こんにちは。エムスリーエンジニアリンググループ AI・機械学習チームでAPIエンジニアをしている農見(@rookzeno) です。最近はAPIを作ったり叩いたりする仕事をしています。
今回はGoogle CloudからPythonでGoogle Drive APIを叩く経験を得たので、その内容を記載していきたいと思います。具体的にはGoogle Driveから必要なファイルをdownloadして加工後、uploadするという一連の流れになります。

- APIにアクセスできるようにする
- ローカルでリフレッシュトークンを作成する。
- Google Cloudにclient_secret.jsonとtoken.jsonを置く
- Google CloudからGoogle Drive APIを利用する
- 最後に
APIにアクセスできるようにする
Google CloudからDriveAPIを叩く方法は、サービスアカウントの権限でDriveにアクセス方法と別のGoogleアカウントの権限でDriveにアクセスする2種類の方法があります。今回はセキュリティの設定でサービスアカウントにアクセスしたいDriveの権限を与えることが出来なかったので別のGoogleアカウントの権限でDriveにアクセスする方法を使用しました。
この場合することは
① APIとサービスでGoogle Drive APIを有効化する

② OAuth クライアント ID を作成する
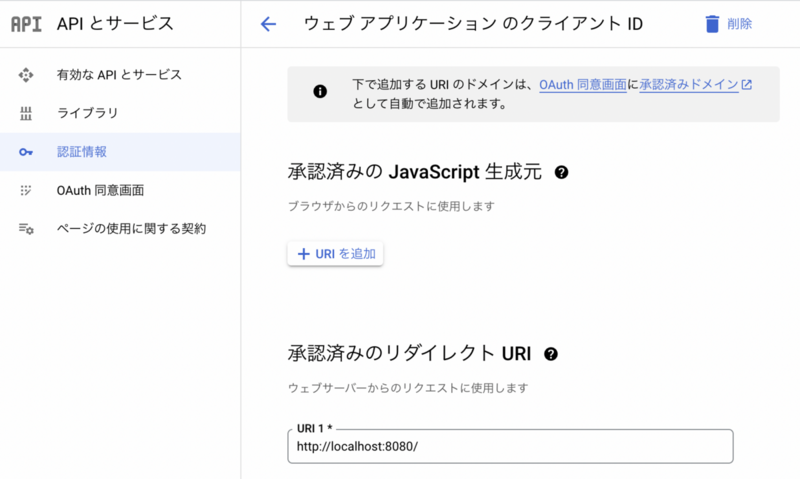
今回はウェブアプリケーションで作成しました。ただし、承認済みのリダイレクト URIが空だと後でする認証が通らないのでhttp://localhost 等の適当なURLを書いておきましょう
作成したらOAuthクライアントの情報をJSONでダウンロードします。client_sercret_~~~.json(今後、client_secret.jsonと呼ぶ)というファイルです。
③ OAuth同意画面でGoogle Drive APIのスコープを追加する
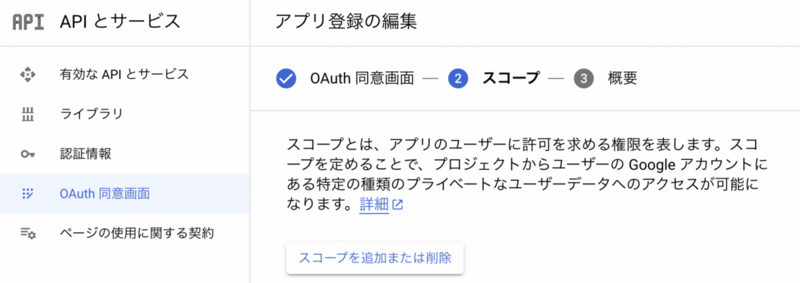
以上でAPIにアクセスする準備は完了です。
ローカルでリフレッシュトークンを作成する。
必要なライブラリをインストールします。
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib oauth2client
その後、以下のコードを実行します。
from oauth2client import client, file, tools SCOPES = ['https://www.googleapis.com/auth/drive'] store = file.Storage('token.json') flow = client.flow_from_clientsecrets('./client_secret.json', SCOPES) tools.run_flow(flow, store)
実行すると自動的にブラウザが開き、Googleにログインを求められます。
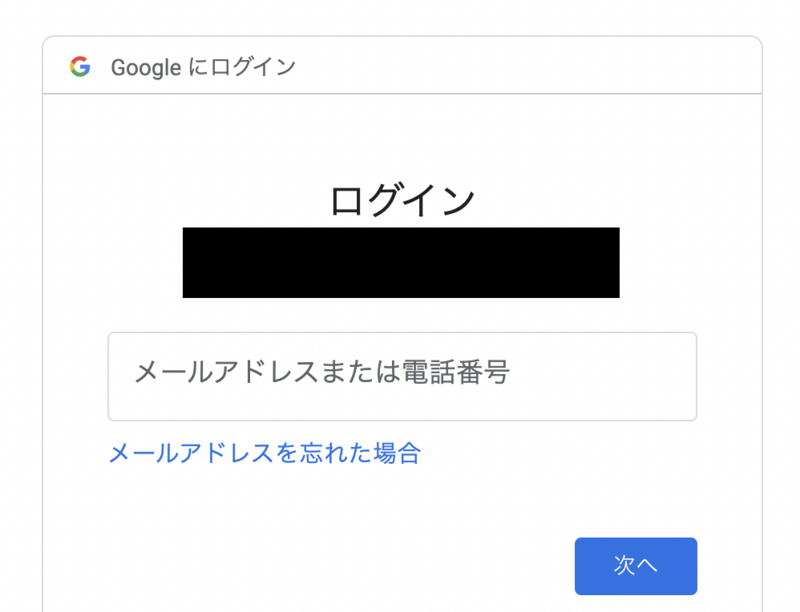
使用するアカウントでログインして、許可すると認証が完了してリフレッシュトークンを得ることが出来ます。
Google Cloudにclient_secret.jsonとtoken.jsonを置く
AIチームではSecretをBerglasで管理しているので例に倣って、BerglasでGoogle Cloudにトークンを置きました。AIチームのSercret管理に関する記事はこちらです
Google CloudからGoogle Drive APIを利用する
前置きが長くなりましたが、本題です。共有ドライブのフォルダで作業したので、マイドライブで作業する場合とは異なったコードになってます。簡潔に言うと余計な設定が増えてます。
共通部分
以下の作業では毎回同じclassを作成するので最初に共通化しておきます
from googleapiclient.discovery import build from oauth2client import client, file, tools def drive_api_client(): store = file.Storage('token.json') creds = store.get() drive_service = build('drive', 'v3', http=creds.authorize(Http())) return drive_service
ファイルを一覧表示する
どのファイルをダウンロードするか決めるためにファイル一覧を取得します。
def ls_drive(q: str): drive_service = drive_api_client() files = drive_service.files().list(corpora='drive', # 共有ドライブを指定 driveId='xxxxxxxxxxx', # 共有ドライブのId includeItemsFromAllDrives=True, # 共有ドライブを含めるため includeTeamDriveItems=True, # 共有ドライブを含めるため q=q, pageSize=100, # 一度に返すレスポンスの上限 supportsAllDrives=True, # 共有ドライブを含めるため fields= 'files(mimeType,id,name)' # 必要な返り値を指定できる。filesのtypeとidとnameがあれば基本十分 ).execute()['files'] return files
