/${SENTRY_PROJECT_ID}/store/ method: POST headers: - X-Sentry-Auth: "Sentry sentry_version=5, sentry_client=1, sentry_timestamp=${moment().unix()},sentry_key=${SENTRY_CLIENT_KEY}" content: event_id: ${sentry_event_id} timestamp: ${moment().toISOString()} environment: ${DIGDAG_ENV} exception: type: "Digdag ETL Error" # Digdagの仕様上、エラーメッセージしか取得できないので型名取得は諦める value: ${error.message} tags: workflow: ${task_name.split(/[+^]/)[1]} message: formatted: "failed task name is ${task_name}. stacktrace is shown below:" params: - ${error.stacktrace} platform: "other" content_format: json
あとはこれをエラー時に実行してあげるだけです。なお、SENTRY_PROJECT_ID, SENTRY_CLIENT_KEY, DIGDAG_ENV 辺りのパラメータは別途設定しておく必要があります。
ポイントとしては、
- POST時にイベントのUUIDを生成して送る必要がある(上記の例ではPythonスクリプトで実現している)
- Digdag上では例外の細かい情報を取得できない(
error.message,error.stacktraceくらいしか参照できない)ため、深追いしすぎない
ということでしょうか。
Sentryへの通知は最終的には結局Slackに転送するのですが、その際にはエラー専用のSlackワークスペースを利用しています。今回Sentry通知を導入したことで、他システムのエラー通知と一貫した仕組みでの障害検知を行えるようになりました。地味な変化ですが、「データ基盤のエラーだけは通知経路が違っていて成功通知に埋もれているんですよね...」という状態だとやはり人に伝えるときに辛いので、やって良かったと思います。
slaと組み合わせた初動対応
また、最終的にはこの通知をDigdagの sla: ディレクティブと組み合わせました。
Scheduling workflow — Digdag 0.10.5 documentation
この機能を使うと所定時間内に終わらなかったワークフローがあった時に通知を送ったりできます。これを用いて「いつもより遅れた処理があったときに即時検知する」ということが日常的に行えるようになりました。
これにより、
- 不慮の事態でECSタスクがハングした => 朝一で気づいてstop
- タスクが増えた関係でそれまでの実行時間を超過した => ワークフローの構成をリファクタ
...など、「傷が広がる前に手を打つ」ということがかなりの精度で出来るようになってきました。
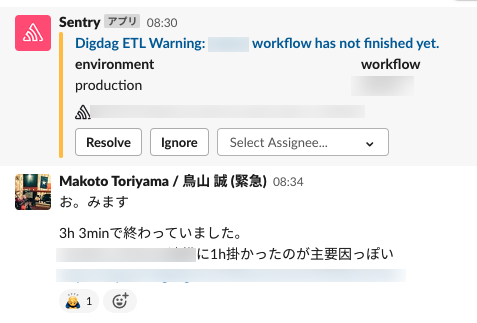
バッチ処理系、特にデータ処理系のエラーや遅延というのは発覚が遅れたりそもそも気づけない場合も決して少なくありません。現状の仕組みが強力に働いてくれているなという実感があります。
まとめ
以上、Digdag + Embulkの困った部分を解決するべくクラウド環境に転生させた話をお送りしました。考えてみれば、すでにオンプレミスで動いているものを本番に動かす、というのはこれが自分にとって初めての経験でした。しかし、
- 比較的小規模なため取り組みやすかった
- 自分自身が運用していて課題に感じたことをアーキテクチャに反映させた
- 自社ですでに使える or 構築済みのインフラを把握した上で設計を考えた
という辺りが成功要因だったかなと思います。また、インフラ設計のレビューやTerraformの作成などは関係各所のエンジニアの方々に大変お世話になったので、この場を借りて感謝申し上げます。
今回ご紹介した改善ポイントは細かい部分も多かったですが、データ基盤は自分が開発者としてよく触る部分だったので、その運用が楽になった! というメリットを実感できたのは非常に良かったです。皆さんが快適なクラウドライフを送る上で何かヒントになったら幸いです。
We are Hiring!
エムスリーでは、データを用いて価値を生み出したいエンジニアを広く募集中です。
データ基盤の管理のみならず、その基盤を使ったシステムの開発や施策の実現など出来ることもたくさんあります。よろしければぜひ以下から応募を検討してみて下さい!
*1:こうなると、最悪のケースではサーバを再起動しても溜まったタスクをDigdagが一斉起動してしまって全く改善しないなど、非常に困った状態になります。最終的にDigdagの内部DBに直接アクセスしてタスクをdeleteして対応したことがありました。その際こちらの記事のER図が大変役立ちました cf: Digdag serverでH2やPostgreSQLのデータベースにデータを格納する - Qiita
*2:なお、BigQueryを利用しているのにAWSを選択したのにはいくつか理由があって、そのうち大きなものはオンプレミス系のシステムとDirectConnectでの通信経路がすでに構築済みなためです。オンプレミスとのバランスを保ちながらクラウド化することも重要と感じています
*3:もちろん無限にスケールするわけではなく、この構成だとデータソースとなるDBの読み取りパフォーマンス、ついでオンプレミス系からAWSまでデータを持って行く際のネットワーク転送で律速することになります。この辺りは適宜モニタリングを行いながら移行作業を実施しました