
こちらはエムスリー Advent Calendar 2023 1日目の記事です。
Overview
エムスリーエンジニアリンググループ AI・機械学習チームでソフトウェアエンジニアをしている中村(po3rin) です。趣味は麻雀でフリー雀荘で毎年200半荘以上打ちます。好きな麻雀プロは園田賢さんです。
麻雀を始めるときに一番の障壁になるのは点数計算ではないでしょうか? 特に符計算が初心者の関門のようです。一方私のような初中級者でも突然のレアな点数申告にまごつくことがあります。
そこで、今回はその人に合った麻雀の点数計算問題(主に符計算が焦点となる問題)を生成して、自分で点数計算&点数申告の練習をする方法を探求したのでその紹介をします。麻雀用語が少しだけ登場するので、対象読者は麻雀を少しでもかじったことのあるエンジニアの方です。
- Overview
- 麻雀の点数計算の難しさ
- 現状の点数計算の練習方法の課題
- 今回作った点数申告練習システム
- 麻雀の点数計算問題を自動生成する
- 点数申告を発声で回答する
- 文字起こし微修正
- Future Work
- 小噺: ChatGPTで麻雀点数計算問題生成
- まとめ
麻雀の点数計算の難しさ
麻雀はアガリの形によって点数が決まります。アガリの形から飜数と符数を導き、下記の表を参照して相手にアガリの点数を申告します。下記は1 ~ 4飜、20 ~ 70符の点数の表です(もちろん5飜以上、80符以上の点数も存在します)。
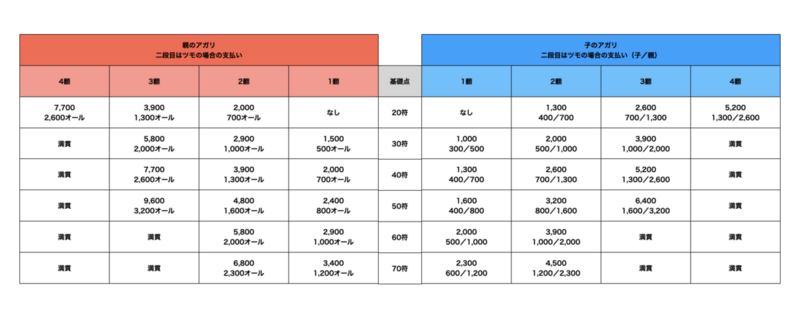
覚えるだけなら難しくなさそうですが、麻雀中は飜や符の計算を即座にリアルタイムで行う必要があるため、初心者が即座に点数申告をするのは時間がかかります。特に符の計算は間違えやすく、最も麻雀の敷居を高くしている要因だと考えています。
現在、麻雀点数計算に慣れるために様々な練習方法がありますが、それぞれ課題があると考えています。
現状の点数計算の練習方法の課題
書籍
書籍は点数計算の方法が体系的に学べるのでゼロから始める初心者にはおすすめです。最近では下記の書籍のように書いて覚える系が多い印象です。
")
こちらの本では飜数や符数を確認しながら、点数を記入して練習できるようです。
しかし、これだけだと点数だけを答えるリアルでの点数申告(飜数などを申告せず、子や親が払う点数だけを発声する)の感覚が身につきません。リアルな点数申告の感覚を得るためには、現状は雀荘に行って実際に打って練習する必要があります。例えば子の満貫は子から2000点、親から4000点をもらうので「にせんよんせん」と発声します。このように点数を子と親からもらう用の言い方に変換する必要があります。
アプリ
僕が現在、麻雀初心者にオススメしているアプリはこちらです。

「麻雀点数計算 超 実践問題集」は「4飜以下50符以上」などの条件をつけて簡単or難しい問題に絞って問題を解くことができます。しかし、こちらのアプリでは「4飜以下50符以上」が必ず出題されることがわかってしまうので、リアルの麻雀とは少しかけ離れた思考になってしまい、本番でケアレスミスが増えます。
また、書籍の課題と同じように回答方法が4択の選択式だったりするので、リアルでの点数申告(飜数などを申告せず、子や親が払う点数だけを発声する)の感覚が身につきません。
そこで、自分としては「出題範囲の条件はないが、その人のレベルにあった問題が確率的に出題される」ことと「リアルでの点数申告に合った回答方法」が必要なのではないかと考えています。
実際に打って覚える
リアルでの点数申告が行えるので、最も練習になりますが、麻雀を打つ頻度が少ないと中々身につきません。リアルな点数申告方式で、回数をこなせる方法が必要だと自分は考えています。
...
