M3 ではグローバル CTO の Brian が、サービスの海外展開や技術基盤の共通化などを積極的に進めています。その中のプロジェクトの1つとして、アメリカで提供している医療ニュースのリニューアルにチャレンジしています。2018 年 5 月には日本オフィス所属のイギリス人エンジニア @christophrowley と日本人のエンジニア (筆者)が 1 ヶ月ほどニューヨークに出張してリニューアルの検討をしてきました。
 ( ↑ Chrisが撮影してくれた NY の写真 )
( ↑ Chrisが撮影してくれた NY の写真 )
今回の記事は、リニューアルで採用を検討している GraphQL を Apollo + JavaScript で作るチュートリアルです。
TL;DR
- Apollo を使って、クライアントサイド、バックエンドを作るチュートリアルを紹介
- 英語・海外での開発に挑戦したいエンジニアを絶賛募集中です。もし興味があればランチ行きましょう!
GraphQL の概要
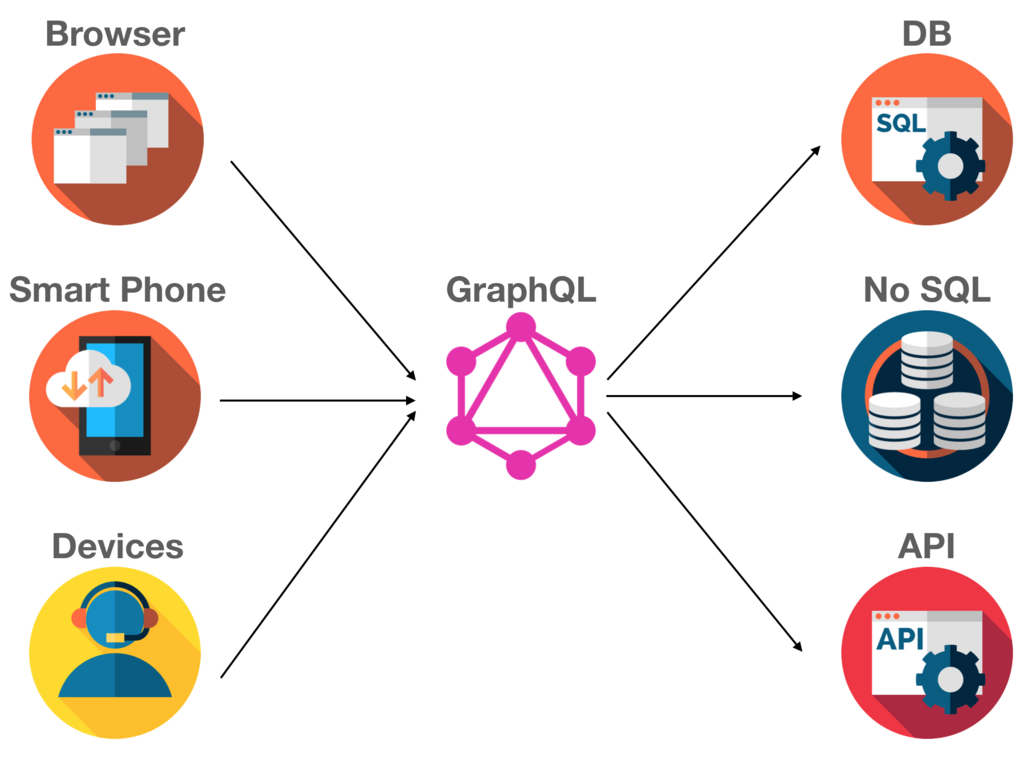
GraphQL は Facebook が発表した、クライアントアプリがサーバから柔軟にデータを取得できるように設計されたクエリ言語です。
GraphQL の概要を知るのに How to GraphQL (英語)がオススメです。GraphQL の初心者向けの説明資料や 40 分ほどの動画を掲載されています。React.js や Ruby での実装チュートリアルなどもあります。GraphQL の概要を知るのに最適なサイトです。
GraphQL にトライ

GraphQL API Explorer では GitHub が公開している GraphQL の API を簡単に試すことができます。GraphQL がいったいどういうものかを触ってみるのにちょうど良いサンプルです。
右上の「Docs ボタン」をクリックすると GraphQL のドキュメントを見ることができるので、参考にしつつクエリを書いてみてください。
GraphQL のメリット
一般的な GraphQLのメリット
GraphQL を採用するメリットは次のようなものがあります。
M3 US におけるメリット
M3 US で GraphQL を採用したいと考えている理由は:
- USの開発チームは人数が少ないため、Contentful や Okta のような外部サービスを利用したい。 GraphQLはそういった外部サービス、既存・新サービスのAPI Gateway として活用できそう
- USは利用者のスマートフォン比率が高いので、バックエンドをGraphQLにしてスマホアプリの開発を加速させたい (バックエンドとフロントエンドが非同期に開発しやすかったり、仕様と一致したドキュメントを整備しやすいなど)
Apollo GraphQL は Meteor.js を開発しているチームが中心となって 開発している GraphQL のための OSS、サービスです。
代表的なツールとしては、
今回は Node.js による GraphQL バックエンドと、GraphQL を使ってデータを表示する React フロントエンドのチュートリアルを紹介します。動作検証はnode.js v8.11.2で行っています。
GraphQL バックエンド
プロジェクトの初期状態の構築
Express.js を使って、GraphQL のバックエンドを構築します。ターミナルで次のコマンドを実行してください。
# プロジェクトのフォルダを作成して移動
mkdir express-graphql && cd express-graphql
# Nodeプロジェクトの初期状態を構築
npm init
# ライブラリをインストール
npm install --save express body-parser cors graphql apollo-server-express graphql-tools graphql-tag
ちなみにインストールしたライブラリは次の通りです。
そしてpackage.jsonのscriptを次のように変更します。
"scripts": {
"start": "node ./index.js"
}
GraphQL サーバアプリの作成
次にindex.jsを作成して次のように記述します。
const express = require("express");
const bodyParser = require("body-parser");
const cors = require("cors");
