この記事はエムスリーAdvent Calendar 2023とMLOps Advent Calendar 2023の12日目の記事です。
AI・機械学習チームの北川です。 最近は猫のかまってアピールがすごすぎて、よく仕事の邪魔されます。

現在AI・機械学習チームではMLのバッチをGoogle Kubernetes Engine(GKE)上で運用しています。 現在数えてみたところ240個以上のバッチがGKE上で動いているようです。
AI・機械学習チームでは2019年頃から約4年ほどGKE上でMLバッチを運用しています。 その間にコストの最適化や安定したバッチの運用などに力を入れてきました。 この記事では、主にスケールインとコスト最適化について説明しようと思います。
チームのMLについて全体を把握したい場合は以下の記事が詳しいです。
GKEの用語の確認
まず最初にGKE(Kubernetes)の用語について確認をしていきます。 Kubernetesがわかる方は飛ばして次に行ってください。
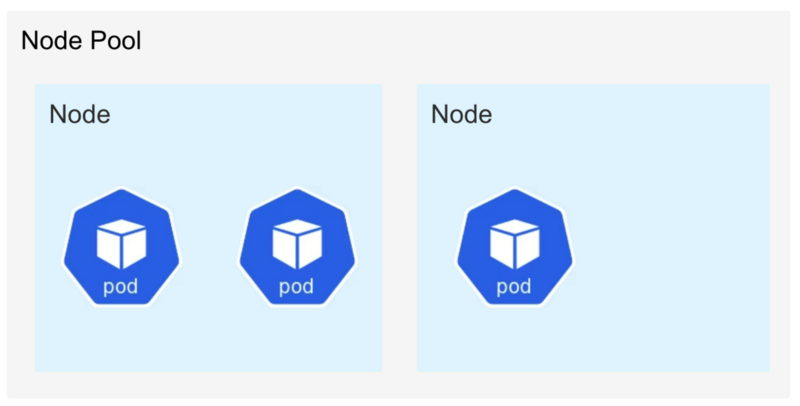
- Pod
- Node
- Node Pool
Pod
Podは1つまたは複数のコンテナのグループを表すKuberntesのリソースです。 複数のContainerを起動できるので、docker composeのようなものと認識すると分かりやすいかもしれません。 ストレージやネットワークの共有リソースを持つので、各コンテナ間で通信したり、データを共有したりすることが出来ます。
Node
Nodeは1つのVMまたは物理的なマシンを表します。 各Nodeには複数のPodが配置されます。 GKEのStandardモードではNodeは一つのCompute Engineを表します。 Amazon Elastic Kubernetes Service(EKS)でもNodeはEC2インスタンスを表すようです。
Podでは各コンテナに対してCPUやメモリの下限や上限を指定することが出来ます。 メモリの下限を設定するとKubernetesのスケジューラは、その情報を利用してどのNodeにどのPodを配置するかを決定します。
Node Pool
