こんにちは、エムスリーエンジニアリンググループ コンシューマチームの園田です。
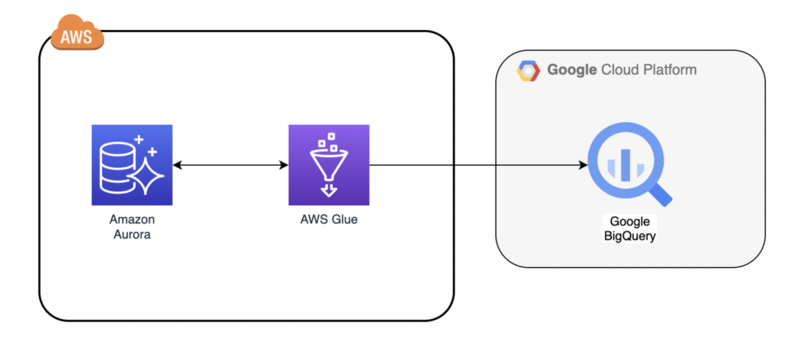
Google BigQuery Connector for AWS Glue を使って AWS 上にあるデータを BigQuery に書き込むというのを Terraform でやっていきます。 BigQuery から AWS へのデータ取り込みはググればいくらでもヒットするのですが、逆パターンはほとんどなかったのと、公式ドキュメントも不十分だったので備忘を兼ねて投稿します。
この記事は エムスリー Advent Calendar 2022 の 8 日目の記事です。前日は @no_clock による「Renovate をゆるく運用しはじめて半年が経ちました」でした。
Connector や Glue のバージョンはそれぞれ以下のとおりです。
- Google BigQuery Connector for AWS Glue 0.24.2 *1
- AWS Glue 3.0 - Supports spark 3.1, Scala 2, Python 3
ポイントは以下の 4 点
- BigQuery からの Read では credentials の設定に
Secrets Managerが使えるけど Write ではなぜか使えない - Glue の Context で
SparkConfを上書きするやり方が、通常のspark-bigquery-connectorの手段と異なる - データベース接続の credentials で
Secrets Managerを使うとなぜかエラーになる - VPC で実行する場合はアウトバウンドを許可しないと ECR の API がタイムアウトする
なお、この記事では AWS 側の実装を取り扱うため、BigQuery で利用する Google のサービスアカウントと GCS バケットはあらかじめ用意してあるものとしています。
- 想定シナリオ
- ざっくり手順
- Aurora 用の AWS Glue Connection 作成
- BigQuery 用の AWS Glue Connection 作成
- AWS Glue Job 用の IAM ロール作成
- AWS Glue Job 作成
- ジョブの実行
- ソースコード評価時に発生したエラーたち
- おわりに
想定シナリオ
今回は AWS の Amazon Aurora で構築されたデータベース上にあるデータを JDBC ドライバーで読み込み、BigQuery に取り込む処理を実装してみたいと思います。
本来なら AWS Glue Crawler を定義して Aurora データベーススキーマのメタデータ (テーブル構造など) を収集してから ETL ジョブを実装するのがセオリーだと思います。ただ、それだと前置きが長くなりすぎるため今回は DB テーブルのデータを直接読み込んで、無変換で BigQuery に取り込む処理を実装します。
ざっくり手順
- Aurora 用の AWS Glue Connection 作成
- BigQuery 用の AWS Glue Connection 作成
- AWS Glue Job 用の IAM ロール作成
- AWS Glue Job 作成
Aurora 用の AWS Glue Connection 作成
今回のシナリオではデータソースを Aurora とするため、Aurora に対する Connection を作成します。データソースを S3 や DynamoDB にする場合は Connection の作成は不要です。*2
なお、Connection とは、AWS Glue の AWS リソースの 1 つで、データソースとの接続情報を表すものです。Connection とは別に Connector というのもあるので紛らわしいですが、本稿では Connection と書いたら Connection リソースのことを指します。
セキュリティグループの作成と変更
VPC 内の Aurora をデータソースとする場合、AWS Glue の JDBC Connection には DB 接続が可能な VPC サブネットとセキュリティグループを指定する必要があります。また、一時ファイルや Spark のログなどを S3 に出力するため、S3 に対するアウトバウンド通信が許可されている必要があります。
上の公式ドキュメントでは「自己参照の I/O と、S3エンドポイントに対するアウトバウンドの許可を追加」と書いてありますが、今回は新しいセキュリティグループを作成し、アウトバウンドの許可はそちらで行うようにします。また、Google BigQuery Connector for AWS Glue は ECR にアクセスできないと Connector のコンテナイメージがダウンロードできずにタイムアウトエラーが起きます。us-east-1 の ECR に対する VPC エンドポイントを用意するのがベストですが、今回は面倒なので全アウトバウンドトラフィックを許可しています。
まずは自己参照の I/O ルールです。すでにある場合は不要です。
variable "database_connection_security_group_id" {} data "aws_security_group" "database" { id = var.database_connection_security_group_id } resource "aws_security_group_rule" "ingress_self" { security_group_id = data.aws_security_group.database.id type = "ingress" from_port = 0 to_port = 65535 protocol = "tcp" self = true } resource "aws_security_group_rule" "egress_self" { security_group_id = data.aws_security_group.database.id type = "egress" from_port = 0 to_port = 65535 protocol = "tcp" self = true }
続いて新規セキュリティグループを作成して、アウトバウンド許可を追加します。
variable "glue_security_group_name" {} resource "aws_security_group" "glue" { name = var.glue_security_group_name vpc_id = data.aws_security_group.database.vpc_id tags = { Name = var.glue_security_group_name } } # 全アウトバウンドトラフィックを許可(s3 と ecr のみに絞った方がベター) resource "aws_security_group_rule" "egress_all" { security_group_id = aws_security_group.glue.id type = "egress" from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] ipv6_cidr_blocks = ["::/0"] }
