 【 デジスマチーム ブログリレー1日目】
【 デジスマチーム ブログリレー1日目】
こんにちは。
デジスマチームの山本です。 クリニック向けDXサービスであるデジスマ診療のWeb フロントエンド・バックエンド・インフラを担当しています。
今回は先日AWSから発表されたaws-advanced-jdbc-wrapperについて紹介します。
- はじめに
- AWS Advanced JDBC Wrapper
- フェイルオーバーとは
- これまでのフェイルオーバー対策
- AWS Advanced JDBC Wrapperを利用した場合のフェイルオーバー対策
- 導入方法
- 実際に動かしてみた
- まとめ
- We are hiring!!
はじめに
こちらの記事は、先日エムスリー社内LT会であるTechTalkで発表した内容で、動画でも視聴いただけます。
AWS Advanced JDBC Wrapper
AWS Advanced JDBC WrapperとはAWSが開発している、既存のJDBCをラップし、AWS上のAuroraのようなクラスター化されたデータベースをより安全に、便利に利用できるようにするドライバーです。
メインとしてはフェイルオーバー時のダウンタイムを最小限に留める機能を提供しつつ、プラグイン形式でSecret Managerからのクレデンシャルの取得やIAM認証への対応なども有効にできるようになっています。JDBCのラッパーとして実装されているため、AWS SDKを直接使用するようにアプリケーションコードを変更する手間が必要なく、JDBCの接続部分の設定のみを変更するだけで導入できるというのも魅力の1つです。
現在対応しているのはPostgreSQL JDBC Driverのみですが、MySQLやMariaDBへの展開も検討されているそうです。一方で、AWSはMySQL向けのJDBC Driver for MySQLも開発しており、フェイルオーバー高速化などAdvanced JDBC Wrapperの一部の機能はそちらですでに提供されていました。おそらく後発のAdvanced JDBC Wrapperに統一していく見込みなのだとは思いますが、この辺りはよくわかりません。
提供Plugin
前述のように、当ライブラリはプラグイン形式で多くの機能を提供しています。ここではいくつか抜粋して紹介します
- Failover Connection Plugin
- フェイルオーバー改善用(後述)
- Host Monitoring Connection Plugin
- フェイルオーバー改善用(後述)
- IAM Authentication Connection Plugin
- Aurora IAM認証をJDBC側で透過的に実現するプラグイン
- IAMでのDB接続はこれまでひと手間必要だったので大変便利に利用できるようになったと思います
- AWS Secrets Manager Connection Plugin
- Secret ManagerからのDB接続クレデンシャル取得を実現するプラグイン
- Secret Managerでのローテションを設定している場合にはコンテナの再起動をせずに更新ができる。また、開発環境等でAWS上のDBにつなげる場合に、パスワードを共有せずにIAM権限の付与だけで実現できるのも便利になりそうです。
この他にも、開発ブランチではConnection#setReadOnlyでの動的な向き先の変更に対応するRead-Write Splitting Pluginなども追加されており、積極的に開発が行われているようです。
フェイルオーバーとは
AWS Auroraにおけるフェイルオーバーとは、 マルチインスタンスなAurora Clusterにおいて、Writerインスタンスに何らかの問題が生じたときに、ReaderインスタンスをWriterインスタンスに昇格し、新しいクエリに関しては昇格したインスタンスで実行するようにする、という一連の処理を指します。(広義にはReaderインスタンスの障害時に別のReader/Writerにトラフィックを移行することも指します) フェイルオーバーは単なるOOMのようなデータベースの再起動の他にも、インスタンスサイズの変更や、(まれに)メンテナンスウィンドウ内でも実行されることがあり、いかにフェイルオーバーを乗り越えるか、は安定したサービスの提供に必要不可欠な要素となっています。