const { graphqlExpress, graphiqlExpress } = require("apollo-server-express");
const { makeExecutableSchema } = require("graphql-tools");
const books = [
{
title: "Harry Potter and the Sorcerer's stone",
author: "J.K. Rowling",
price: 2000
},
{
title: "Jurassic Park",
author: "Michael Crichton",
price: 3000
}
];
const typeDefs = `
type Query { books: [Book] }
type Book { title: String, author: String, price: Int }
`;
const resolvers = {
Query: { books: () => books }
};
const schema = makeExecutableSchema({
typeDefs,
resolvers
});
const app = express();
const corsOptions = {
origin: "http://localhost:3000",
optionsSuccessStatus: 200
};
app.use(
"/graphql",
bodyParser.json(),
cors(corsOptions),
graphqlExpress({ schema })
);
app.use("/graphiql", graphiqlExpress({ endpointURL: "/graphql" }));
app.listen(4000, () => {
console.log("Go to http://localhost:4000/graphiql to run queries!");
});
module.exports = app;
GraphQL サーバアプリの動作確認
先程作成した Express.js のアプリを起動するために、ターミナルで次のコマンドを実行してください。
npm run start
http://localhost:4000/graphiqlにアクセスできれば成功です。ちなみに、これは GraphQL のクエリを簡単に試すことができる Web 上のエディタです。例えば、
{
books {
title
author
}
}
を左側のペインに入力して再生ボタン(Execute Query)を押すと GraphQL からデータを結果を取得できます。

React フロントエンド
React アプリの初期構築
create-react-app を使って、React フロントエンドのアプリを構築します。ターミナルで次のコマンドを実行します。
# create-react-app のインストール (インストール済の場合はスキップ)
npm install -g create-react-app
# create-react-app を使って、プロジェクトを作成してそのフォルダに移動
create-react-app react-graphql && cd react-graphql
# ライブラリのインストール
npm install
# 動作確認
npm run start
http://localhost:3000 にアクセスして以下の画面が表示されたら成功。

Apollo Client で使うライブラリをインストールして、GraphQL にアクセスできるようにします。
npm install apollo-boost graphql-tag graphql react-apollo --save
GraphQL サーバからデータを取得
次に、./src/App.jsを次のように変更します。
import React, { Component } from "react";
import ApolloClient from "apollo-boost";
import { ApolloProvider } from "react-apollo";
import Books from "./Books";
const client = new ApolloClient({ uri: "http://localhost:4000/graphql" });
