
こちらは 情報検索・検索技術 Advent Calendar 2022 の19日目の記事です。
エムスリーエンジニアリンググループ AI・機械学習チームでソフトウェアエンジニアをしている中村(po3rin) です。検索とGoが好きです。
今回はElasticsearch × バンディットアルゴリズムで検索リランキングを最小工数で実装したアーキテクチャを紹介します。バンディットアルゴリズムをオフラインで行うことで実装するべきものを最小限に出来た例として面白いと思います。
Overview
エムスリーではGoogleやYahoo!での検索から流入してきたユーザーにサイト内のコンテンツを表示するサービスがあります。
流入したページに表示するコンテンツは流入キーワードを使ったサイト内検索結果を表示します。この検索結果はユーザーのアクセスから利用促進を促すための重要な機能です。
検索機能は内部でElasticsearchを利用しており、基本的なterm検索を行なっています。検索品質向上への取り組みなどに関しては下記の記事をご覧ください。
ユーザーのアクセスからの更なる利用促進のために、検索結果をバンディットアルゴリズムでリランキングしてリスト上位にユーザーにとって魅力的なコンテンツを並べる施策をしました。
この施策の効果を最短で確認するために、工数最小限でリランキングを試せるアーキテクチャが必要でした。今回はこの施策で実装した検索リランキングアーキテクチャを紹介します。
エムスリーでは今回のように、施策を小さく始めて、効果が出ることが分かってからアルゴリズムを修正していくというフローを大切にしています。なるべく最小工数で施策を試せる構成を追求することはソフトウェアエンジニアの腕の見せ所かもしれません。
既存の検索基盤にバンディットアルゴリズムを使ったリランキングを組み込む
今回採用したアーキテクチャはこちらになります。
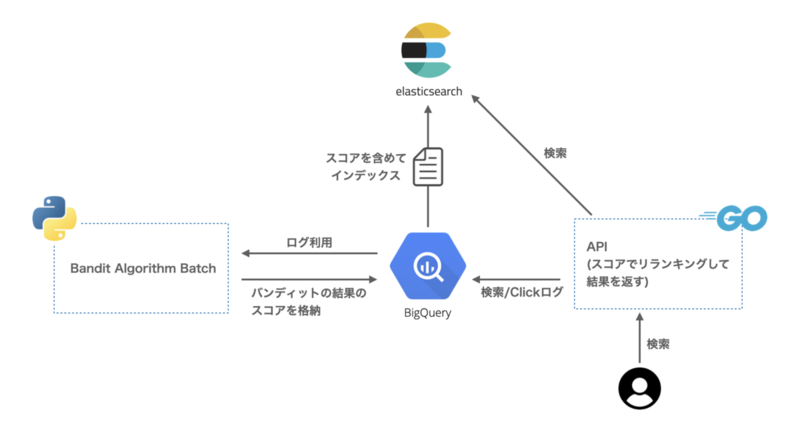
このアーキテクチャによって、エムスリーが保有していた元々のコードや検索基盤を利用でき、開発工数をほとんどかけずに実装できました。1つ1つの要素について簡単に説明します。
Bandit Algorithm Batch
BigQueryからログを参照し、バンディットアルゴリズムを1日1回k8sのcronjobで回して、結果のスコアをBigQueryに格納します。
1日1回のcronjobで回すことによって、オンラインで学習することを放棄することになります。その代わり、単純なアーキテクチャで最適化を実装することが可能になります。今回のケースではリアルタイム性が不要なためこの方法をとっています。この点に関しては後でアーキテクチャの考察でも触れます。
実装に関しては、既にエムスリーにはバンディットアルゴリズムのロジックを実装したPythonプライベートモジュールが存在するのでそちらを使います。このPythonモジュールは医師向けサイト上では年間1億円の利益貢献を生んでいる貢献度の高いモジュールです。これを使うことで開発工数を大きく減らすことができました。
医師向けサイトでのバンディットアルゴリズム利用に関してはこちらの記事をご覧ください
BigQueryからElasticsearchへのインデックス
エムスリーではElasticsearchにドキュメントをインデックスする際にはBigQuery内にあるデータをマスターデータとしてBatchでインデックスを行なっていました。今回の修正ではバンディットアルゴリズムで計算したスコアのフィールドを追加するだけなので、インデックスBatchの数行の変更で対応できました。
API
APIはユーザーからの検索を受けて、Elasticsearchにリクエストを投げて、返ってきた結果をバンディットアルゴリズムで計算しておいたスコアでソートして返します。元々の検索APIの実装にスコアでソートする関数を一個はさむだけなので、こちらも修正コストはほとんど必要ありません。
工夫として、スコアの存在しないドキュメント(まだ探索していない新規ドキュメント)はクエリ関連度(BM25など)で決まるリスト位置をキープします。こうすることで、クエリと関連度の高いドキュメントはリストの上位で探索をすることが可能になります。
検索ログ
検索ログはGoogle Analytics経由でBigQueryに格納しています。検索ログ分析基盤の開発に関してはこちらのブログをご覧ください。
アーキテクチャの考察
上記のアーキテクチャには下記のメリットがあると考えています。
- Elasticsearchを使った検索基盤があれば開発工数が小さい