新しいクエリを昇格したインスタンスで実行する、というのはAuroraのクラスターエンドポイントによって実現されています。 これはクラスター単位での、Writer用・Reader用のホストが設定されており、そのDNS解決先がフェイルオーバーの前後で変化するという仕組みです。
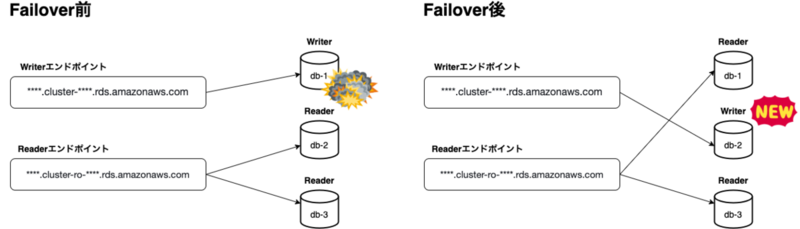
通常このフェイルオーバー処理自体は数分、早いときには数十秒で終了しますが、利用側のクライアントによってはより長く数分アクセスができなくなる、あるいはwrite系クエリが実行できなくなる、という問題が生じます。なぜエラーになるか、を分解すると以下の3つに分類できます。
- インスタンス昇格/降格処理
- Reader -> Writerまたはその逆への変更中はアクセスできない時間があります。
- コネクションプーリング
- Reader/Writerで別のコネクションプールを利用している場合、WriterがReaderに降格した場合でもコネクションプールが残り、ReaderとなっているのにWrite系のクエリが実行されてエラーになる
- DNSキャッシュ
- 上記のクラスターエンドポイントDNSレコードはTTLが5秒という短い時間が設定されていますが、OSやJVMの設定によってはより長い時間キャッシュされることがあります。Writerに接続しようとしてDNSキャッシュに残っていた現ReaderのIPに接続してしまった場合、コネクションプール問題と同じ問題が生じます。
1.に関しては適切なリトライ、2.に関してはエラーが発生した場合のコネクションの破棄、3.に関してはDNSキャッシュを十分に短くする、あるいはDNSに頼らない他の方法を使う、ということが考えられます。
これまでのフェイルオーバー対策
上記のような問題に関してこれまでもいくつかの選択肢がありました。 これ以降の項に関しては、特に断りがない場合Aurora PostgreSQL + Javaが対象になります。
- 各種設定の見直し。代表的なのは以下のようなものかと思います
- DNSキャッシュ時間の設定
networkaddress.cache.ttl,networkaddress.cache.negative.ttlを設定する
- コネクション作成タイミングでReader/Writerを判定し、適切なインスタンスを選択するようにする
- こちらはいくつかの実装パターンが有るようです
- AWS公式ドキュメントにあるように、インスタンスホストを一覧化し
targetServerTypeでインスタンスの選択をPostgreSQL JDBC Driverに委ねる。
- AWS公式ドキュメントにあるように、インスタンスホストを一覧化し
- HikariCPの
connectionInitSqlでSHOW transaction_read_only等を実行して、コネクション作成をリトライさせる
- こちらはいくつかの実装パターンが有るようです
- HikariCPの
hikari.max-lifetime等で、コネクションプール側のコネクション保持期間を短く設定する
- DNSキャッシュ時間の設定
- Amazon RDS Proxy
1.に関してはデフォルトで有効な設定ではないこと、フェイルオーバーという比較的レアな事象でしか発生しないことから、特に設定をせずに利用されている方も多いのではないでしょうか。また、1.c のようにコネクションの再利用性を下げるような変更は、通常時のパフォーマンス低下を招くため、発生確率を鑑みてあえて採用しないという選択肢もあったかと思われます。 2.に関してはインフラ側の追加コンポーネントが必要なこと、あるいはPrepared Statement等の「ピン留め」現象によってRDS Proxyが適さないアプリケーションも多く、採用しない・できないこともあるかと思います。
