
【デジカルチーム ブログリレー1日目】
こんにちは、デジカルチームの鳥山(@to_lz1)です。
プロダクト開発の傍ら、人事チーム(=ピープルサクセスグループ)向けに内製したデータ基盤の開発も担当していたりします。
今回は主務の話から逸れますが、こちらの話です。Google Cloud Workflowsを採用した処理基盤が比較的うまく回っているため、開発・運用の中で得られた知見をご紹介したいと思います。
システムの概要
弊社人事メンバーは採用管理システム(ATS)、勤怠管理システムなどいくつかのシステムを管理者として利用しています。そこから得られるデータの分析も重要な業務の1つです。
- ATSのデータを用いた、採用への応募から、面接、オファーまでの通過率の分析
- 勤怠管理システムのデータを用いた、残業時間などの確認
しかし複数のシステムを使っている関係上、いくつかの課題が発生していました。例えば以下のようなものです。
- データが分散しているので突合作業が必要で、負担になっている
- 準備したデータに対して「去年分のデータも見たい」と言われたときにタイムリーに反応できない
こうした課題を解決するため、BigQueryを中心にデータ基盤を構築したのが本プロジェクトの始まりです。
Workflows導入前の構成は、以下のようになっていました。
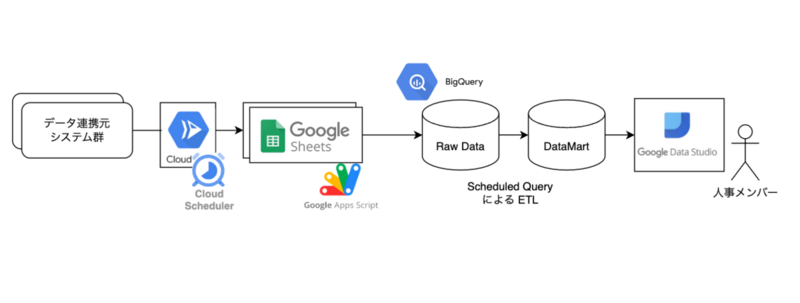
人事業務に関するデータ基盤のため詳細を書くことは難しいですが、
- 複数のデータソースから、Cloud Schedulerが起動したCloud RunによってGoogle Spread Sheetにデータを集める
- 集まったデータを、Google Apps Script によってBigQueryに連携する
- BigQuery上の生データを、Scheduled Queryによってデータマート化
- 人事メンバーがData Studio(現Looker Studio)で閲覧
- 更新サイクルは概ね日次
といった構成です。
これはこれで効果的に動いていましたが、データ取得元を増やすなど拡張を重ねるにつれ、新たな課題も発生してきました。例えば処理の依存関係がわかりにくく、前段が失敗していることに気付かないまま処理が動いてしまう...などです。
「今日、データ更新されてなくないですか?」と日中に人事メンバーから言われて気付く といった事象が度々発生したりしていました。
上図でも分かる通り、このパイプラインには定時で処理を実行する主体が複数存在してしまっています。
- Cloud Run を kick する Cloud Scheduler
- GASの画面上で設定したトリガー
- Scheduled Query
これらを協調させて「前の処理成功してるよね?」といった確認を都度行うのは難しいです。課題の源泉がこの辺りにありそうと考えたので、GASとScheduled Queryを極力廃止し、処理の実行基盤を別のプラットフォームに一本化する方向で検討を進めました。
Google Cloud Workflowsについて
Google Cloud WorkflowsはGCP上の様々なサービスの呼び出しをワークフローとして統合できるサービスです。発表は2020年の8月で、類似のサービスであるCloud Composerと比べれば新しいサービスといえます。
いくつか代替サービスも検討しましたが、
- Cloud Runなど既存資産がGCP上にあるため、Connectorという形式でこれらの呼び出しをサポートしているWorkflowsは親和性が高い
- Pricingに分がある(月5,000stepまで無料、代替となるCloud Composerなどに比べると安価)
- yamlベースでワークフローを構築でき、実装が容易
- サーバーレスのため運用負荷が低いと期待できる
といった要素が今回の要件にはマッチしており、採用に至りました。
具体的に利用している機能
以下では、ワークフロー内で実装している内容をいくつか例とともに説明します。
Sub WorkflowによるBigQuery SQLの実行
移行元にScheduled Queryによって実行される複数のクエリがあったので、そこに登録されているクエリを実行するための基盤が必要でした。
