この記事はエムスリー Advent Calendar 2022 14日目の記事です。 AI・機械学習チームの北川(@kitagry)です。 最近猫を飼い始めました。可愛くて仕方がありません。 元々全然外に出なかったのに、引きこもりが加速されています。
今回は去年、新卒1年目の時に引き継いだアラートだらけのシステムを黙らせた話について書きます。

引き継いだプロダクトについて
エムスリーでは、医療従事者向け総合医療情報である「m3.com」というウェブサイトを運営しています。このウェブサイト上には、医療ニュース、医学文献検索、医師限定掲示板、求人募集・転職情報など様々なコンテンツが掲載されています。
実際の画面は下記の通りです。
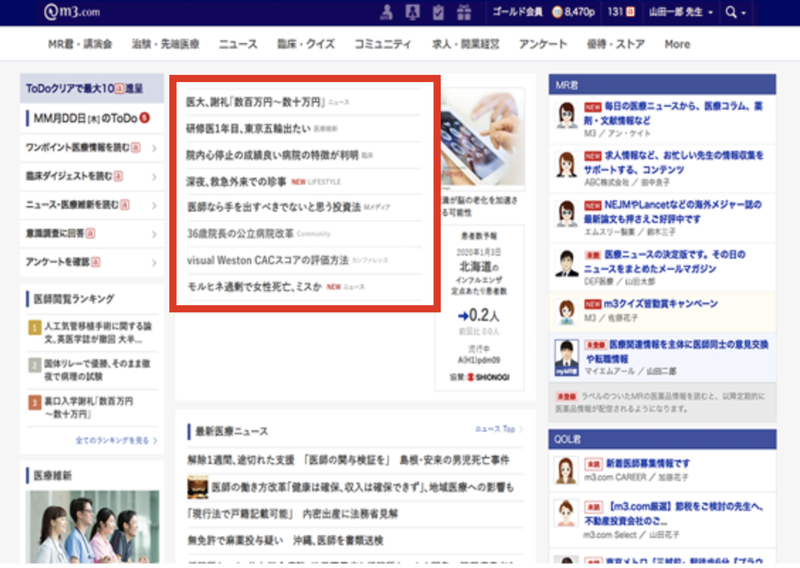
今回はこのトップページの中でも特に目立つ位置にある、医療系のニュースなどを扱うエリア(画像中の赤枠で囲ったエリア)の推薦システムを改善しました。
このプロダクトの開発当初については下記の記事にまとまっています。 僕が入社する前の記事ですが、新規プロダクトを開発する上でとても参考にしている記事なのでぜひ読んでください。
この記事の後も、このシステムは色々変化がありました。 具体的には以下のようになっていました。
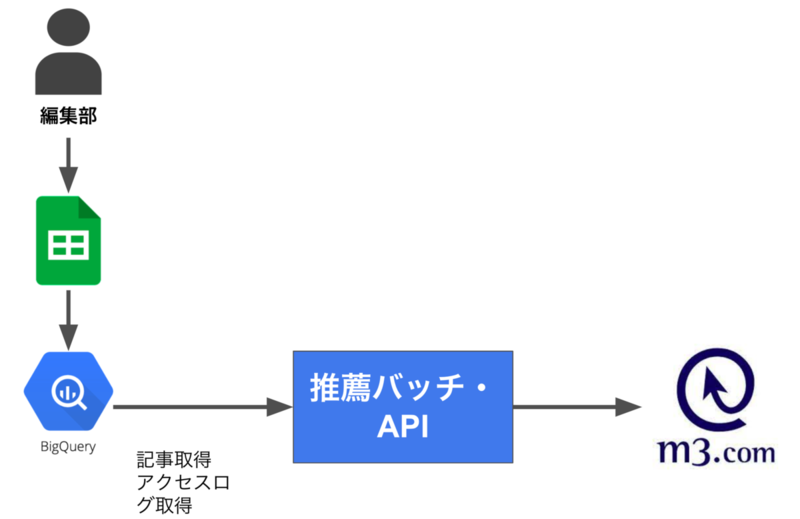
特徴としては以下の通りです。
- 20分ごとにサービスごとのバッチが動き、準リアルタイムで推薦を行なっていた
- 探索した結果をメルマガ・アプリのプッシュ通知などの他の出面で使われるようになった
急成長するプロダクトとそれに伴う痛み
上記のブログの通り、このプロダクトはトップページで大きな利益をあげました。 このプロダクトでは準リアルタイムで記事の探索し、記事をスコアリングするというバンディッドアルゴリズムで動いていました(実際のバンディッドアルゴリズムはリアルタイムが多いと思います)。 このスコアリングが確定するまでの速さによって、その日のニュースをこのプロダクトでスコアリングし、その日のうちにメール配信やアプリのプッシュ通知で使うなど幅広く利用されてきました。 これによってこのプロダクトはチーム内でもトップレベルの利益をあげるプロダクトへと進化していきました。 しかし、それと同時にこの急速な横展開によって以下のような副作用が顕在化していました。
- 一日に20回鳴るアラート
- 横展開によるコードのレガシー化
僕が引き継いだ時にはこの急速な横展開で徐々に顕在化が始まっており、僕がプロダクトコードの全容を把握する前に横展開コードを書きながら自分自身でレガシー化を加速させていく感覚がありました。 この問題を早期に解決することが重要なポイントであると思い、これらの問題への対策を始めました。
一日に20回近く鳴るアラート
これが特にやっかいでした。 アラートは一目で内容のわかるもの・わからないもの・実は原因が別の場所にあるもの。 その中でもすぐさま対応が必要なもの・実は放っておいてもよいものなどさまざまなものがありました。 引き継いだ当初は、放っておいても良いものだと思っていたエラーが実はすぐに対応しないといけないもので、編集部に「どうなっているんだ?」と問い合わせを受けて慌てて原因を探りにいくという状態でした。
特にこのプロダクトは横展開された結果、メルマガの配信などのためによりタイトなスケジュールで原因特定までしないといけませんでした。 例えば、16時に入稿されたニュース記事のCTRをこのプロダクトで探索し、どの記事がよりCTRが高いかの結果を元に記事を並び替え18時のメルマガの配信に使うなどの用途で用いられたりします。 そのため、アラートは一刻も早く対策を打たなければいけない問題の一つでした。 また、アラートの調査・対応で僕自身の開発時間を削減されるというのも地味に生産性に響いたり、素直に楽しくない状況でした。
そこで大きな方針として2つの方向でこの問題について対策しました。
- 記事の入稿ミスなどのエンジニアでは対応出来ない場合には編集部向けにアラートを飛ばす。
- 無視しても良いエラーについてはそもそもアラートを出さない。
この2つの対策をすることによって、本当に対応しなければならない問題のみエンジニアがアラートを受け取るという形にしました。
エンジニアでは対応出来ない場合には編集部向けにアラートを飛ばす
この対策は非常にシンプルで記事の入稿にミスがあった場合に編集部に向けてアラートを投げるだけです。 とても簡単でこんなの1日で終わるだろうと思うでしょう。 そう考えていた時期が僕にもありました。
なんと、このプロダクトはコード中の様々なところでassertを行なっており、その全てでそれが編集部向けのエラーなのかどうかを判断する必要がありました。 なぜこんなに各所にassertが散らばっていると、アラートの原因特定後に各エラー箇所にassertを入れておけば原因特定が簡単になるだろうという処理が加えられた結果だと思います。