S3 エンドポイントなどを追加する場合は以下のようになると思います。
data "aws_vpc_endpoint" "s3" { vpc_id = aws_security_group.glue.vpc_id service_name = "com.amazonaws.${data.aws_region.current.name}.s3" } resource "aws_security_group_rule" "egress_s3" { security_group_id = aws_security_group.glue.id type = "egress" from_port = 443 to_port = 443 protocol = "tcp" prefix_list_ids = [data.aws_vpc_endpoint.s3.prefix_list_id] }
AWS Glue JDBC Connection の作成
クレデンシャルとセキュリティグループができたら Connection を作成します。
variable "database_cluster_identifier" {} variable "database_connection_subnet_id" {} variable "database_name" {} variable "database_force_ssl" { default = false } variable "database_credentials" { type = object({ username = string, password = string }) sensitive = true } data "aws_rds_cluster" "database" { cluster_identifier = var.database_cluster_identifier } data "aws_subnet" "database" { id = var.database_connection_subnet_id } locals { database_engine = endswith(data.aws_rds_cluster.database.engine, "postgresql") ? "postgresql" : "mysql" database_jdbc_url = "jdbc:${local.database_engine}://${data.aws_rds_cluster.database.endpoint}:${data.aws_rds_cluster.database.port}/${var.database_name}" } resource "aws_glue_connection" "database" { name = "database-connection" description = "Aurora Database Connection" connection_type = "JDBC" connection_properties = { JDBC_CONNECTION_URL = local.database_jdbc_url JDBC_ENFORCE_SSL = var.database_force_ssl USERNAME = var.database_credentials.username PASSWORD = var.database_credentials.password # Management Console で作成するとなぜかこのプロパティが存在する KAFKA_SSL_ENABLED = false # SECRET_ID を指定すると Glue ジョブが必ずエラーになります(テスト接続は成功するのに) } # 作成したセキュリティグループを紐付ける physical_connection_requirements { subnet_id = data.aws_subnet.database.id availability_zone = data.aws_subnet.database.availability_zone security_group_id_list = [ aws_security_group.glue.id, # S3,ECR 用 data.aws_security_group.database.id, # DB 接続用 ] } }
ちなみに、後述する BigQuery Connection にセキュリティグループを紐付けても ECR との疎通はなぜかエラーになりました。なので、ECR と直接関係のないデータベースの Connection にセキュリティグループを紐付けています。おそらくデータベースの Connection はジョブノードのローカルで確立されるのに対し、BigQuery Connection はコンテナ上に確立されるからだと思いますが、Connection まわりのネットワーク仕様が複雑すぎて、もうちょっと抽象化してもらいたいものです。*3
BigQuery 用の AWS Glue Connection 作成
BigQuery の AWS Glue Connection を作成するのは、途中まで公式のブログに書いてあるとおりの手順です。
- AWS Secrets Manager にクレデンシャルの JSON コンテンツを格納する (Writeでは利用しない)
- Google BigQuery Connector for AWS Glue をサブスクライブする
- Google BigQuery Connector for AWS Glue を利用して Glue Connection を作成する
ここまでブログの手順どおりに実施します。
マーケットプレイスでサブスクライブを実行してアクティベートすると自動的にカスタム Connector が追加されます。ブログではそのあとに Connection の作成までやっていますが、terraform で作成できるので、その手順以降は実施しません。
BigQuery 接続用のクレデンシャルを登録
BigQuery 接続に必要なサービスアカウントのクレデンシャル JSON を Secrets Manager に登録します。
variable "bigquery_credentials_json" { sensitive = true } resource "aws_secretsmanager_secret" "bigquery_credentials" { name = "bigquery_credentials" } resource "aws_secretsmanager_secret_version" "bigquery_credentials" { secret_id = aws_secretsmanager_secret.bigquery_credentials.id secret_string = jsonencode({ credentials = base64encode(var.bigquery_credentials_json) }) }
