こちらはエムスリーAdvent Calendar 2022の20日目の記事です。 AI・機械学習チームの池嶋 iksm (@mski_iksm) / Twitter です。
AI・機械学習チームでは、ユーザーへの記事レコメンドなどに活用するために、各ユーザーの興味キーワードを特定する機械学習モデルを開発しています。このモデルは前日までのモデルを初期値として、新たなデータを加えて追加学習をする、というのを繰り返しています。そのため、前日のモデルを再帰的に参照しています。
ここで問題になるのはコードを修正するなどしてモデルを変更する場合です。モデルを変更しようとすると、整合性を保つために前日のモデルも変更が必要になり、その場合そのまた前日も…という具合でかなり過去のモデルまで遡った変更が必要になります。しかし、長期間遡ってモデルを変更しようとすると、今日のモデルを作るまでに非常に長い時間がかかってしまい、日次バッチの完了予定時刻*1を超過してしまう問題が発生します。
この記事では、この問題にいかに対応しようとしているかを、過去の戦いも含めて紹介します。

tl;dr
- 前日モデルに再帰的に依存するモデルは、モデルのバージョンを変えるときに過去分のモデルも再実行する必要がある
- しかし、過去分モデルの再実行に時間がかかる場合、モデル変更を安易に行うと本番運用されている日次バッチの完了予定時刻を守れなくなるので困る
- そこで、「準備が完了している過去分モデルのバージョンを管理しておき、本場運用モデルはそのうち最新のものを使用するようにする」という運用方法をとった
言及すること
- 過去モデルを再帰的に参照するモデルのコードやデータ変更の難しさ
- モデル変更を可能にする実装の工夫
言及しないこと
- 興味キーワードを特定する機械学習モデルの詳細
- tl;dr
- 課題の定義
- v1運用: 手動で過去分モデルを作り、手動で本番モデルを切り替える
- v2運用: 興味キーワード出力用環境と過去分モデル作成用環境と最新コードをコミットしていく環境を3段階に切り離す
- v3運用: 使用可能な最新コード・キーワードマスタのバージョンを別途管理する
- まとめ
- We are hiring!!
課題の定義
冒頭にあったように過去のモデルに再帰的に参照のある機械学習モデルを考えます。具体的には各ユーザーの興味キーワードを特定するモデルです。興味キーワードは時々刻々と変化する可能性があるため、毎日更新ができるよう日次で視聴ログを取り込み、モデルを作り直しています。たとえば9/3のモデルは9/3の視聴ログを使ってモデルを作成しています。
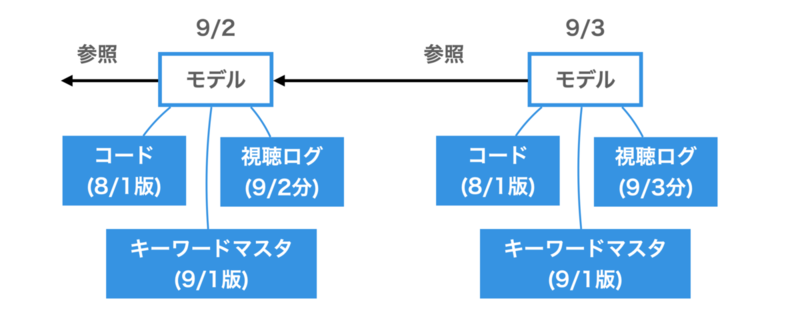
このモデルは前日までのモデルを初期値として、新たなデータを加えて追加学習をする、というのを繰り返しています。今日分のモデルを作るためには前日分のモデルが、前日分のモデルを作るためには前々日分のモデルが、…という形で2年前まで遡った日付分のモデルが必要になっています。
このとき、前日のモデルであれば何でもOKなわけではないのが難しいポイントです。モデルには「興味キーワードマスタのバージョン」と「コードのバージョン」の組み合わせでバージョンがあり、これを揃えないといけません。
興味キーワードマスタは興味度をトラッキングするキーワードの一覧です。新しい疾患や新しい薬剤が出てくると、その新語に対応する必要があるため、月に一度程度の頻度でキーワードマスタは変更されています。例えば、9/3のモデルは9/3頃の視聴ログと9/1のキーワードマスタを使ってモデルを作成しているというバージョンになります。前日以前のモデルを参照するときには同じく9/1のキーワードマスタを使って作った9/2、 9/1、8/31、 …のモデルを参照する必要があります。