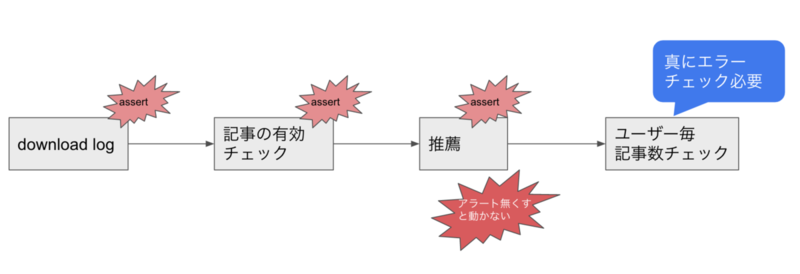
現状の実装のままアラートを追加するという対応でもよかったのですが、横展開をしていたためこれには難点がありました。 例えば各箇所で記事が0件ではないかをチェックするassertがあるとします。 新規の開発で「メルマガに配信する対象の記事は0件でもOKとする」という仕様になった場合、上記のassertの全てでこの条件について対応しなければなりません。 そのため、推薦システムやダウンロードを行なっている箇所に関しては記事が何件であろうと動くようにし、バリデーションを行う場所は1箇所だけにするという方針で実装していくことにしました。
この作業がかなり厄介で一番時間がかかったところでした。 特に推薦システムで記事が0件の場合を想定して書かれていないコードが多く、大体動かないのです。 その場合、テストを追加し、修正していくという形で変更をしていきました。
無視しても良いエラーについてはそもそも出さない
このプロダクトのバッチは20分に1回動いています。 そして、記事の種類ごとや横展開用のバッチなど数十種類のバッチがその間隔で動いています。 1日に40回近く動くバッチだと、たまにBigQueryやGCSなどの外部サービスとの通信エラーが起こったりします。 バッチの時間的には、このようなエラーの場合はすぐさまリトライはせずに、次のバッチで成功すれば問題ありません。 今まではこのような類のエラーについてもアラートを出していたのですが、このアラートがノイズになっていました。 そこで、このプロダクトのSLOとして1時間に1度は少なくとも成功することを定めて、それが満たせなかった場合のみアラートをあげるシステムを構築しました。
このSLOのためのアラートシステムについては以下のリンクに詳しく書いていますので、ここでは割愛します。
結果
今まで毎日20件ほど鳴っていたアラートをほぼ0件に抑えることに成功しました。 また、アラートを切り分けたことで、新たな問題が発生した場合もそれが直すべきなのか否かを判断できるようになりました。 この数ヶ月ほどで一回くらいしかアラートは鳴っていません。(そのアラートもただの設定ミスでした。)
また、SLOに関してはチーム全体にこの考え方が広まっていきました。 チーム全員がアラートに対して対応するべきなのか否かを意識することで、自分が直接関わりないプロダクトでもこのアラートはやばそうだから担当者に連絡を入れておこうという雰囲気が芽生えました。 大量のアラートによって、本当に対応しなければならないアラートが埋もれるということも起きなくなりました。 このようにチーム全体のアラートに対する意識が変わったことが結果的によかったなと思います。
システムの開発や横展開によるコードのレガシー化
ここではアラートに続いて厄介になっていたコードのレガシー化について書いていきます。 このプロダクトは横展開やロジックの改修によりチーム内でもかなり大きなプロダクトの一つになっていました。 そこで、以下の問題が表面化してきました。
- クラスの責務が分離されていないコードがある
- 仕様が失われており、ビジネス制約がわからない
クラスの責務が分離されていないコードがある
横展開を見越して開発してくれと言ってもしょうがないのですが、これにはかなり苦しめられました。 例えば、記事を外部リソースからダウンロードし、それを推薦のために整形するためのクラスがあったとします。
横展開によって、メルマガでは全記事ではなく前日分の記事だけを扱うという処理も加えたいとします。 この場合、ダウンロードするロジックと整形するロジックがクラス内に混ざっていると、このような簡単な変更でも困ることになります。 ここでやってしまいがちな対応は以下の2パターンでしょう。
- メルマガ用にダウンロードと整形クラスを新たにコピーする
- メルマガ用の条件を既存クラスに入れる
この2つ対応にはどちらも弱点があります。 前者の場合は、記事の整形するところに修正があれば直す部分が複数増えてしまいます。 もし、僕のように新しい人が引き継いで修正することになれば修正箇所を見逃してしまう可能性は高くなります。 後者の場合は、クラスが複雑になるということが弱点になります。 メルマガの次に「アプリのプッシュ通知では前日と当日の記事だけが対象です」となったときにどこをどう直すかに頭を悩ませることになります。 今回の例ではDownloadクラスとFormatクラス、2つに分けました。そして、Downloadクラスをそれぞれのサービス用に複数用意し、外部から差し込む形にしました。