これらの問題に関して、Aurora MySQLの場合はすでにMariaDB Connector/JやAWS謹製のAWS JDBC Driver for MySQLといったJDBCドライバーでの解決策が(2015年ころから…!!) ありましたが、PostgreSQLに関しては僕の知る限り存在していませんでした。
今回のAWS Advanced JDBC WrapperはこれをAurora PostgreSQLでも解決しようということで、PostgreSQLを優先的に対応したものと思われます。
AWS Advanced JDBC Wrapperを利用した場合のフェイルオーバー対策
ではAWS Advanced JDBC Wrapperではどのように問題を解決しているのでしょうか。
これには複数のプラグインが連携することで実現していることがわかります
Failover Connection Plugin
このプラグインは、コネクションのラッパーを作ることで、物理的なコネクションと論理的なコネクションの分離を行います。 論理的には1つのコネクションを利用しつつも、エラーが発生したときに内部的には新しいコネクションに差し替える、ということを自動的に行い、アプリケーションレベルでは単に処理時間のかかったJDBCコール(クエリ実行)に見えるということです。

新しいコネクションを貼るときに最新のプライマリインスタンスを選択する必要がありますが、
- 稼働中のプライマリインスタンスから定期的にホストの一覧を取得する
- (フェイルオーバー発生後)キャッシュされていたホストの一覧から一旦アクティブなリードレプリカに接続する
- リードレプリカから1.と同様にホストの一覧を取得し、プライマリインスタンスが確定したらそちらに接続する
という処理を行っているようです。これによってDNSよりもより確実・高速なフェイルオーバーを実現しています。
Host Monitoring Connection Plugin
このプラグインは、実行しようとしているクエリと並行してインスタンスの稼働状態を監視するタスクを実行することで、フェイルオーバーが発生した場合にはクエリを途中でキャンセルできます。キャンセルされた場合はFailover Connection Pluginが処理を新しいコネクションで再実行する、という組み合わせのようです。インスタンスが応答していないのにクエリの終了を待ち続ける、というのを防いでくれるということのようです。
このプラグインは、長時間実行されるようなクエリがない場合にはメリットが薄く、TCP Keep Aliveでも代替できリソースの消費もあるため、常に有効にしてよいというプラグインではなさそうです。
導入方法
AWS Advanced JDBC WrapperはJDBCドライバとして提供されているため、導入も簡単です。
- 依存先への追加
- 接続するJDBC URLの変更、利用するプラグインの指定
- (Connection Poolを利用する場合) 例外設定の追加
- (IAM認証 / Secret Managerとの連携を利用する場合) 実行IAM Roleへの権限の付与
基本的には以上の4ステップのみで利用を開始できます。
Gradle(Kotlin)での依存先の追加
implementation("software.amazon.jdbc:aws-advanced-jdbc-wrapper:1.0.1")
Spring Boot + HikariCPでの設定例
spring: datasource: writer: jdbc-url: jdbc:aws-wrapper:postgresql://****-****.rds.amazonaws.com:5432/****?wrapperPlugins=failover,efm exception-override-class-name: software.amazon.jdbc.util.HikariCPSQLException reader: jdbc-url: jdbc:aws-wrapper:postgresql://****-ro-****.rds.amazonaws.com:5432/****?wrapperPlugins=failover,efm exception-override-class-name: software.amazon.jdbc.util.HikariCPSQLException