Node Poolはクラスタ内で同じ構成を持つNodeのグループです。 新たなPodを作成しようとした時にCPUやメモリなどリクエストが足りない場合、Node PoolはNodeをスケールアウトしてくれます。 逆にNodeが余っている場合はNodeをスケールインしてくれます。
GKEのStandardモードやEKSはNode単位で課金されます。 そのため自動でスケールインしてくれる機能はとても嬉しいものです。
KubernetesのEvictionについて
KubernetesにはEvictionという機能があります。 これはNodeのリソースが余っていた場合にPodを別のNodeに退避させ、Nodeをスケールインしてくれるという機能です。 これによって料金の課金をある程度抑えてくれます。
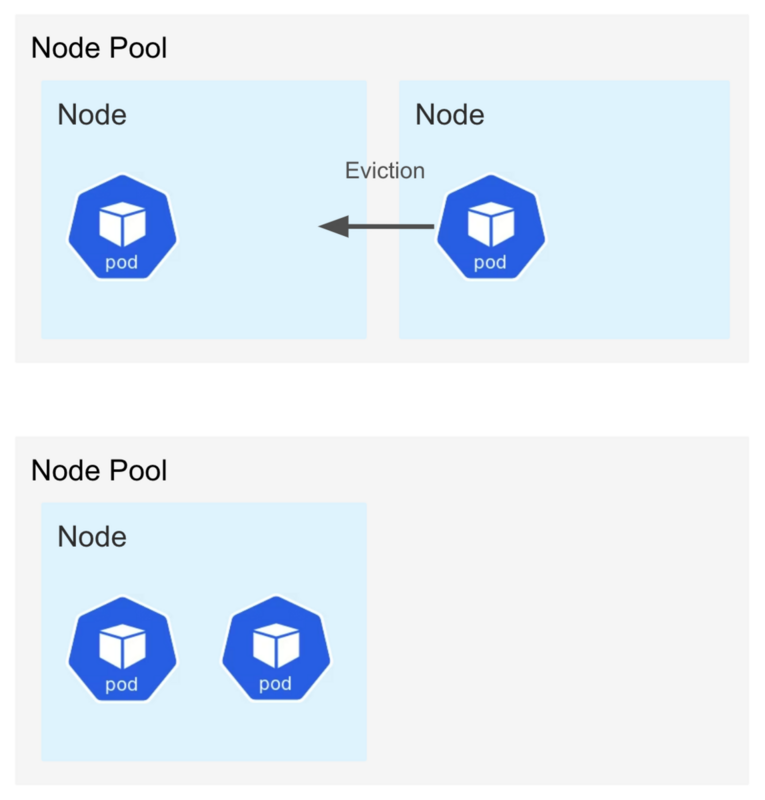
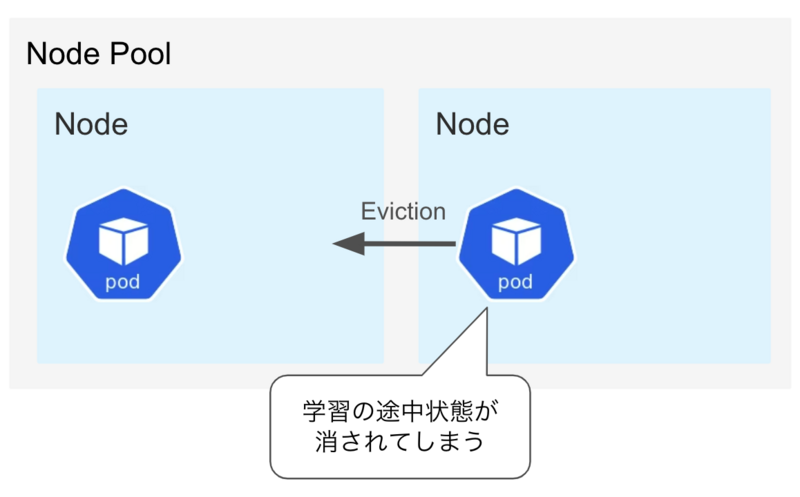
しかし、この機能はMLのバッチのような長時間計算して、その状態を保持する必要がある場合には致命的となります。 近頃のMLバッチはパイプラインライブラリなどを利用して、バッチ全体を複数のステップに分割して各ステップをキャッシュするというようなものが多いと思います。 AI・機械学習チームでもgokartというパイプラインライブラリを利用しています。 しかし、実際に計算する部分は数時間かかるものがあり、その実行中にEvictionが走るとそれまでに計算した状態ごと消えてしまいます。
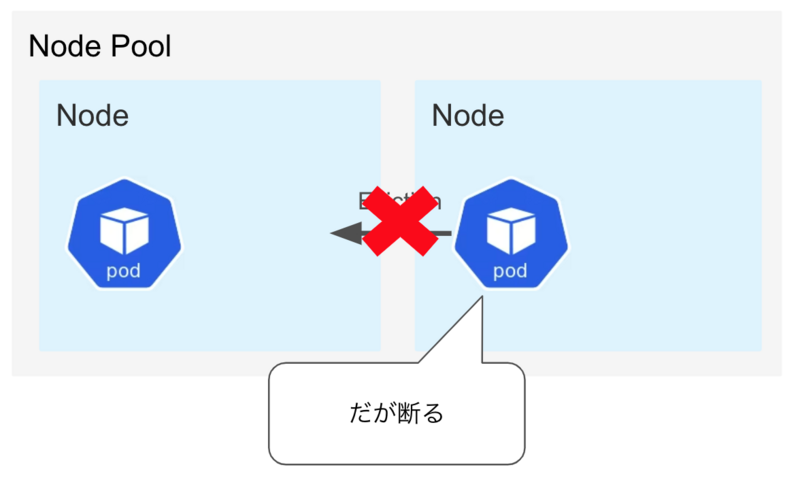
Evictionで困るのはバッチだけではありません。 例えば、レプリカ数が1しかないAPIなどは別のNodeで新たに起動している間にはサービスの断続が出てしまいます。 この様にEvictionを回避したい場合は色々あり、Google CloudでもEvictionを回避する手段を用意してくれています。 以下のようなannotationを書くことによって回避することが出来ます。
metadata: annotations: cluster-autoscaler.kubernetes.io/safe-to-evict: "false"