またコードが変更され、モデルのロジック自体に変更が入る場合もあります。そのためコードのバージョンもモデルに影響を及ぼします。例えば、9/3のモデルは9/3頃の視聴ログと9/1のキーワードマスタと8/1のコードを使ってモデルを作成しているというバージョンになります。前日以前のモデルを参照するときには同じく9/1のキーワードマスタと8/1のコードを使って作った9/2、9/1、8/31、…のモデルを参照する必要があります。
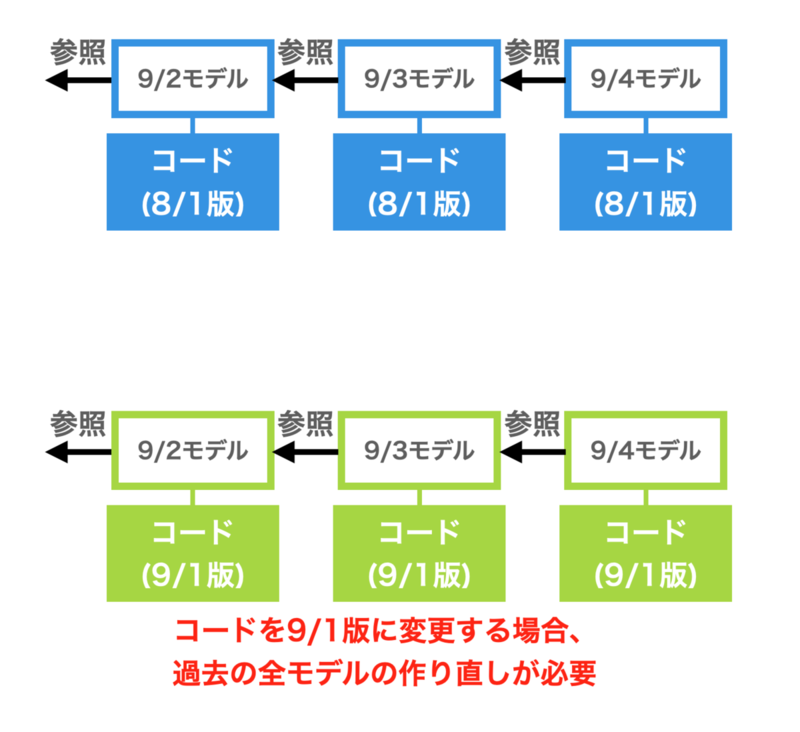
このように、キーワードマスタを変更するとき、あるいはコードを変更するときには、同じキーワードマスタ・同じコードで実行した過去分のモデルが必要になってきます。
モデルの作成には1日分を作るのにだいたい30分ぐらいの時間がかかります。日次バッチでは通常1日分だけを作成するので、この実行にかかる時間は許容されています。しかし、2年間遡って過去分のモデルを作成しようとすると、モデル間に依存関係があり順番にしか作れないことから、完了まで16日程度かかってしまいます。サービスごとに定められたバッチ完了予定時刻までにモデル作成が終わらず、他サービスにも影響を与えてしまうことから、この遅れは許容されません。「ある日コードやキーワードマスタを変更したら、それ以降15日間は過去分モデル作成に時間を取られ今日分のモデルが出てこなくなる」というのは非常に困ります。かと言って、コードやキーワードは変更できないのも困ります。
v1運用: 手動で過去分モデルを作り、手動で本番モデルを切り替える
前節で述べた問題に対して、まずは手動で過去分モデルを作り、手動で本番モデルを切り替える方法をとっていました。キーワードやコードが変更になったら、そのバージョンのキーワード・コードの組み合わせで過去2年分のモデルを作成します。これには約15日かかりますが、じっと辛抱します。そして15日後に過去分モデルが全部作成完了したら本番モデルの参照するキーワード、コードのバージョンを最新のものに切り替えます。
下記の図では9/4に過去分モデルの作成を開始したので、9/20ごろに本番モデルの切り替えが可能になります。
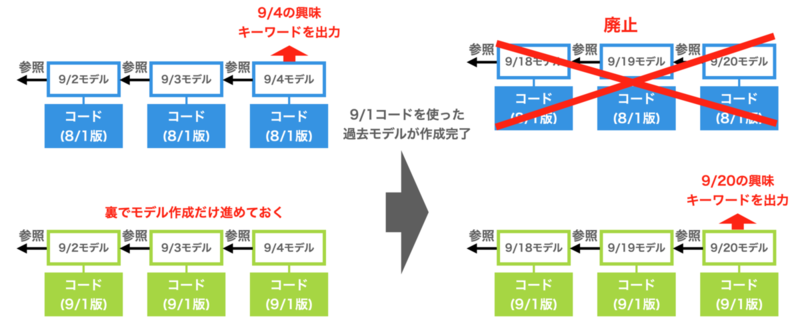
しかし、この手法では切り替えを手動で行うため、オペレーションが難しくミスが起こりうる問題がありました。例えば、過去分のモデルを作成開始後15日ぐらい経ってから完了したかを確認しその後モデルを切り替える、あるいは上図の例では最新バージョンでは9/5~9/19のモデルが作成されていないので本番モデル切り替え前に再度この部分を作成し直す必要がある、など気をつけなくてはいけないポイントが多数ありました。また、キーワードの変更は毎月のように必要なため、毎月ミスの起こりやすい操作に工数を割くのは辛いと考えていました。
そこでこのモデル再作成・切り替えを自動化する方法が求められました。
v2運用: 興味キーワード出力用環境と過去分モデル作成用環境と最新コードをコミットしていく環境を3段階に切り離す
いくつかの議論の末、安定的な運用が可能な方法として考えられたのが、「興味キーワード出力用環境と過去分モデル作成用環境と最新コードをコミットしていく環境を3段階に切り離す」という方法です。これはv1運用で課題となっていた、モデル再作成・切り替えを自動化することが目的です。
