こんにちは! エムスリーエンジニアリンググループ、 SRE の平岡(@uhtter)です。 こちらは エムスリー Advent Calendar 2021 の14日目の記事になります。
私がエムスリーに入社してから3年経ちました。 エムスリーではこの3年間の間に、チームSREの文化が誕生・醸成し、クラウド移行(=脱オンプレ)の活動が盛んに行われてきました。 その結果、インフラの全体像も変化を重ねていくこととなり、それに伴い IaC の構成も大きく変わっていきました。 この記事ではその変遷を辿っていきながら、今後のインフラの展望について考えてみたいと思います。

3年間のタイムライン
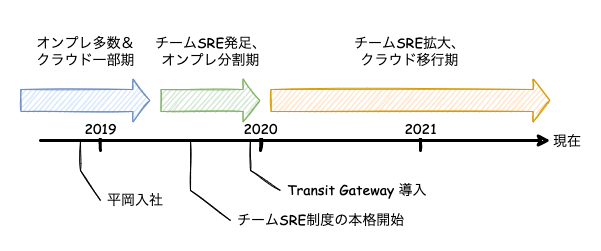
2018 年頃から現在までのエムスリーのインフラ管理を振り返ると、大きく分けて3つの時期があったように感じます。
- オンプレ多数&クラウド一部期(〜2019年初)
- チームSRE発足、オンプレ分割期(2019年中〜2020年)
- チームSRE拡大、クラウド移行期(2020年〜現在)
やはり大きな契機となったのは、 チームSRE の制度です。 チームSREとは、エムスリーの各ビジネスユニットに対応するエンジニアチーム内からアサインされたSREメンバーの通称です。 それまでのSREチームは、特定のユニットに紐付かない横断チームとして存在していましたので、今では(チームSREに対して)コアSREとして区別して呼ばれるようになっています。 チームSRE制度の導入背景については、 こちらの記事 で端的に説明されています。
チームSREの制度が発足し、広がっていく中で、エムスリーのインフラ管理は様変わりしていったように感じます。 以降では、上記のそれぞれの時期がどういった状況だったのかについて振り返ってみたいと思います。
1. オンプレ多数&クラウド一部期
私が入社した2018年末から2019年の段階では、オンプレで多数のサービスが密に連携しており、一部のチームで例外的にクラウドが使われているような状況でした。 オンプレのインフラのコードは、単一の巨大なリポジトリ*1 に各種オンプレサーバの ansible playbook がまとめて管理されている、といった状況でした。
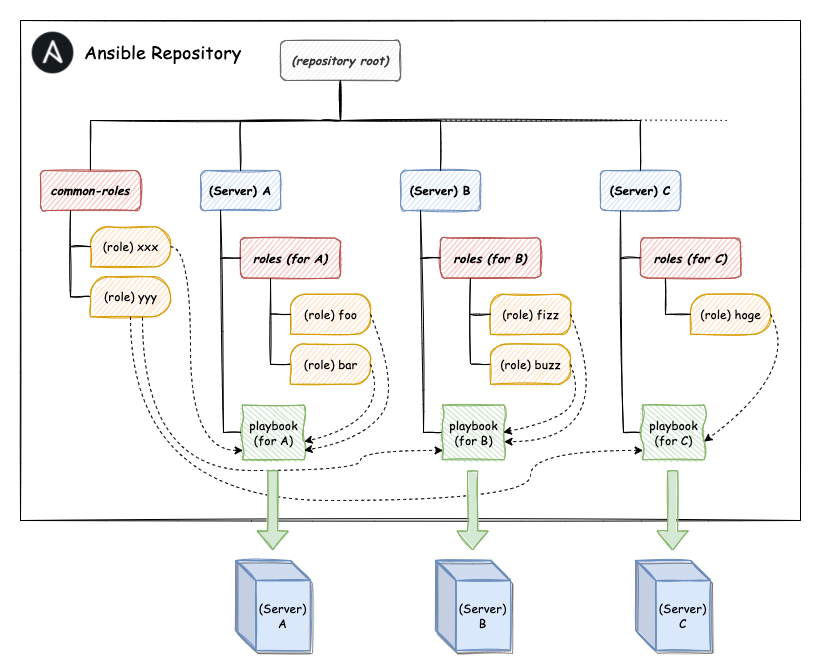