しかし、このevictionを回避すると別の問題が出てきてしまいます。
Evictionを回避することによる問題
Evictionを回避することによって実際に発生した問題を見てみましょう。 弊チームにはメモリが膨大に必要なバッチからメモリ利用量は少ないが長時間かかるバッチまで様々なバッチがあります。 そこで以下のようなケースを考えてみます。
- 巨大なNodeに巨大なPodが実行される。
- そのNodeにメモリ利用量が少なくて長時間かかるPodが迷い込む
- 巨大なPodが終了する
- メモリは全然必要ないのに長時間かかるPodが残り続ける
- evictionが拒否されるため、巨大なNodeはずっと残り続ける
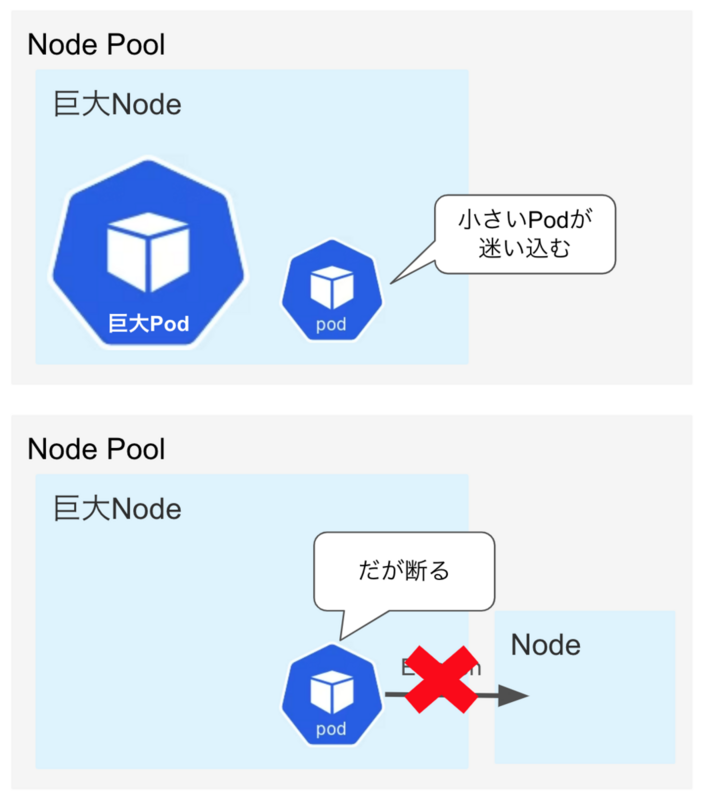
この様にevictionを回避した結果、高価なNodeがずっと残り続け課金額が跳ね上がります。
そこで弊チームでの回避方法をどうしたかを見てみましょう。 PodにはnodeSelectorという値を指定できます。 nodeSelectorはPodが載ってもよいNodeの種類を選ぶというものです。 そして、NodePoolにはリソースが少ないNode用のものからリソースが多いNode用のものまで用意します。 これによってある程度料金とNodeのスケールを指定することが出来ました!(手動で)
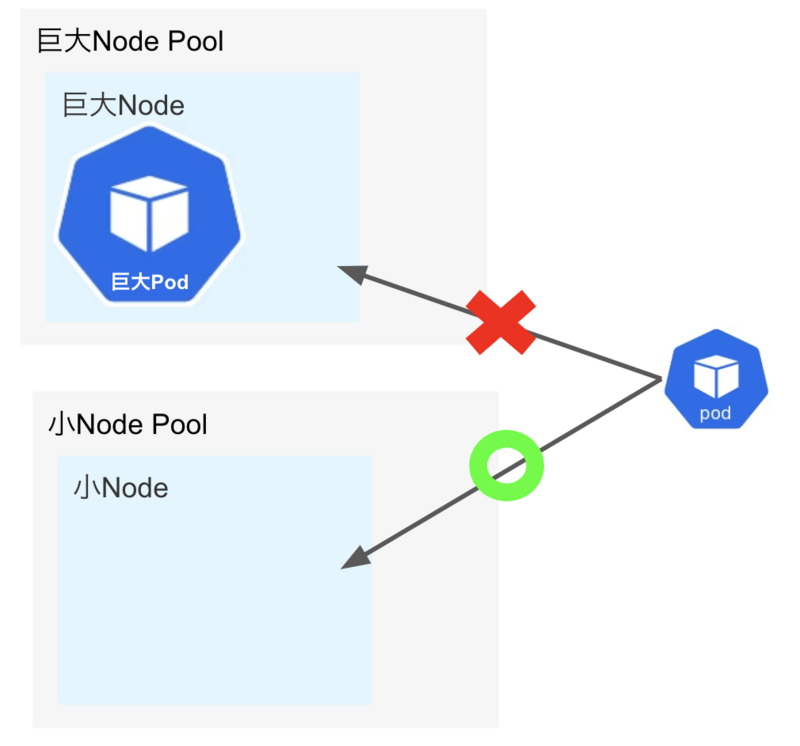
Nodeについてはもっとメモリが欲しいという要望があったり、GPUを載せたNodeがほしいという要望があったり様々です。 そして、Spot VMのような料金が安いNodeなども用意してデフォルトではそちらを使うようにするなどしたりしました。 結果NodePoolを管理する数が増えていき、人間が考えなければいけないNodeが増えていきました。。
GKEにはStandardモードとは別にAutopilotモードがあります。 AutopilotモードはNodePoolの管理をユーザーがしなくても良いモードになります。 これを利用すれば、このNode管理地獄から抜け出せそうです!