後述しますが、上のクレデンシャルは BigQuery からの読み込み時にのみ利用され、書き込み時は S3 に同じ内容の JSON ファイルが別途必要です。そのため今回は利用しないのですが、Connection を作成するにあたり必要なのであらかじめ作成しています。
AWS Glue BigQuery Connection の作成
クレデンシャルが登録できたら Connection を作成します。CONNECTOR_URL は https://709825985650.dkr.ecr.us-east-1.amazonaws.com/amazon-web-services/glue/bigquery:0.24.2-glue3.0 となります。バージョンによって異なるので、ここの ECR URL に何を設定したらいいかわからない場合はマネジメントコンソールの Connector (ConnectionじゃなくてConnector) の詳細から確認してください。 match_criteria はマネジメントコンソールで作成したときに設定されていた値をそのまま入れています。一度マネジメントコンソールで作成したものを import した方が安全かもしれません。
resource "aws_glue_connection" "bigquery" { name = "bigquery-connection" description = "Google BigQuery Connection for AWS Glue 3.0" connection_type = "MARKETPLACE" match_criteria = ["Connection", "Google BigQuery Connector 0.24.2 for AWS Glue 3.0"] connection_properties = { CONNECTOR_TYPE = "Spark" CONNECTOR_CLASS_NAME = "com.google.cloud.spark.bigquery" CONNECTOR_URL = "https://709825985650.dkr.ecr.us-east-1.amazonaws.com/amazon-web-services/glue/bigquery:0.24.2-glue3.0" SECRET_ID = aws_secretsmanager_secret.bigquery_credentials.name } }
前述の通り、この Connection には VPC 設定は不要です。
AWS Glue Job 用の IAM ロール作成
今回のシナリオで AWS Glue Job に必要な権限は以下の 2 つです。
- BigQuery のクレデンシャルを読み取るための権限
- ECR からイメージを pull するための権限
Google BigQuery Connector は ECR のコンテナイメージとして提供されているため、ECR に対する権限が必要です。こちらはマネージドポリシーを利用します。なお、AWS Glue Job で必要とされる基本的な権限(assetsファイルの保存・読み込みやログ出力など)についてもマネージドポリシーが用意されているため、そちらを利用します。
variable "job_role_name" {} data "aws_iam_policy_document" "glue_assume_role_policy" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["glue.amazonaws.com"] } } } # BigQuery のクレデンシャルを読み取るための権限 data "aws_iam_policy_document" "get_describe_secret" { statement { sid = "GetDescribeSecret" actions = [ "secretsmanager:GetResourcePolicy", "secretsmanager:GetSecretValue", "secretsmanager:DescribeSecret", "secretsmanager:ListSecretVersionIds", ] resources = [aws_secretsmanager_secret.bigquery_credentials.arn] } } resource "aws_iam_role" "glue_job" { name = var.job_role_name description = "Allows Glue to call AWS services on your behalf." assume_role_policy = data.aws_iam_policy_document.glue_assume_role_policy.json } resource "aws_iam_role_policy" "get_describe_secret" { name = "get_describe_secret" role = aws_iam_role.glue_job.id policy = data.aws_iam_policy_document.get_describe_secret.json } # ECR からコンテナイメージを pull するための権限 resource "aws_iam_role_policy_attachment" "read-ecr" { role = aws_iam_role.glue_job.name policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly" } # Glue Job の基本的な権限(assetsファイルの保存・読み込みやログ出力など) resource "aws_iam_role_policy_attachment" "glue-service" { role = aws_iam_role.glue_job.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole" }
データソースを S3 や DynamoDB などの AWS サービスにする場合は、それらを読み取るための権限が必要です。今回はデータソースが Aurora なので不要です。
AWS Glue Job 作成
ここまでできたらようやくジョブの作成です。Google BigQuery Connector for AWS Glue の Usage には BigQuery への書き込みについて(2022/12現在)以下の記述があります。
You need to upload credentials.json to your S3 bucket, and set the file path in Referenced files path.