各環境の用途と名称の関係は以下のとおりです。
- 興味キーワード出力用環境:daily環境
- 過去分モデル作成用環境:staging環境
- 最新コードをコミットしていく環境:master環境

各環境内ではコードのバージョンやキーワードマスタのバージョンは月内においては固定してあります。月が切り替わるたびにstaging環境のモデルはdaily環境に、master環境のモデルはstaging環境に移行していきます。master環境にコミットされたコードは、次の月にはstaging環境で過去分モデルが作成され、そのまた次の月にはdaily環境で興味キーワード出力に活用されるという仕組みです。
daily環境では、日次の興味キーワード出力のバッチが実行されます。この環境では過去分のモデルが前月にstaging環境において作成済みのため、1日分のモデルを作るだけで今日分の興味キーワードを出力できます。
staging環境では、来月のdailyでの使用に備えて来月用の過去分モデルを作成します。これには15日間かかりますが、毎月2日にはじめても16日には終わるので、多少データが多い月など少し実行時間が伸びても月末には確実に完了している計算です。
master環境は、最新のコード修正をどんどん入れていく環境になります。ここではモデル作成は行わないため、モデルを改変するような修正も躊躇なく入れることができます。次の月の1日に、それまでの修正が入ったmasterブランチのコードのスナップショットがstaging環境のコードとなり、過去分モデルの作成が開始されます。
この方法を採用することで、このMRの修正によってモデルの作り直しが必要になるんじゃないかといった懸念をもたず、躊躇せずmasterへの修正を入れることができるようになりました。また、キーワード・コードのバージョン管理が自動で行われるようになったのでモデルの作り直しなどに工数を割かれることがなくなりました。さらに、各環境のコード(dockerイメージ)とGitのブランチを対応させているので、各環境でのコードがどうなっているのか一目瞭然となりました。
一方で問題点として、コードの変更の反映が最大2ヶ月遅れるという問題もあります。masterに入れたコードは翌々月1日からdailyに反映されるので、例えば9/2にmasterにマージされたコードは11/1になるまで興味キーワード出力の日次バッチに適用されません。これは急いで何か修正を入れたいときに不便です。
また、構成が複雑すぎて障害が発生したときに手動で復旧させるのが難しいという問題も発生しました。AIチームでは基本的に本番データを使った本番環境とは別にテスト用のQA環境、そして開発時の動作確認用のdevelop環境の全部で3つの環境が存在しています。この3環境それぞれにmaster、staging、dailyを意識した対応が求められるので3×3のマトリックスを常にイメージしておく必要が出てきます。障害発生時には急いでいるあまり、チーム内で「QAのdailyってどうなってるっけ?」と尋ねられても「それなんだっけ???」となったり、「prodのQAは?」といったような存在しないブランチを考え始めるといった混乱がありました。
この運用も人間には難しすぎるという結論から、より簡単な構成が求められました。
v3運用: 使用可能な最新コード・キーワードマスタのバージョンを別途管理する