yaml内にSQLを書くような悪魔合体があっては後の変更が大変ですから、なんとか関心を分離したいと考えました。少し調べたところ、以下の事例が大変参考になりました。
main の ... step から、それぞれ別の SQL のファイルパスを渡し、GCS の SQL ファイルデータを取得して BigQuery にクエリ実行するサブワークフローを実行します。
この構成を取ることで、任意のクエリの実行がyaml上でわずか4行で表現できるようになりました。
- createTableFoo: call: exec_query # Sub Workflowにまとめた部分。詳細は引用元の記事を参照 args: file_name: "create_table_foo.sql" - createTableBar: call: exec_query args: file_name: "create_table_bar.sql"
Sub Workflowの詳細は引用元の記事に譲りますが、中では以下を利用しています。
parallel stepsによる並列実行
最初にデータソースが複数あると記述したのですが、これらのデータソースの間には特に依存はなく、集めてくる処理は並列で動いても差し支えありません。というか、並列にしないと時間の無駄になってしまいます。
Workflowsではparallel stepsと呼ばれる機能で並列実行がサポートされるので、こちらも併せて利用しています。
Parallel steps | Workflows | Google Cloud
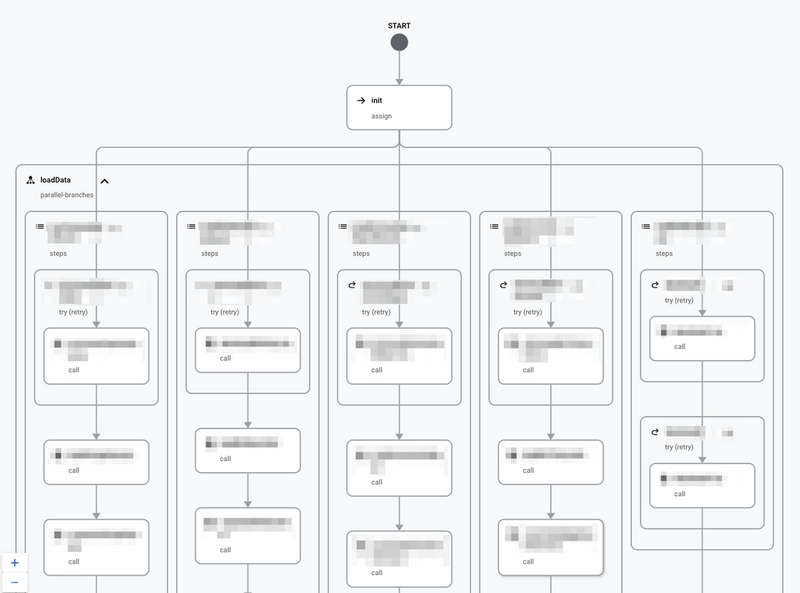
コンソールでは構築したワークフローを可視化してくれるので処理の流れは一見して分かりやすいです。テンションもちょっとだけ上がります。
Terraformでのコード管理
ワークフローはTerraformで以下のようなResourceとして定義しています。
resource "google_workflows_workflow" "workflows_main" { name = "main-${var.env_name}" region = "us-central1" description = "main workflow for daily update" service_account = google_service_account.workflows.id source_contents = templatefile("workflows/main.yaml", { service_a_download_url = google_cloud_run_service.service_a_download_url.status[0].url, service_b_download_url = google_cloud_run_service.service_b_download_url.status[0].url, dataset_name = var.dataset_name, query_bucket_name = google_storage_bucket.query_bucket.name }) }
工夫というか少し注意を要する点として、ワークフロー内で変数を使いたいときにも$始まりで表現することになっていることがあります。何も考えずにyamlを書いてtemplatefile関数に噛ませると、ワークフロー内の変数までtemplatefile関数で置換されてしまい困ったことになります(なりました)。
少し読みづらくなりますが、yaml内の変数は $$ でエスケープし、templatefileによって置換したいところは $ で記載する必要があります。
main: steps: - init: assign: - now: $${time.format(sys.now(), "Asia/Tokyo")} # Workflowsのレイヤで変数として処理される - downloadDataOfServiceA: try: call: http.get args: url: ${service_a_download_url}/exec # terraform plan|apply 時に置き換わる auth: type: OIDC timeout: 1800 result: downloadResult # ...