ここまでで挙げた書籍やアプリの課題から、私の考える最強の麻雀点数計算問題出題システムは下記を備えたものだと考えています。
- リアルでの点数申告に沿った回答方法(発声)
- 出題範囲の条件はないが、その人のレベルにあった問題が確率的に出題される
- 高速に大量の問題数をこなすことができる
今回作った点数申告練習システム
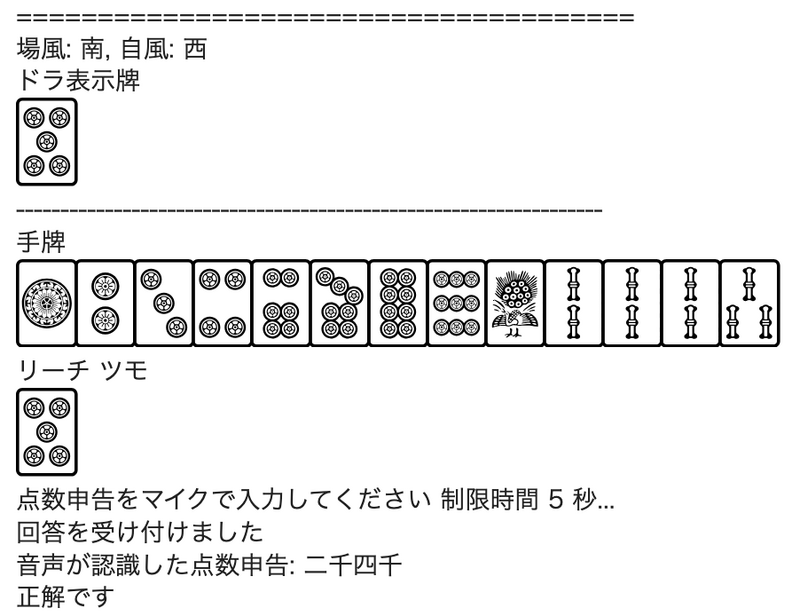
そして今回作ったものがこちらになります。Google Colabratory上で動作します。
こちらを実行すると下記のように計算問題を表示して、点数申告の発声をレコーディングして正解不正解を判定します。
麻雀の点数計算問題を自動生成する
麻雀点数計算問題出題システムを作るためには出題元となる問題集が必要になります。どこかに問題集がコードから利用できる形で公開されてないかと考えましたが、そのような便利なものは私が調べた範囲では無いようです。
麻雀アプリである天鳳などの対局ログからアガリ形を抽出して、問題集としても良いですが、中級者以上が練習したいレアなアガリ(80符以上など)は数が少なく、下記のサイトの調べでは3%しか出現しないようです(体感この数字も大きすぎる気がしますが...)。
そのため、天鳳の対局ログから問題集を作成するためには、過去数年分の大量のログをロードしなくてはいけないため、時間がかかります。そこで私は麻雀の点数計算問題の自動生成に取り組みました。これで目標の1つである「問題数に限りがほとんどない」が達成できます。
今回私が作ったPythonによる点数計算問題の自動生成モジュールはOSSで公開しています。
from mahjong_question_generator import generate_question df = generate_question(n=3) # 3問生成 print(df)
こちらのDataFrameでは出題に必要な以下の情報を含んでいます。
round_wind: 場風 player_wind: 自風 hand: 手牌 win_tile: アガリ牌 dora_str: ドラ表示牌 is_riichi: リーチの有無 is_tsumo: ツモの有無 is_haitei: ハイテイの有無 is_houtei: ホウテイの有無 hand_value_han: アガリの飜数 hand_value_hu: アガリの符数 hand_value_cost_additional: 子が払う点数 hand_value_cost_main: 親が払う点数(ロンの場合は振り込んだ人がが払う点数) hand_value_yaku: アガリ役のリスト
これだけの情報があれば下記のようにNotebookで問題が出題できます。
import time import pandas as pd from IPython.display import display from cmajiang import Shoupai from mahjong_question_generator import generate_question df = generate_question(n=3) # 3問生成 questions = df.to_dict('records') for q in questions[:3]: print('======================================') print(f'場風: {q["round_wind"]}, 自風: {q["player_wind"]}') print('ドラ表示牌') display(Shoupai(q['dora_str'])) print('------------------------------------------------------------------') print('手牌') display(Shoupai(q['hand'])) print('リーチ' if q['is_riichi'] else '', 'ツモ' if q['is_tsumo'] else 'ロン', '海底摸月' if q['is_haitei'] else '', '河底撈魚' if q['is_houtei'] else '') display(Shoupai(q['win_tile'])) print(f'正解は {q["hand_value_han"]}飜{q["hand_value_hu"]}符, {q["hand_value_cost_additional"]}, {q["hand_value_cost_main"]}です。') print(f'役: {q["hand_value_yaku"]}')
実装のポイント
メンツのパターンを重み付きランダムサンプリングして難易度を調整
今回は特に符計算に焦点を当てているため、出現するメンツの種類で難易度を調整しています。難しい点数計算が絡む時は暗刻やカンが入っているため、その出現率で難易度が調整できます。
TILE_PATTERN = ['run', 'triple', 'chi', 'pon', 'kan'] DEFAULT_TILE_PATTERN_WEIGHTS = [4,1,1,1,1] def hand_candidates(tile_pattern_weights: list[int] = DEFAULT_TILE_PATTERN_WEIGHTS) -> dict: mentsu_list = random.choices(TILE_PATTERN, weights=tile_pattern_weights, k=4) # ... 省略