前述しましたが、BigQuery への Write では Read と違って Secrets Manager を使ってくれません。別途 S3 に JSON ファイルを置かないといけないという謎仕様です。
また、
Private key * spark.hadoop.fs.gs.auth.service.account.email= [your-email-extracted-from-service_account_json_file] * spark.hadoop.fs.gs.auth.service.account.private.key.id= [your-private-key-id-extracted-from-service_account_json_file] * spark.hadoop.fs.gs.auth.service.account.private.key= [your-private-key-body-extracted-from-service_account_json_file] You can set these Spark configurations in one of following ways. * The param --conf of Glue job parameters * The job script using SparkConf
とあるのですが、ジョブパラメータは Key-Value 形式なので --conf を複数個は設定できません*4。そのため、必然的に後者の The job script using SparkConf を選択することになります。
Python スクリプトを直接編集することになるのですが、ゼロから実装するのではなく Glue Studio の Visual Editor で作成したジョブのスクリプトを編集し、terraform に載せる方針でいきます。
Visual Editor でジョブを作成
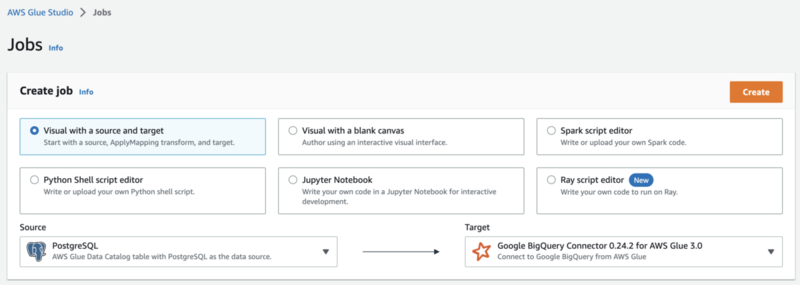
Glue Studio の [Jobs] メニューで Visual with a source and target を選択し、[Source] にデータベースを*5、[Target] に Google BigQuery Connector 0.24.2 for AWS Glue 3.0 を選択して [Create] ボタンをクリックします。
今回のシナリオではデータスキーマの変換は行わないため、ApplyMappingのアクションノードは削除します。
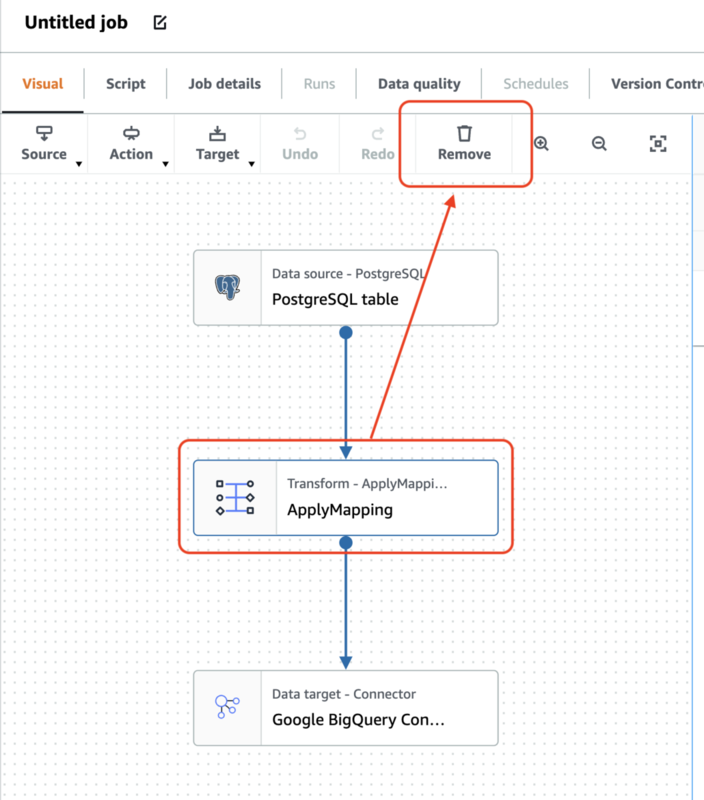
Source ノードを選択し、[Data source properties - JDBC] タブで作成済みの JDBC Connection を選択、テーブル名を スキーマ名.テーブル名 の形式で指定します。なお、ここで指定したテーブル名はあとで terraform により上書きされるため、UI 上ではダミーのテーブル名で問題ありません。
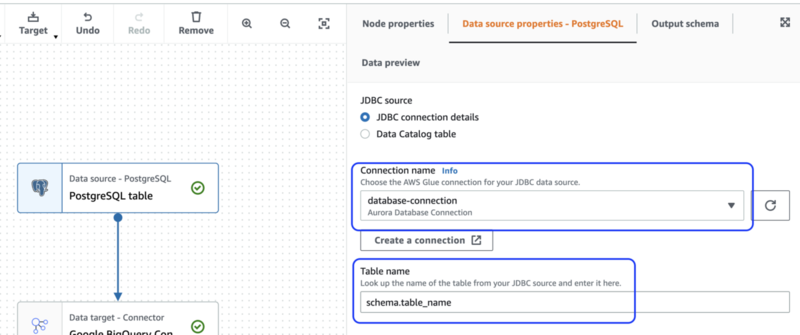
同様に、Target ノードを選択し、[Data target properties] タブで書き込み時に必須のプロパティ*6である parentObject, temporaryGcsBucket, table を設定します。ここもあとで書き換わるためダミーの値で問題ありません。
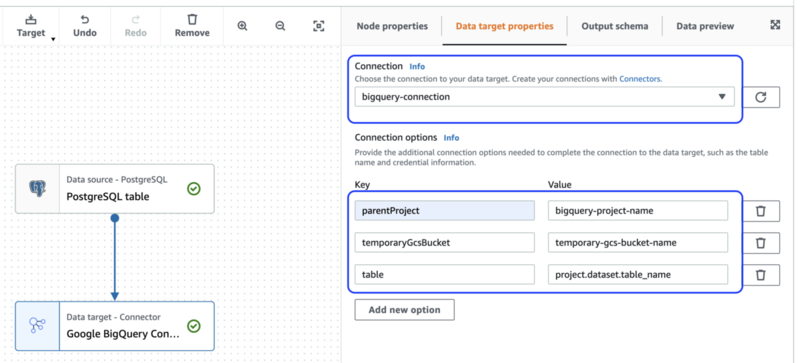
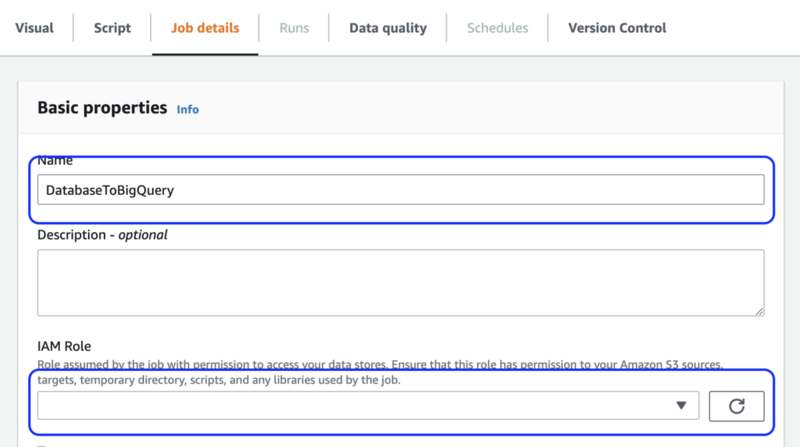
最後に、[Job details] タブでジョブに適当な名前をつけて、IAM ロールに先ほど作成したジョブロールを選択し、[Save]ボタンをクリックします。ジョブ名はリソース ID になるため、後から変更はできません。*7
画面の通りに設定した結果、出力されるスクリプトは以下のとおりとなります。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.dynamicframe import DynamicFrame def directJDBCSource( glueContext, connectionName, connectionType, database, table, redshiftTmpDir, transformation_ctx, ) -> DynamicFrame: connection_options = { "useConnectionProperties": "true", "dbtable": table, "connectionName": connectionName, } if redshiftTmpDir: connection_options["redshiftTmpDir"] = redshiftTmpDir return glueContext.create_dynamic_frame.from_options( connection_type=connectionType, connection_options=connection_options, transformation_ctx=transformation_ctx, ) args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node PostgreSQL table PostgreSQLtable_node1 = directJDBCSource( # <= (注) ここのノード名は毎回異なります glueContext, connectionName="database-connection", connectionType="postgresql", database="database_name", table="schema.table_name", redshiftTmpDir="", transformation_ctx="PostgreSQLtable_node1", ) # Script generated for node Google BigQuery Connector 0.24.2 for AWS Glue 3.0 GoogleBigQueryConnector0242forAWSGlue30_node3 = ( # <= (注) ここのノード名は毎回異なります glueContext.write_dynamic_frame.from_options( frame=PostgreSQLtable_node1, connection_type="marketplace.spark", connection_options={ "parentProject": "bigquery-project-name", "temporaryGcsBucket": "temporary-gcs-bucket-name", "table": "project.dataset.table_name", "connectionName": "bigquery-connection", }, transformation_ctx="GoogleBigQueryConnector0242forAWSGlue30_node3", ) ) job.commit()