このリファクタリングを行う際には必ず既存のテストがそのまま通ることを確認し、不安な場合はテストを追加して行なっていきました。 学生時代に「リファクタリング」読んでおいてよかった。ありがとう。
仕様が失われており、ビジネス制約がわからない
トップページではこのようなユーザーにはこの種類の記事を出してはいけないなどのビジネス上の制約がありました。 ただし、ドキュメントなどは探しても見つからず(実は後にそれっぽいドキュメントと偶然出会うのですが、必要な時に探して見つかることがなかった以上、「存在しなかった」のです)、テストがあるだけでした。 そしてテストがこのような形になっていました。
def test_run: control_items = pd.DataFrame([ dict(user_id=1, item_id='1', item_type='news', rank=1), dict(user_id=1, item_id='2', item_type='news', rank=2), # ここから30行超え dict(user_id=3, item_id='4', item_type='journal', rank=8), ]) test_items = pd.DataFrame([ dict(user_id=1, item_id='2', item_type='news', rank=1), dict(user_id=1, item_id='1', item_type='journal', rank=2), # ここから30行超え dict(user_id=3, item_id='6', item_type='news', rank=8), ]) control_test_user = pd.DataFrame([dict(system_cd=1, is_test=True), ...]) special_item = pd.DataFrame([ dict(system_cd=1, item_id='3', item_type='special'), ]) permission_list = dict(news={1}) n_top_items_list = ({'item_types': ('news',), 'num': 2}, {'item_types': ('journal'), 'num': 1}) special_item_rank = 1.5 actual = GenerateClass.run(control_items, test_items, control_test_user, special_item, permission_list, n_top_items_list, special_item_rank) expected = pd.DataFrame([ dict(user_id=1, item_id='2', item_type='news', rank=1), dict(user_id=1, item_id='3', item_type='special', rank=2), # ここから30行超え dict(user_id=3, item_id='6', item_type='news', rank=8) ]) pd.testing.assert_frame_equal(actual, expected)
これでも、ブログに乗せるためにそこそこ端折っています。 なんと100行超えの壮大なテストです。 このシステムの仕様変更をしてテストが落ちるようになったときに、僕はテスト自体が正しいのか間違っているのかわかりませんでした。 このために、テストのリファクタリング・ドキュメント化を行うように心がけました。 ここで注意すべき点は
- 1つのテスト内では、1つの仕様のテスト
- 必要最低限しか書かない
これによって、テストの意図が分かり易くなり、落ちた場合にもバグなのか仕様が変わったからなのかの判断がしやすくなります。
def test_arrange_correct_order(): """ 記事の並び順はnews->news->journalの順番で出す """ control_items = pd.DataFrame([ dict(user_id=1, item_id='1', item_type='news', rank=1), dict(user_id=1, item_id='2', item_type='journal', rank=3), dict(user_id=1, item_id='3', item_type='news', rank=2), ]) control_test_user = pd.DataFrame([dict(system_cd=1, is_test=True)]) n_top_items_list = ({'item_types': ('news',), 'num': 3}, {'item_types': ('journal'), 'num': 2}) actual = GenerateClass.run(control_items, empty_df, control_test_user, empty_df, empty_df, n_top_items_list) expected = pd.DataFrame([ dict(user_id=1, item_id='1', item_type='news', rank=1), dict(user_id=1, item_id='3', item_type='news', rank=2), dict(user_id=1, item_id='2', item_type='journal', rank=3), ]) pd.testing.assert_frame_equal(actual, expected) def test_arrange_special_item(): """ special_itemは2番目に差し込まれる """ ...
結果
最終的に僕がこのプロダクトを引き継いだ約1年前と比べると以下のように変わりました。
- テストの数: 31 -> 101
- プロダクトの行数: 2173 -> 3388
- テスト行数: 1359 -> 3257
また、このリファクタリングの結果以下のような嬉しいことがありました。
変更に対して自信が持てるようになりアジリティが上がった
コードに変更を加えたい場合、今までは全体への影響が分からずに動作確認に時間を費やしていました。 それが、Testのカバレッジが上がることによって変更への自信が上がりました。 おそらくコードを書いてからリリースまで1.x倍くらいの速度になったと思います。
また、安心して他の人にタスクを任せることができるようになりました。 コード全体の可読性が上がったのでキャッチアップの時間がかなり小さくなったというメリットもありました。
勝手にテストの品質が上がっていった
今までは一つのメソッドのテストを一つのテストの内に全て書くという書き方になっていました。 変更のたびにそのテストへ変更が追加されるため、テストが肥大化していました。 それによって、既存のテストが複雑だから、新しいロジックのテストが書けないというような問題もありました。 それが、一つのテストは一つの仕様について書くという形に変わったおかげで、僕が特に指摘などをしなくても他の人がそれに沿ってテストを書いてくれるようになりました。
僕としては、既存のテストコードが追加しやすく読みやすいだけで、それ以降もテストが綺麗に書かれるというのは新たな発見でした。
さらにその先へ
注意: ここから若干ポエム
僕自身としては社会人半年でそのような手のかかるプロダクトに出会って、テストの大事さやプロダクトの成長の難しさ・引き継ぎの難しさなど学ぶことが出来ました。 この経験を受けて、自分自身としては明日急にチームの他のプロダクトを任せたり任されたりしても全く問題ない柔軟な組織にしたいと強く意識するようになりました。 これは初めて働き始めてから、一緒に働いていた人が残念なことに他の会社に行かれたり、新しいチームメンバーを迎えたりしたことも強く影響していると思います。
そこで最近は以下のような取り組みを積極的に行なっていくようにしています。
学びについて積極的にアウトプットするようになった
社内のtechtalkやチーム内の技術共有会でテストの話などの学んだことを共有しました。 techtalkについてはYouTubeに公開されているので、興味があれば見てみてください。
MLテストの話【M3 Tech Talk 第200回】 - YouTube
チーム内での技術共有会でもテストやドキュメントの話をし、議論をしたりしました。 技術共有会については、インターン生のブログで軽く紹介してくれたりしています。
ドキュメントの整備
チームメンバーの入れ替わりで徐々に失われていく知見についてはドキュメントを残すのが大事だと思います。 また、ドキュメントのレビューや誰が書いたかを辿れるように最近Gitで管理する体制を整え始めています。 今回のプロダクトに対しても、テストだけでは分からないような全体像などをかなり詳しめにドキュメントを整えるようにしました。
まとめ
今回は新卒で引き継いだアラートだらけのプロダクトに対してどのように解消していったかについて書きました。 僕のようにシステムを引き継いだはいいが、アラートがなりまくってもうだめだという人の参考になれば良いかなと思います。
We are hiring!!
弊社では既存のコードをリファクタリングし、プロダクトの成長を加速させるエンジニアを募集しています! 以下のURLからカジュアル面談お待ちしています!