役のある手牌を強引に作る
点数計算問題を作成する際に、役がある手牌を最初から狙って生成するのは少し難しいので、メンツや鳴きやアガリ牌をランダムで生成して、最終的に役がなければ強引にハイテイやホウテイの役をつけています。
# ... 関数の一部を抜粋 # 点数計算 hand_value = calculator.estimate_hand_value(tiles, win_tile, melds, dora_indicators, config) # 役がなかったら強制的に役をつけて再計算 if str(hand_value) == 'no_yaku': is_haitei = is_tsumo and not is_riichi is_houtei = not is_tsumo and not is_riichi config = HandConfig(is_tsumo=is_tsumo, is_riichi=is_riichi, is_haitei=is_haitei, is_houtei=is_houtei, player_wind=player_wind, round_wind=round_wind, options=OptionalRules(has_open_tanyao=True, kiriage=True, kazoe_limit=HandConfig.KAZOE_SANBAIMAN)) hand_value = calculator.estimate_hand_value(tiles, win_tile, melds, dora_indicators, config) # ...
これで役がない手牌も問題として拾うことができます。特に今回のように符計算に重きを置いた出題ではハイテイだろうとホウテイだろうとリーチだろうとあまり難易度に影響がないので、この強引な方法で許容しています。この回避策に違和感を感じるならば、「手牌に役がなければその手牌は捨てて、役がある手ができるまで生成する」という設定にすれば良いでしょう。
majiang-coreで手牌を描写できる形式で出力する
今回は問題の出題に手牌やアガリ牌、ドラ表示牌に画像が使いたかったので下記のモジュールを使っています。
こちらはインターネット麻雀である電脳麻将内部で使われている手牌表現をサポートしているため、文字列を渡せばですぐに画像を出力できます。
cmajiangは下記のようにSVGで非常に綺麗に牌を描写できるのでおすすめです。

点数申告を発声で回答する
リアルに近い形の点数申告に寄せるために、点数申告発声で回答を入力したいので、ユーザーの発声をレコーディングして、文字起こしして解答と一致するかをチェックします。
文字起こしサービスとしてGoogleのCloud Speech-To-Text APIやOpenAIのWhisperなどがあります。しかし、今回の趣味開発の域では無料で実行したいところです。そこで今回は音声処理ツールキットOSSのESPnet2と既存の学習済みモデルを使って文字起こしを行いました。
文字起こし
まずはGoogle Colaboratory上で発声をレコーディングする方法です。下記はESPnet2のデモスクリプトから拝借しました。
from IPython.display import Javascript from google.colab import output from base64 import b64decode RECORD = """ const sleep = time => new Promise(resolve => setTimeout(resolve, time)) const b2text = blob => new Promise(resolve => { const reader = new FileReader() reader.onloadend = e => resolve(e.srcElement.result) reader.readAsDataURL(blob) }) var record = time => new Promise(async resolve => { stream = await navigator.mediaDevices.getUserMedia({ audio: true }) recorder = new MediaRecorder(stream) chunks = [] recorder.ondataavailable = e => chunks.push(e.data) recorder.start() await sleep(time) recorder.onstop = async ()=>{ blob = new Blob(chunks) text = await b2text(blob) resolve(text) } recorder.stop() }) """ def record(sec, filename='audio.wav'): display(Javascript(RECORD)) s = output.eval_js('record(%d)' % (sec * 1000)) b = b64decode(s.split(',')[1]) with open(filename, 'wb+') as f: f.write(b)