前節v2の方法では、環境が3つに分かれているために構造が難しすぎてオペミスが発生しやすいという問題がありました。
そこで、現在移行が考えられているのが、環境を1つにまとめる代わりに「使用可能な最新コード・キーワードマスタのバージョンを別途管理する」という方式です。日次の興味キーワード出力のバッチでは、使用可能な最新バージョンのモデルを読み込んで使うことになります。
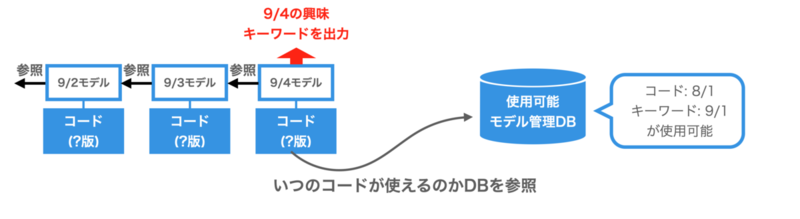
前節のv2の運用では、日次のバッチが動くdaily環境では8/1のコードを、過去分モデルを作るstaging環境では9/1のコードを、という形でバージョンを固定し月次で切り替えていくという方法をとっていました。一方v3では、日次のバッチにはどのバージョンのコード・キーワードマスタを使うかの指定はせず、実行のたびにDBで管理されている「使用可能モデルのバージョン」を参照します。
過去分モデルの作成は、Gitのmasterブランチにコードをマージするたびやキーワードマスタが変更されるたびに自動的に行います。そして完了次第「使用可能モデルのバージョン」のDBに追記します。コードが変更された直後に使えるようにはなりませんが、15日程度経って過去分モデルが用意できるとすぐにコードのバージョンを切り替えられるようになりました。
v3の方法を使うことで、
- 1) daily、stagingなどの環境分けがなくなりシンプルになり
- 2) コードを修正しても変更が日次バッチに反映されるまで2ヶ月かかる遅れの問題が軽減されながらも
- 3) v1で問題になっていた手動の更新作業をなくす
ことができました。
一方で「masterブランチにコードがマージされるたびに過去分モデルが作成されるのは無駄が多いのではないか?」という疑問もあるかと思います。コメントの追加などモデルには影響を及ぼさない修正をmasterにマージしただけで15日間もかかるモデルの作り直しが実行されるのは非効率と感じられます。この問題はAIチームで開発されているOSSのパイプラインツール・gokartを使うことで解消しています。gokartを使うことで、変更のあった部分だけコードを実行できます。コメントの追加のような軽微な修正の場合、これまでのコードとほとんど重複するため、ほとんどのコードが実行されず、過去のキャッシュを流用できます。これにより、非常に短時間でモデル作成を完了できます。
gokartの詳しい説明は過去の当ブログをご参照ください。
まとめ
この記事では前日モデルに再帰的に依存するモデルに関して、まずコードやデータの変更によるモデル変更の難しさを紹介しました。そして過去の実装も含めて、どのような設計にしたらいいかを議論しました。現在はv3運用の節で述べた「使用可能な最新コード・キーワードマスタのバージョンを別途管理する」がいいのではないかと考え、実装を進めています。
We are hiring!!
今回の記事では機械学習モデルを実運用にどうやって載せるかという取り組みを紹介しました。AI・機械学習チームではこうしたMLOpsはもちろん、MLモデルそのものの開発・改善も行っております。カジュアル面談等でちょっと話を聞くのもOKなので、興味がある方は下記リンクにてお待ちしています!
*1:AI・機械学習チームではほとんどのバッチに完了予定時刻が設定されており、これに違反していないか監視が行われています。監視に関しては以下の記事で紹介されています。 https://www.m3tech.blog/entry/ai-slo-monitoring