【 AIチーム ブログリレー7日目】 こんにちは、エムスリーエンジニアリンググループのAI・機械学習チームで機械学習エンジニアをしている氏家です。今日はエムスリーのMLインターン面白いぞ、と言う話です。

AI・機械学習チームでは通年でインターンを募集しています。インターンの課題はML基盤の構築からアルゴリズムの開発・改善まで多岐にわたり、データエンジニアリングとしてもMLとしても面白い課題が揃っています。 最近のテックブログでも、BigQueryのローカルテスト基盤を作ってくれた後藤さんや、エムスリー発のOSSであるgokartの並列分散実行に取り組んでくれた小栗さんなどがインターンの様子を伝えてくれています。
エンジニアリング寄りの課題はお二人の記事に譲るとして、MLはどういうことするの? そもそもどういう流れなの? という方が多いかと思います。 そこで今回は、ML課題におけるインターンの流れを紹介し、京都大学大学院の唐井さんが取り組んでくれた「ユーザーの投稿確認システムの改善」というテーマを例にインターンの面白さをお伝えできればと思います。
インターンの流れ
AI・機械学習チームでのMLインターンでは、基本的に「社内の〇〇を改善したい」といった課題に沿ってモデルやシステムを開発、改善していきます。 多くの場合インターンの最終目標は、開発したモデルをプロダクトとしてリリースし実際に課題を解決できたか検証することです。 実際にはインターン期間が2週間しかないため検証までやり切ることは難しいですが、リリースや検証まで至らなくとも、課題解決を見据えた開発をすることで、ビジネスでのML応用を体感できるインターンになっています。
分野は自然言語処理から画像処理、推薦まで幅広く、本人の興味に合わせてメンターと相談しながらテーマを決定します。 自分の研究分野と近しい課題を選んでも良いですし、普段触っている分野から離れた分野にチャレンジもできます。 その場合もメンターはじめチームメンバーが全力でサポートします。
テーマの決定後は、いよいよモデルの開発です。メンターの補助のもとモデル開発、改善に取り組んでいきます。 開発は社内のリソースを自由に使い、本人の裁量でどんどん進めていくことができます。 本人の裁量で進めていくとは言いつつも、朝会やメンターとの日次1on1が設定されているなど、インターン中のサポートは充実しています。 また、チームの雰囲気もいい意味でカジュアルで、Slackで聞くとすぐに回答が来るようなチームなので、開発を自発的にゴリゴリ進めていける環境になっています。
ここからは実際のテーマを元に見ていく方がイメージしやすいと思うので、唐井さんが取り組んでくれたインターンテーマを元に具体的な様子を見ていきましょう。
インターンテーマ: ユーザー投稿確認システムの改善
唐井さんのインターンでは、エムスリーが運営する健康医療相談サービスでの投稿確認業務の効率化に取り組んでもらいました。 ちなみに、唐井さんが作成してくれたモデルは(ほぼ)そのままリリースされようとしています。テックブログでの報告になりますが、唐井さんお疲れ様でした、ありがとうございました!