ポイントは、
- JDBC URLの先頭部分に
aws-wrapper:を追加すること - クエリパラメータで利用するプラグインをコンマ区切りで指定すること
- HikariCPがフェイルオーバー時にリトライできるよう、
exception-override-class-nameを指定すること
の3点です。
実際に動かしてみた
以下のような環境で実験してみます。
- Aurora PostgreSQL db.t4g.medium * 2
- advanced-jdbc-wrapper:1.0.1
- 実は直近でDNS反映遅れへの対応が改善しているのでこれ以降のバージョンを利用することをおすすめします
- Spring Boot (2.6.6) + HikariCP (4.0.3) + Exposed (0.41.1)
- 以下の二種類のAPIエンドポイント
- Write: Writerエンドポイントに対してUPDATEを実行
- Read: Readerエンドポイントに対してSELECTを実行
- AWSコンソールから手動でフェイルオーバーを実行
何も設定しない場合
まずは何も設定していない場合の挙動です。
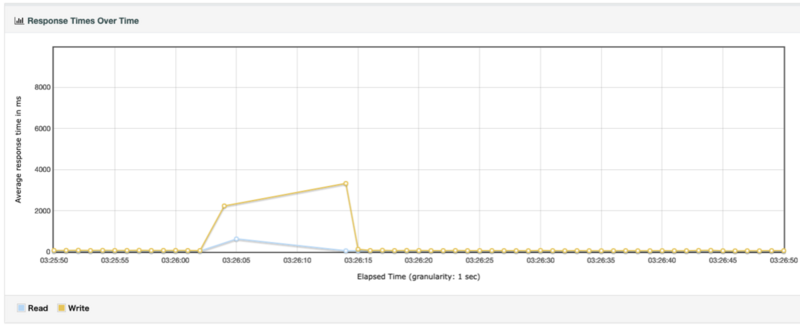 まずはレイテンシの推移ですが15秒程度影響はあるもののそれ以外は影響がないことがわかります。
まずはレイテンシの推移ですが15秒程度影響はあるもののそれ以外は影響がないことがわかります。
 一方でエンドポイントごとの成功・失敗リクエスト数は、フェイルオーバー後はReadは成功しているもののWriteに関してはエラーが発生していることがわかります。
一方でエンドポイントごとの成功・失敗リクエスト数は、フェイルオーバー後はReadは成功しているもののWriteに関してはエラーが発生していることがわかります。
アプリケーション側では
cannot execute UPDATE in a read-only transaction
のエラーが出ており、おそらくDNSキャッシュの影響で旧Writerインスタンスを新しいWriterだと勘違いして、コネクションを作成し、それを使い続けている状態です。 こうなるとコネクションが破棄されるまで(max-lifetime分)エラーが出続けるので、エラーが長期化してしまっています。
設定後
一方でAWS Advanced JDBC Wrapperの利用後のレイテンシ・リクエスト数は


のようになっており、大幅にエラー数が削減していることがわかります。(実験の経緯的に2回フェイルオーバーさせて1回目のグラフなので赤い線が伸びてしまっていますが、フェイルオーバー時点でのみエラーが発生しています)
レイテンシの悪化期間は長くなっているように見えますが、この期間のトレースを見ると。
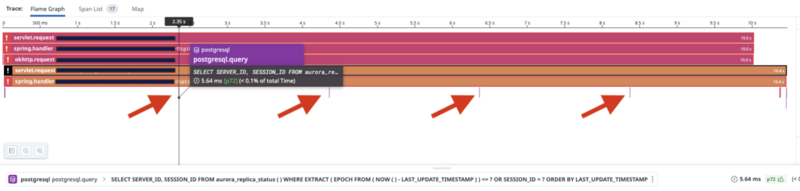
このように aurora_replica_status() を定期的に監視して、新しいWriterが準備できるのを待つ、という挙動になっているようです。
この辺りのリトライ間隔や、どこまで待つかは設定で変更できます。
まとめ
今回はAWS Advanced JDBC Wrapperの紹介をしました。 比較的簡単に高速なフェイルオーバーが実現できるということで興味がある人も多いのではないでしょうか。
最後に懺悔しますが、私が開発に参加しているデジスマ診療では hikari.max-lifetime を短く制限することでこれまでフェイルオーバーに対応していました。
この方法では、新規コネクションが増えてしまうことで、コネクションの作成や、Prepared Statementの作成にコストがかかっており、DBの負荷になっています。
次回以降の記事では、デジスマ診療に実際に導入したときの効果について共有できればと思います。
We are hiring!!
私のいるデジスマ診療チームでは、日本のクリニック診療をDX化するデジスマ診療を開発しています! 開発チームの紹介資料もありますのでぜひご覧ください!
エムスリーではエンジニアを絶賛募集中です。チーム紹介資料を読んで興味を持たれた方も、そうでない方も是非ご応募ください!