運用してみてよかったこと
Workflowsへの移行を済ませたあと、集計データをGSSに書き戻したいといった要件が挙がってCloud Functionsを書くことになりました。思い返すと、この追加開発はWorkflowsに移行していた事によって非常に楽に実装できたと思います。
- リポジトリにFunctionを追加
- TerraformとしてResource化
- URLを使ってワークフローに呼び出し処理を記載
- terraform applyでデプロイ
ステップ自体はありふれていますが、処理がGASにも書かれていた頃を思うと1つのリポジトリで開発が完結するだけでも楽です。また、切り戻しも容易だったので動作確認と修正のサイクルは安心感を持って回すことが出来ました。
システムとしてもツールとしても概ね安定してきたので現在のところ開発は落ち着いていますが、先日人事のメンバーからも
「毎日使っておりとても便利! 集計の手間もなくなったし、リアルタイムで数字が把握できるので課題の発見からアクションするまでが早くなった。このシステムがなかった頃が考えられない!」
というフィードバックを頂けました*1。特に、MTG中に欲しい数字がパッと出せる、という点は意思決定を高速化する上でも効果を発揮しているようで、開発してきてよかったなと思えた瞬間でした。
課題・改善したいこと
エラー時の対応のしやすさ
エラー発生はCloud MonitoringとSlack通知で検知していますが、いざコンソールの画面を見に行ってもCloud Run呼び出し時のステータスコードがJSONに出ているだけだったりするので、ここは今後の改善に期待したいところです。
例えばどこで失敗した、がグラフィカルに分かるとか、対応しているCloud Run / Cloud Functions のログに飛べるとか、が機能追加されると嬉しいなと思っています*2。
Cloud Functions第2世代への対応
Cloud Functionsを実装した話を途中で挙げましたが、現在これが第1世代のものに留まっています。
タイムアウト最大値が遥かに長いなど恩恵も多いのでシュッと移行したいのですが、URLが決定的でないためにワークフローに設定するための情報が Terraform Resource の Attribute として取得できない問題があります。
Cloud Functions バージョンの比較 | Google Cloud Functions に関するドキュメント
現在、Cloud Functions(第 2 世代)の関数 URL は非決定的な形式を使用します。つまり、デプロイ前に関数の URL を予測することはできませんが、デプロイ後、URL は安定したままです。第 2 世代の関数の URL は、今後のリリースで安定的かつ確定的に更新される予定です。
こちらは現時点でComing Soonとの記載があるので、発表され次第追随したいと思っています。
まとめ
今回は弊社内、人事チームのIT活用にGoogle Cloud Workflowsを採用・運用してみた話をご紹介しました。広くコーポレートエンジニアリングと呼んでも良い領域かと思います。
Google CloudのプロダクトマネージャーであるFilip KnapikさんはGCP上でのオーケストレーションツールの選定についてこのように述べています:
Cloud Composerは、データエンジニアリングパイプライン、ETLオーケストレーション、ビッグデータ処理、機械学習ワークフローに最適な選択肢です。
なので、今回のようなパイプラインの実行基盤にWorkflowsを用いるのは実は「王道」ではないかもしれません。
しかしながら、「BigQueryの多くのユーザのデータ保存量の中央値が、実は100GBをはるかに下回るほどでしかなかった」という話も聞かれます。
個人的には、こうした「Bigではないデータ」の取り回しにはWorkflowsは隠れた選択肢として有望なのでは、と思うに至っています。
GASを使って業務の自動化をしている企業やチームは数多あると思いますが、「運用していてつらい...でも、DataflowとかCloud Composerを使うのは明らかにやりすぎなんだよな...」といったステータスのチームもまた、この中に多く含まれているのではないでしょうか。
GASはGASで非常に便利なので否定するものではありません。しかし、上記のシナリオがちょっとでも当てはまるな、と感じた方はGoogle Cloud Workflowsの検討機運、訪れているのかもしれません。筆者の観測する限りでは事例紹介が少ないサービスだったので、参考になれば幸いです。
We are Hiring!
エムスリーでは、プロダクトの課題にも、社内の課題にも、技術を用いて全力でぶち当たっていくメンバーを募集しています。 少しでも面白そうと思って頂けた方、カジュアル面談や採用のご応募をお待ちしています。
なお、主務であるデジカルについては、こちらでチーム紹介資料をご覧いただけます。チームメンバーによる別記事もお楽しみに!