AskDoctorsにおける投稿確認システム
エムスリーではAskDoctorsという遠隔健康医療相談サービスを運用しており、毎日大量の医師への相談が寄せられています。
寄せられる投稿の中には「〇〇県に住んでいる〇〇(氏名)と申します」といった個人情報を含むものなどもあるため、ユーザーのプライバシー保護等の観点で、投稿時点で公開しうる投稿かどうか確認を行なっています。 しかし、大量の投稿を人手で全て確認していると効率的ではありませんし、どうしても見落としが発生してしまいます。 当然確認が終わるまでは医師回答が得られないため、ユーザー体験向上のためにも確認業務の効率化は重要になります。
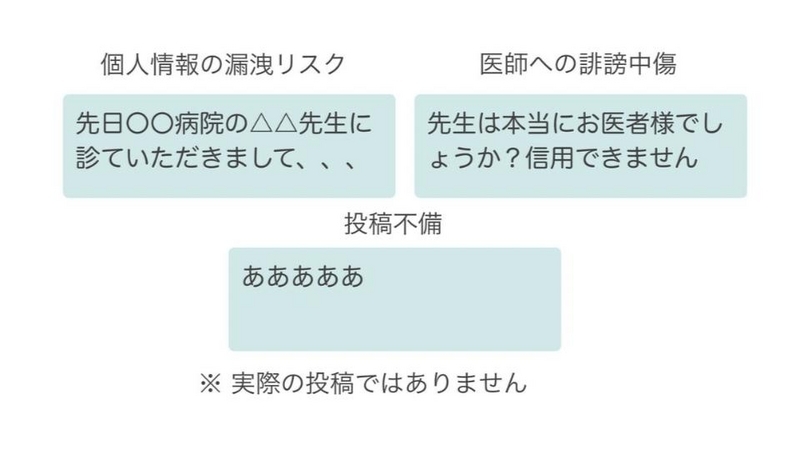
そこで、弊社ではこの確認業務にMLシステムを導入しています。 具体的には、投稿が不適切かどうかをモデルで判断し、その予測結果をもって人手確認業務を補助することで、確認を効率化するとともに不適切投稿の見落としを減らすことができています。
インターンでは、確認業務のさらなる効率化を目指し、この現在運用されている自動投稿確認システムの精度改善に取り組んでもらいました。
タスクとしての面白ポイント
今回のタスクは素朴には不適切かどうかの2値分類モデルで解けると思います(現状運用されているモデルも素朴な2値分類モデルです)が、このモデルを改善するにあたってデータの特徴など考慮すべき面白い(難しい)ポイントがあるのでいくつか紹介していきます。
不適切理由の多様性
まずは不適切の判定理由が多岐に渡ることがあげられます。
一口に公開すべきでない不適切な投稿と言っても実際には多くのパターンがあり、例えば個人情報ひとつとってもテキストとして言及されている場合もあれば、添付されたCT画像に氏名や病院名が入り込んでいる場合もあります。 他にも、医師への誹謗中傷や誤った薬の使用方法など、投稿者や回答していただく医師、質問を閲覧するユーザーが不利益を被らないための多くの確認項目があります。
過去に不適切だと判定された投稿には全て不適切な理由が付与されているため、それらを使ってモデルを改善していくことになります。 例えば、モデルを何段かに分けたり、不適切な理由を損失に考慮したりなど、改善ポイントは多く思いつきます。 また、画像やユーザー情報も合わせてマルチモーダルモデルを構築もできるでしょう。
実際に今回のインターンでは、唐井さんの試行錯誤の結果個人名や病院名が既存モデルで特に取れていないことがわかり、個人情報などの項目について特化したモデルを前段にはさむことで精度を改善されました。
適切な評価指標
また、実際に運用していく上で、評価指標を考えることも必要になってきます。 今回のような設定ではRecallを高く保ち、Precisionを上げていくのが一般的だと思いますが、不適切判定という性質上、偽陰性がどのような投稿だったかも重要です。 というのも、前項の通り不適切な理由は多様にあり、その中でも個人情報など優先して精度を上げたい項目が存在するからです。
そのため、偽陰性について重要性を追加でアノテーションし、重要度の高い投稿についてRecallを見ていく、といったことが必要になります。 このように、実際の使われ方を意識した評価設計を経験できるのも面白いポイントだと思います。 インターンでは、既存モデル開発時のものを評価設計の土台にしつつ、実際に少数のサンプルについてアノテーションしてもらい、今回の設定での評価指標を設計してもらいました。
まとめ
今回はAI・機械学習チームでのインターンについて紹介しました。 今回紹介したテーマ以外にも、推薦システム改善など社内に蓄積されたデータを使った迫力ある開発ができるテーマが揃っています。 大学生や大学院生で、企業でのモデル開発を経験してみたい方は下記リンクから応募してみてください!
We are hiring!!
エムスリーではモデルをゴリゴリ開発したいインターン・正社員を随時募集しています!この記事を読んでピンと来た方は是非ご応募ください。カジュアル面談も絶賛募集中です!