Python スクリプトの編集
このスクリプトはコピーしてローカルファイルとして terraform のディレクトリに保存します。ただし、このままだと BigQuery に接続するためのクレデンシャルが見つからずエラーになるため、以下の修正を適用します。
--- script.orig.py 2022-12-06 23:39:44.000000000 +0900 +++ script.writable.py 2022-12-06 23:42:28.000000000 +0900 @@ -2,6 +2,7 @@ from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext +from pyspark.conf import SparkConf from awsglue.context import GlueContext from awsglue.job import Job from awsglue.dynamicframe import DynamicFrame @@ -32,9 +33,13 @@ transformation_ctx=transformation_ctx, ) +conf = SparkConf() +conf.set("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem") +conf.set("spark.hadoop.fs.gs.auth.service.account.enable", "true") +conf.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "credentials.json") args = getResolvedOptions(sys.argv, ["JOB_NAME"]) -sc = SparkContext() +sc = SparkContext.getOrCreate(conf=conf) glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext)
spark.hadoop.google.cloud.auth.service.account.json.keyfile に指定する credentials.json は後述の S3 にアップロードしたクレデンシャルファイルの basename です。AWS Glue の --extra-files オプションで S3 のパスを指定することで、ジョブノードのワーキングディレクトリに自動的に展開されます。
さらにテーブル名などを terraform の templatefile 関数で書き換え可能なようにプレースホルダに置き換えます。これ(プレースホルダへの置き換え)は今回のシナリオで必須ではありませんが、実際に運用する際にはこういった実装になると思われます。
--- script.writable.py 2022-12-06 23:42:28.000000000 +0900 +++ script.template.py 2022-12-06 23:41:45.000000000 +0900 @@ -36,7 +36,7 @@ conf = SparkConf() conf.set("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem") conf.set("spark.hadoop.fs.gs.auth.service.account.enable", "true") -conf.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "credentials.json") +conf.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "${credentials_filename}") args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext.getOrCreate(conf=conf) @@ -48,10 +48,10 @@ # Script generated for node PostgreSQL table PostgreSQLtable_node1 = directJDBCSource( glueContext, - connectionName="database-connection", - connectionType="postgresql", - database="database_name", - table="schema.table_name", + connectionName="${database_connection_name}", + connectionType="${database_connection_type}", + database="${database_name}", + table="${database_table_name}", redshiftTmpDir="", transformation_ctx="PostgreSQLtable_node1", ) @@ -62,10 +62,10 @@ frame=PostgreSQLtable_node1, connection_type="marketplace.spark", connection_options={ - "parentProject": "bigquery-project-name", - "temporaryGcsBucket": "temporary-gcs-bucket-name", - "table": "project.dataset.table_name", - "connectionName": "bigquery-connection", + "parentProject": "${bigquery_project_id}", + "temporaryGcsBucket": "${temporary_gcs_bucket_name}", + "table": "${bigquery_table_name}", + "connectionName": "${bigquery_connection_name}", }, transformation_ctx="GoogleBigQueryConnector0242forAWSGlue30_node3", )
最終的な Python コードテンプレートはこちら
- script.template.py