class App extends Component {
render() {
return (
<ApolloProvider client={client}>
{}
<div>
<h2>My first Apollo app</h2>
<Books />
</div>
</ApolloProvider>
);
}
}
export default App;
次に、./src/Books.jsを作成して、GraphQL から書籍bookの情報を取得します。
import React from "react";
import { Query } from "react-apollo";
import gql from "graphql-tag";
const Books = () => (
<Query
query={
gql`
{
books {
title
author
price
}
}
`
}
>
{}
{({ loading, error, data }) => {
if (loading) return <p>Loading...</p>;
if (error) return <p>Error</p>;
return data.books.map(course => (
<div key={course.title}>
<p>title: {`${course.title}`}</p>
<p>author: {`${course.author}`}</p>
<p>price: {`${course.price}`}</p>
<hr />
</div>
));
}}
</Query>
);
export default Books;
React アプリの動作確認
作成した React フロントエンドを起動するために、ターミナルで次のコマンドを実行してください。
# React フロントエンド(react-graphql)フォルダで以下のコマンドを実行
npm run start
ブラウザで、http://localhost:3000/にアクセスして、GraphQL サーバのデータを取得できていれば成功です。

GraphQL のパフォーマンスの監視などを行うサービスとして Apollo Engine があります。このサービスは、GraphQL のクエリの実行日時、処理時間、処理時間の内訳、エラーの発生率やキャッシュヒット率などを確認できます。100 万クエリ / 月までは無料で利用することができます。
まずは Apollo Engine の Web 画面からAPI KEYを取得します。

次に apollo-engine と環境変数を管理する dotenv をインストールします。
# Apollo Server(Express.js)のフォルダへ移動
cd express-graphql
# apollo-engine dotenv をインストール
npm install --save apollo-engine dotenv
# .env に先程取得したAPI KEYを設定
echo "APOLLO_ENGINE_API_KEY=XXX" > .env
Apollo Server(Express.js)のプロジェクトのindex.jsを次のように変更。
require("dotenv/config");
const express = require("express");
const bodyParser = require("body-parser");
const cors = require("cors");
const { ApolloEngine } = require("apollo-engine");
const { graphqlExpress, graphiqlExpress } = require("apollo-server-express");
const { makeExecutableSchema } = require("graphql-tools");
const { APOLLO_ENGINE_API_KEY } = process.env;
const books = [
{
title: "Harry Potter and the Sorcerer's stone",
author: "J.K. Rowling",
price: 2000
},
{
title: "Jurassic Park",
author: "Michael Crichton",
price: 3000
}
];
const typeDefs = `