これでrecord関数を呼べば、指定時間だけ録音をしてwavファイルとして保存できます。
続いて、この音声ファイルを文字起こしします。
from espnet_model_zoo.downloader import ModelDownloader
from espnet2.bin.asr_inference import Speech2Text
d = ModelDownloader()
speech2text = Speech2Text(
**d.download_and_unpack("kan-bayashi/csj_asr_train_asr_transformer_raw_char_sp_valid.acc.ave"),
device="cuda"
)
speech, sr = librosa.core.load("audio.wav", sr=16000)
nbests = speech2text(speech)
text, *_ = nbests[0]
これでGoogle Colaboratory上でレコーディングしたユーザーの回答を文字起こしできます。
文字起こし結果と比較可能な形に正解側を変換する
ここでひとつ問題があり、上記のコードで文字起こしを行うと発声した点数が漢字で文字起こしされてしまいます。
例えば「1300 2600」の発声は「千三百二千六百」と文字起こしされます。この漢字の並びをパースするのは面倒なので、mahjong-question-generatorで生成した正解側を漢字にすることで比較可能な形にします。intを漢字の文字列に変換する際にはkanjizeというモジュールを利用します。
from kanjize import number2kanji def convert_answer_for_voice_assertion(q: dict) -> str: # 音声データと比較するための回答を用意 if q["hand_value_cost_additional"] == 0: # ロン answer_for_voice_assertion = number2kanji(q["hand_value_cost_main"]) elif q["hand_value_cost_additional"] == q["hand_value_cost_main"]: # 親のツモあがり answer_for_voice_assertion = number2kanji(q["hand_value_cost_main"]) + 'オール' elif q["hand_value_cost_additional"] != 0: # 子のツモあがり answer_for_voice_assertion = number2kanji(q["hand_value_cost_additional"]) + number2kanji(q["hand_value_cost_main"]) return answer_for_voice_assertion
これでanswer_for_voice_assertion変数に文字起こしと比較可能な文字列を取得できます。
文字起こし微修正
点数申告の文字起こしそのままだと、「千」が「ん」に認識されることが多かったので、手元で微修正を加えています。下記の修正で大体の点数申告は問題なく文字起こしできるようになりました。
def adjust_speech(speech: str) -> str: # 「千」が「ん」にされることが多い if text == "ん": text = "千" # たまに「ん」が入り込む if 'ん' in text: text = text.replace('ん', '') return text
一旦この対応にとどまっていますが、点数申告は基本的に漢字で文字起こしされるので、ひらがなや記号を削除するなど大胆な調整にしても良いかもしれません。
Future Work
今回は問題をPythonで生成してGoogle Colaboratoryで問題を出すところまでを実装しました。
ここからはネイティブアプリ化や強化学習でそのユーザーが間違えやすい問題を出すように進化していくなどが考えられます。
小噺: ChatGPTで麻雀点数計算問題生成
最初はChatGPTで点数計算問題を生成できるかと思いましたが、全然うまくいきませんでした。
プロンプト: 回答が「親のロンあがりで2翻50符4800点」となる麻雀の点数計算問題を作ってください。符計算ができる問題にしてください。実際に手牌が並んでいる例を文字列で表現してください。 回答: 親が次のような手牌でロンあがりしました。 手牌:「東東東」、「發發發」、「2萬3萬4萬」、「5索6索7索」、対子が「赤ドラ」 アガリ牌:「4萬」 この場合、役はリーチ、一発、ドラ1となります。この時の点数を計算してください。
ChatGPTが作った問題は解答が12000の問題なのでオーダーとは違います。他にも何回かプロンプトを試行錯誤してみましたが全然うまくいきませんでした。ChatGPTで麻雀関連の質問をするのはまだ早そうです。
まとめ
今回は麻雀の点数計算問題をPythonで自動生成して、実際に発声して点数申告の練習をする方法を探求しました。みなさんもエンジニアリングで麻雀ライフをより良いものにしていきましょう。
We are hiring
エムスリーでは趣味をエンジニアリングでごりごりハックするようなギークなエンジニアを随時募集中です。軽く話を聞いてみるだけでも OK ですので、ぜひともカジュアル面談をお申し込みください!