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from pyspark.conf import SparkConf from awsglue.context import GlueContext from awsglue.job import Job from awsglue.dynamicframe import DynamicFrame def directJDBCSource( glueContext, connectionName, connectionType, database, table, redshiftTmpDir, transformation_ctx, ) -> DynamicFrame: connection_options = { "useConnectionProperties": "true", "dbtable": table, "connectionName": connectionName, } if redshiftTmpDir: connection_options["redshiftTmpDir"] = redshiftTmpDir return glueContext.create_dynamic_frame.from_options( connection_type=connectionType, connection_options=connection_options, transformation_ctx=transformation_ctx, ) conf = SparkConf() conf.set("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem") conf.set("spark.hadoop.fs.gs.auth.service.account.enable", "true") conf.set("spark.hadoop.google.cloud.auth.service.account.json.keyfile", "${credentials_filename}") args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext.getOrCreate(conf=conf) glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node PostgreSQL table PostgreSQLtable_node1 = directJDBCSource( glueContext, connectionName="${database_connection_name}", connectionType="${database_connection_type}", database="${database_name}", table="${database_table_name}", redshiftTmpDir="", transformation_ctx="PostgreSQLtable_node1", ) # Script generated for node Google BigQuery Connector 0.24.2 for AWS Glue 3.0 GoogleBigQueryConnector0242forAWSGlue30_node3 = ( glueContext.write_dynamic_frame.from_options( frame=PostgreSQLtable_node1, connection_type="marketplace.spark", connection_options={ "parentProject": "${bigquery_project_id}", "temporaryGcsBucket": "${temporary_gcs_bucket_name}", "table": "${bigquery_table_name}", "connectionName": "${bigquery_connection_name}", }, transformation_ctx="GoogleBigQueryConnector0242forAWSGlue30_node3", ) ) job.commit()
Python スクリプトを S3 に保存
このテンプレートファイルに値を埋め込み、S3 バケットに配置します。ジョブに設定した IAM ロールが読み取れる場所に保存する必要があるのですが、今回は Glue Studio でジョブを作成した際に自動的に作成される aws-glue-assets-<account>-<region> という S3 バケットを利用します。
このバケットのオブジェクトは、ロールにアタッチしているマネージドポリシーの AWSGlueServiceRole で参照可能なため、追加のポリシー設定は不要です。Glue Studio で作成した場合のデフォルトのスクリプト置き場でもあります。
variable "job_name" {} variable "source_table_name" {} variable "bigquery_project_id" {} variable "temporary_gcs_bucket_name" {} variable "destination_table_name" {} variable "credentials_filename" { default = "credentials.json" } data "aws_region" "current" {} data "aws_caller_identity" "current" {} locals { glue_assets_s3_bucket = "aws-glue-assets-${data.aws_caller_identity.current.account_id}-${data.aws_region.current.name}" } data "aws_s3_bucket" "assets" { bucket = local.glue_assets_s3_bucket } resource "aws_s3_object" "script" { bucket = data.aws_s3_bucket.assets.bucket key = "scripts/${var.job_name}.py" # テンプレートファイルは `script.template.py` というファイル名でローカル保存されているものとする content = templatefile("${path.module}/script.template.py", { database_connection_name = aws_glue_connection.database.name database_connection_type = local.database_engine database_name = var.database_name database_table_name = var.source_table_name bigquery_connection_name = aws_glue_connection.bigquery.name bigquery_project_id = var.bigquery_project_id temporary_gcs_bucket_name = var.temporary_gcs_bucket_name bigquery_table_name = var.destination_table_name credentials_filename = var.credentials_filename }) }