Autopilotは銀の弾丸になるか
さて、Autopilotがどのようなものかを見てみましょう。 GKEのStandardがNodeのVMの料金課金だったのに対して、Autopilotは各Podのリソース料金課金になります。 つまり、我々が今まで管理していたNodeの空き容量があると、小さなPodが迷い込んでNodeの課金額がとか言っていたのがPodにしか課金されないので気にしなくても良くなります。 さあ、これですべて解決したと思われたその時
Autopilotではsafe-to-evictが利用できません
そう、振り出しに戻ります。 safe-to-evictの裏側を考えると、Google Cloudのリソースの最適化とは方向性が違ってくるでしょうし、Autopilotでの展開の難しさは想像に難くありません。 そのため、現時点のAI・機械学習チームでは、時間のかかるJobのAutopilotモードの利用に踏み切れていませんでした。
このブログをこれで締めようと思いつつ、ファクトチェックのために色々調べていたらこのような記事に出会います。
なんとAutopilotでもsafe-to-evict利用できるようになっている!!?? 我々的には超重大ニュースが、7月くらいに出てました。気づくのに4ヶ月かかりました。。 注意点としてはevictionを防げるのは7日間だけということです。
自分たちの用途としては7日以上かかるJobは数個しかないので、Autopilot行けるかとなり試して見ようとしました。そして、、、
safe-to-evictはSpot VMでは利用できません
Spot VMというのは可用性が保証されないかわりに通常のVMに比べて非常に安価に利用できるインスタンスです。 Spot VMは最小で60%の割引、最大で91%の割引が適用されます。 可用性が保証されないとはいえ、そこまでスケールインが多発するわけでもないのでStandardモードでは多くのJobがSpot VMでsafe-to-evictを利用していました。 Spot VMがsafe-to-evictで利用できる事を完全に保証をするのは難しそうですし、Google Cloud上でも利用できないのが現状です*1。 個人的な感覚では、Spot VMのスケールインよりもevictionの方が頻度が多いと思っています。 なので、本音を言えば「safe-to-evictを完全には保証出来ないが内部のevictionを発生しない」といった方向性で良いので利用させて欲しい所ですが、これはこれで保証のラインが難しそうだなと思いながら情報ウォッチしています。
というわけで料金最適化のためにStandardに残り続けるか、NodePoolの開放を求めてAutopilot(非Spot VM)に行くか 我々のGKEでのMLOpsはまだまだこれからだぜという事で締めさせてもらいます。
まとめ
Kubernetes上でのMLはAPIのような利用とは異なることを考える必要があり、なかなか難しいです。 しかし、Kubernetes上に集めることによって監視などを自動化するなど嬉しい点もたくさんあります。 何よりKubernetesをいじれる環境というのはとても楽しいです。 今後もAutopilotの進化を見つつ、いつでも乗り換え出来るようなインフラの作り方を心がけていきたいと思います。
We are hiring!!
AI・機械学習チームでは、自分たちでGKEクラスタを運用しながら積極的にMLOps基盤開発に取り組んでいます。 システム全体を見通して基盤を作っていきたいMLOpsエンジニアを募集しています!
*1:記事執筆時点 2023/12/11