qに検索する条件を入れます。公式サイト 見れば分かるように結構何でもできるんですが、僕はあるフォルダの全部のファイルを検索するために
"'folder_id' in parents and trashed = false"
で検索してました。folder_idはdriveのフォルダ開いた時に出てくるurlの最後の部分です。
これの返り値はこんな感じです
[
{'mimeType': 'text/csv',
'id': 'xxxxxxxxxxxxx',
'name': 'xxxx.csv'}
]
注意としては、files().list()はpageSizeというレスポンス上限があるので、それを超えそうならnextPageTokenも取ってきて、再度pageTokenを指定して実行を繰り返す必要があります。PageSizeを大きくするのでも良さそうです。
ファイルをダウンロードする
ダウンロードはファイルIDが分かれば以下でできます。
def download_drive_file(file_id: str, file_name: str): drive_service = drive_api_client() request = drive_service.files().get_media(fileId=file_id) file = io.FileIO(file_name, 'wb') downloader = MediaIoBaseDownload(file, request) done = False while done is False: status, done = downloader.next_chunk() print(f'Download {int(status.progress() * 100)}.')
フォルダを作成する
ダウンロードしたファイルを加工したものを置くためのフォルダを作成します。どこにフォルダを作成するかをparentsで指定します。
def create_folder(file_name: str, parent_id: str) -> str: drive_service = drive_api_client() file_metadata = {'name': file_name, 'mimeType': 'application/vnd.google-apps.folder', 'parents': [parent_id]} create_file_id = drive_service.files().create(body=file_metadata, fields='id', supportsAllDrives=True).execute() return create_file_id['id']
後でファイルをアップロードするのに利用するので作成したフォルダのIDを取得します。
ファイルをアップロードする
parentsで指定したフォルダにファイルをアップロードします。ファイルが2GBを超えることがあったのでresumableをTrueにしました。
def upload_drive_file(file_dir: str, file_name: str, parent_id: str): drive_service = drive_api_client() file_metadata = {'name': file_name, 'parents': [parent_id], 'driveId': 'xxxxxx'} # resumableをTrueにしないと2GBの制限に引っかかる media = MediaFileUpload(file_dir, mimetype='application/zip', resumable=True) request = drive_service.files().create(body=file_metadata, media_body=media, supportsAllDrives=True) done = False while done is False: status, done = request.next_chunk() print(f'Uploaded {int(status.progress() * 100)}.')
注意点としてはresumableをオンにすると最新のhttplib2の場合、googleapiclient.http.MediaFileUpload との兼ね合いが悪くエラーになったためhttplib2==0.15.0を指定してます。
最後に
Google Drive APIを使うのは初めてだったので触るのが楽しかったです。知らないAPIで遊ぶのは楽しい。
参考にしたサイト
数少ない日本語でPythonを使った記事だったので大きく参考にしました。
Google Drive APIの公式サイト。よく使われるAPIなので公式もしっかりしている。
API Reference | Google Drive | Google Developers
We are hiring!!
弊社では色んなAPIで遊んでいる人材を募集しています! 以下のURLからカジュアル面談をお待ちしています!