プレースホルダの中身は terraform apply 時に確定することに注意してください。現状、AWS Glue に変数を持たせる機能はありません。
S3 に BigQuery のクレデンシャルを格納
Glue Job で BigQuery に書き込みするためのクレデンシャルファイルを S3 オブジェクトとして用意します。前述のとおり、AWS Glue の --extra-files オプションでこのファイルの S3 パスを指定し、ジョブノードのワーキングディレクトリに自動的に展開されるようにします。
こちらはセキュアでなければいけないため、別途 S3 バケットが作成済みであるとし、コンテンツの中身は Secrets Manager 作成時に利用した変数をそのまま使います。
variable "credentials_s3_bucket_name" {} variable "credentials_s3_bucket_prefix" { default = "" } data "aws_s3_bucket" "credentials" { bucket = var.credentials_s3_bucket_name } resource "aws_s3_object" "bigquery_credentials" { bucket = data.aws_s3_bucket.credentials.bucket key = "${var.credentials_s3_bucket_prefix}${var.credentials_filename}" content = var.bigquery_credentials_json } data "aws_iam_policy_document" "read_credentials_json" { statement { sid = "ReadCredentialsJson" actions = ["s3:GetObject"] resources = [ "${data.aws_s3_bucket.credentials.arn}/${aws_s3_object.bigquery_credentials.id}" ] } } # 保存したファイルの読み取り権限を IAM ロールに付与 resource "aws_iam_role_policy" "read_credentials_json" { name = "read_credentials_json" role = aws_iam_role.glue_job.id policy = data.aws_iam_policy_document.read_credentials_json.json }
Glue Job の作成
最後に、Glue Job の terraform を実装します。ただし、このジョブはすでに Glue Studio で作成済みのため、terraform import で state を取り込んだあと、差分を terraform apply します。
resource "aws_glue_job" "main" { name = var.job_name role_arn = aws_iam_role.glue_job.arn glue_version = "3.0" # 必須(ないと 0.9 になる) connections = [ aws_glue_connection.database.name, aws_glue_connection.bigquery.name, ] execution_class = "STANDARD" worker_type = "G.1X" max_retries = 0 # デフォルトは 3 number_of_workers = 2 # デフォルトは 10 command { name = "glueetl" script_location = "s3://${aws_s3_object.script.bucket}/${aws_s3_object.script.id}" } default_arguments = { "--extra-files" = "s3://${data.aws_s3_bucket.credentials.bucket}/${aws_s3_object.bigquery_credentials.id}" # 以降のパラメータは Visual Editor で作成した際のデフォルト値 "--TempDir" = "s3://${data.aws_s3_bucket.assets.bucket}/temporary/" "--enable-continuous-cloudwatch-log" = true "--enable-glue-datacatalog" = true "--enable-job-insights" = true "--enable-metrics" = true "--enable-spark-ui" = true "--job-bookmark-option" = "job-bookmark-enable" "--job-language" = "python" "--spark-event-logs-path" = "s3://${data.aws_s3_bucket.assets.bucket}/sparkHistoryLogs/" } }
ポイントは --extra-files でクレデンシャルファイルを指定していることです。その他のパラメータは Visual Editor で作成したときのままにしています。
ジョブの実行
作成した Glue Job を Management Console で [Run] するとジョブが実行されます。ジョブの開始は長いときだと 1 分くらいかかります。 ジョブのステータスが Succeeded になり、BigQuery のコンソールでテーブルが作成されていれば成功です。
以下について、時間がなかったので確認できていません。
- BigQuery のデータは洗い替えなのか、追加書き込みなのか、キーによるマージが可能なのか
- ワイルドカードテーブルの作成はどうするか(
datetime.strftimeでできそう) - ETL の
Tの部分の実装はどうなるのか - Spark UI の表示など
ちなみに Crawler で作成した Data Catalog をデータソースとした ETL ジョブは普通に成功しました。
ソースコード評価時に発生したエラーたち
BigQuery Connection のプロビジョニングエラー
ECR の GetAuthorizationToken が timeout する。これは ECR に対するアウトバウンドが許可されていなかったため。セキュリティグループに 0.0.0.0/0 のアウトバウンドを追加したことで解消。
2022-12-06 03:10:54,541 - __main__ - INFO - Glue ETL Marketplace - Requesting ECR authorization token for registryIds=709825985650 and region_name=us-east-1.