- バンディットアルゴリズムの変更時に影響範囲が小さい
2点目に関してですが、バンディットアルゴリズムの探索の結果がスコアという形でBigQueryに格納されているだけなので、後段のインデックス処理や、APIのコードに修正が及びません。
一方で下記のデメリット(というか制約?)ももちろんあります。
- リアルタイムな探索ができない
- 候補アイテムの入れ替わりが激しいと探索が仕切れない可能性がある
1つずつ解説していきます。
リアルタイムな探索ができない
リアルタイムに探索ができないため、候補アイテムが頻繁に入れ替わるアプリケーションなどには対応できません。 今回のケースでは元々、リアルタイム性が期待されておらず、1日1回の更新で充分なので、今回のアーキテクチャを採用しました。
候補アイテムの入れ替わりが激しいと探索が収束しない可能性がある
今回のバンディットアルゴリズムの探索対象アイテムは「Elasticsearchが検索で返したドキュメント群」となります。つまり、探索するアイテムは検索クエリでヒットしたドキュメントということになります。検索クエリの結果が毎日変わるような更新頻度の高いアプリケーションでは、探索が収束する前に新しい候補を探索しなくてはいけなくなるので思ったように効果が得られないかもしれません。
今回のケースではクエリでヒットするドキュメントの更新頻度が低かったため、このアーキテクチャでも問題がありませんでした。
発展
アーキテクチャの紹介から少し話はそれますが、今回のケースにおいて、クエリごとにドキュメントを最適化する方法を簡単に紹介します。
クエリごとのドキュメント最適化
シンプルな実装では、クエリの内容を無視して、任意の検索で出てきたドキュメント全体を探索対象としてスコアリングを行えますが、クエリごとに最適化したい場合は、Elasticsearch側で少し工夫が必要です。
クエリごとの最適化を行いたい場合はクエリごとにバンディットアルゴリズムを回し、クエリとそれに紐づくドキュメントのスコアをElastisearchに格納する必要があります。Elasticsearchではこれをnestedフィールドで表現します。
// ... "ranking_score": { "type": "nested", "properties": { "query": { "type": "keyword", "index": true }, "score": { "type": "double", "index": true } } }, // ...
これで検索時にクエリに紐づくスコアのみを取得してAPI側でソートすれば、クエリごとにランキングを最適化できます。
一方で、検索数が少ないクエリではいつまでたっても探索が終わらないなどの問題も発生します。検索数が少ない=最適化しても効果が薄いと判断して、今回の施策ではあまり重要な問題としては捉えていません。
実際に今回の施策ではクエリごとに最適化した方が良い効果が出ています。アプリケーションの属性に応じて使い分けましょう。
ポジションバイアス
リスト形式のアイテムを最適化する場合、リスト位置によってポジションバイアスが発生します。今回は単純にクエリ全体でポジションごとのクリック率の平均値で補正していますが、ポジションバイアスを推定する方法にはいくつか方法があります。
書籍「施策デザインのための機械学習入門」にはPair Result RandomizationやRegression-EMなどのポジションバイアスを推定する方法が挙げられているので、興味ある方は是非読んで見てください。

また、ユーザーのリスト走査をCascade Model(ユーザーが結果リストを順位の高いアイテムから順番に走査していくことを仮定したモデル)と仮定した場合に利用できるポジションバイアスを考慮したバンディットアルゴリズムなども存在します。こちらに関しては下記記事で紹介しています。
まとめ
制約は多いですが、今回紹介したアーキテクチャによりバンディットアルゴリズムを使った検索リランキングを簡単に試すことができました。バンディットアルゴリズムの実装を試したい場合はPythonの実装もついている下記の書籍がおすすめです。基本的なアルゴリズムに加えて、アイテムの特徴量などを考慮できるContextual Banditも紹介されています。

We're hiring !!!
エムスリーでは検索&推薦基盤の開発&改善を通して医療を前進させるエンジニアを募集しています!
「ちょっと話を聞いてみたいかも」という人はこちらから! jobs.m3.com