type Query { books: [Book] }
type Book { title: String, author: String, price: Int }
`;
const resolvers = {
Query: { books: () => books }
};
const schema = makeExecutableSchema({
typeDefs,
resolvers
});
const app = express();
const corsOptions = {
origin: "http://localhost:3000",
optionsSuccessStatus: 200
};
app.use(
"/graphql",
bodyParser.json(),
cors(corsOptions),
graphqlExpress({ schema })
);
app.use("/graphiql", graphiqlExpress({ endpointURL: "/graphql" }));
const engine = new ApolloEngine({
apiKey: APOLLO_ENGINE_API_KEY,
stores: [
{
name: "inMemEmbeddedCache",
inMemory: {
cacheSize: 104857600
}
}
],
logging: {
level: "INFO"
}
});
engine.listen({
port: 4000,
expressApp: app
});
module.exports = engine;
これで Express.js を再起動して、画面をリロードしてみます。ターミナルで以下を実行してください。
# express-graphqlフォルダで npm run start を実行したターミナルでCtrl + C 。その上で再度以下を実行
npm run start
そうすると Apollo Engine にパフォーマンス情報などを送信するようになります。React側の画面にもう一度アクセスをしたあとに数秒おいて Apollo Engine をリロードしてみてください。
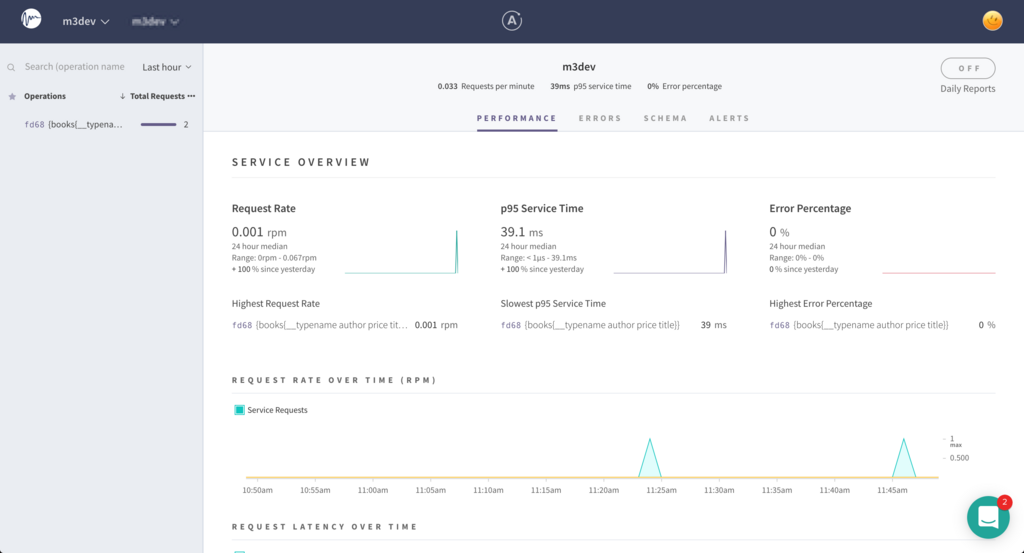
実際に GraphQL の API を運用する場合はこういった情報を使ってパフォーマンスを計測したり、必要に応じてリゾルバやキャッシュの改善を行う必要があると考えています。
今回の チュートリアルのコードを GitHub に公開しています。良ければ参考にお使いください。
https://github.com/m3dev/graphql-apollo-sample
今後の課題
今回のチュートリアルでは GraphQL の API を簡単に構築できることを紹介しました。実際に本番で運用する場合には次のような課題を検討・解決していく必要があると考えています。
- AWS App Sync のような仕組みを使うべきか、自前で GraphQL アプリを開発すべきか?
- 不特定多数のクライアントに GraphQL の API を公開する場合は、クエリの実行権限管理や事前にクエリのコストを見積もる仕組みの整備が必要
- Web 画面のフォームのバリデーションと、GraphQL 側のバリデーションをどう整合性を取るか?などのアプリ開発での実践的なノウハウ
海外で一緒に働いてもらえるエンジニアを募集中
M3 ではアメリカやイギリス(EU)のビジネスの拡大に伴い、一緒に働いてもらえるエンジニアを募集しています!
また社内や グループ会社の メビックス でもGraphQL や Vue.js を使ったプロジェクトが着々と進行中です!GraphQLの開発に興味がある方もぜひ エンジニア向けフォーム からお気軽にご連絡ください!
GraphQL 関連のおすすめサイト

Apllo を開発しているチームの Blog (英語)です。セキュリティやキャッシュ、負荷対策など GraphQL を本番で使うために必要な実践的な知識を紹介してくれており、大変参考になります。
おまけ:便利そうなサービス・ツール
その他、GraphQL を調査している段階で面白そうなサービスをいくつか見つけたのでその紹介です。
Prisma & graphql-yoga
Postgraphile
PostreSQL のフロントで GraphQL を提供してくれる OSS、既存の DB に対して簡単に GraphQL を提供できるのが面白い。
参考リンク