Traceback (most recent call last):
File "/home/spark/.local/lib/python3.7/site-packages/urllib3/connection.py", line 160, in _new_conn
(self._dns_host, self.port), self.timeout, **extra_kw
File "/home/spark/.local/lib/python3.7/site-packages/urllib3/util/connection.py", line 84, in create_connection
raise err
File "/home/spark/.local/lib/python3.7/site-packages/urllib3/util/connection.py", line 74, in create_connection
sock.connect(sa)
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/spark/.local/lib/python3.7/site-packages/botocore/httpsession.py", line 353, in send
ググってみたら以下のスレッドが出てきて、見当違いで数時間ハマった。
https://stackoverflow.com/questions/69879490/etl-connector-not-loading-in-aws
Database Connection のプロビジョニングでもエラー
以下のエラー自体は Database Connection のクレデンシャルを Secrets Manager から Username/Password に変更したら解消されたのだが、根本的な原因は不明。secretsmanager API に関係してそうだけど、Connection のネットワーク仕様が複雑で発生条件の切り分けが大変すぎて追ってません。
22/12/06 06:51:28 ERROR ProcessLauncher: Error from Python:Traceback (most recent call last):
File "/tmp/WriteToBigQuery.py", line 56, in <module>
transformation_ctx="PostgreSQLtable_node",
File "/tmp/WriteToBigQuery.py", line 33, in directJDBCSource
transformation_ctx=transformation_ctx,
File "/opt/amazon/lib/python3.6/site-packages/awsglue/dynamicframe.py", line 770, in from_options
format_options, transformation_ctx, push_down_predicate, **kwargs)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/context.py", line 232, in create_dynamic_frame_from_options
source = self.getSource(connection_type, format, transformation_ctx, push_down_predicate, **connection_options)
File "/opt/amazon/lib/python3.6/site-packages/awsglue/context.py", line 105, in getSource
makeOptions(self._sc, options), transformation_ctx, push_down_predicate)
File "/opt/amazon/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1305, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/opt/amazon/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 111, in deco
return f(*a, **kw)
File "/opt/amazon/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 328, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o97.getSource.
: java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:349)
at scala.None$.get(Option.scala:347)
at com.amazonaws.services.glue.util.DataCatalogWrapper.$anonfun$getJDBCConf$1(DataCatalogWrapper.scala:218)
at scala.util.Try$.apply(Try.scala:209)
at com.amazonaws.services.glue.util.DataCatalogWrapper.getJDBCConf(DataCatalogWrapper.scala:209)
at com.amazonaws.services.glue.GlueContext.applyConnectionProperties(GlueContext.scala:1000)
at com.amazonaws.services.glue.GlueContext.getSourceInternal(GlueContext.scala:913)
at com.amazonaws.services.glue.GlueContext.getSource(GlueContext.scala:776)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:750)
おわりに
We are hiring
エムスリーではデータ活用で日本の医療に貢献したいメンバーを募集中です! カジュアル面談も随時募集していますので、詳しくは以下をご覧ください!
*1:spark-bigquery-connector 0.24.2
*2:ただし、その場合は IAM ポリシーの追加が必要です
*3:おかげで 20 時間くらい溶けた
*4:試しに複数指定してみたらエラーになりました
*5:画面ではPostgreSQL
*6:https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.24.2#properties
*7:terraform の場合、再作成になります