オンプレサーバの ansible リポジトリでは、サーバー間で共通の設定が role として共有され、その中でOSの種類・バージョンの違いを吸収していました。 それらを再利用しながら、各サーバ固有の設定がそれぞれの playbook と role で管理されていました。 この構造は現在でも存在しているオンプレサーバでも維持されており、毎日のように変更されて使われています。
この時期の IaC における課題感として、 ansible で管理できていないレガシーなオンプレサーバのインフラ管理をどうするか、というのが最も大きかったように思います。 ansible のリポジトリがあると言っても、全てのサーバのインフラをコード化できているわけではなく、既にサービスが長期運用されているサーバのインフラを紐解いてコード化していく作業は、大変な労力を伴うものでした。 と言いつつ、「インフラはインフラチームの後継である SRE チームが管理し、サービスを各ユニットチームが開発する」という当時の状況には、シンプルにマッチした構成だったように感じます。
また、クラウドインフラの IaC については、「AWS だったら Terraform が良いのか? CloudFormation が良いのか?」「GCPは何が良いのか?」といった話がクラウドを多用しているチームで議論されている段階で、全体の傾向や方針は明らかになっていませんでした。
2. チームSRE発足、オンプレ分割期
2019年の中頃から、チームSREの推進活動が組織のミッションとして始まりました。 その結果、それまでの SRE チームのメンバーはコア SRE となり、新たに各ユニットチームにチームSRE のメンバーがアサインされるようになりました*2。
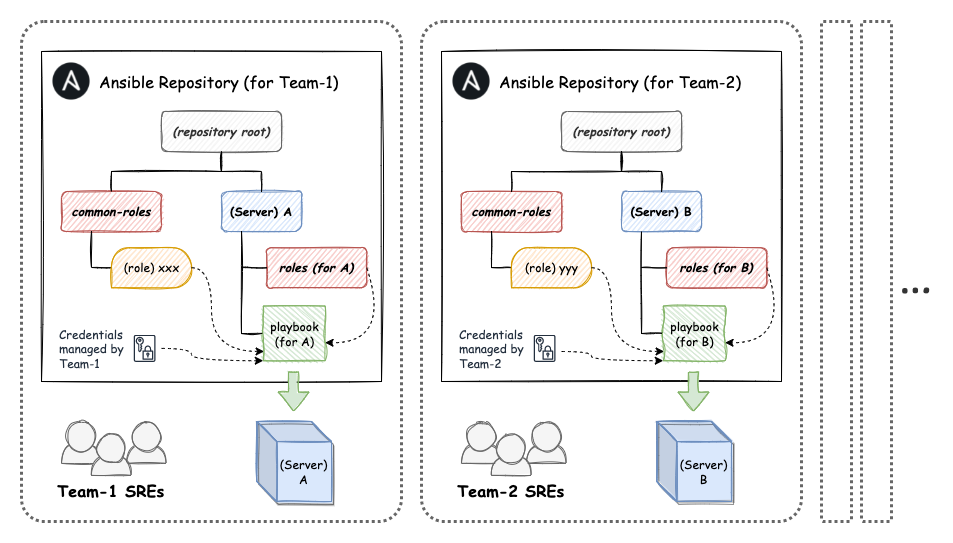
チームSRE 制度が始まったことで、必然的に、オンプレサーバの IaC のコード管理についてもチーム SRE に移譲できることが望まれるようになりました。 ここですぐに思いつくのは「これまで使ってきた(単一の) ansible リポジトリをチームSREでも編集できるようにする」という方法ですが、ここで課題となったのが「 IaC のコードに含まれるDB接続情報などのクレデンシャルをどう扱うか?」ということでした。 playbook に記述されているインフラの構成情報だけであれば、各チームのチームSREメンバーに公開・共有しても問題ありませんが、クレデンシャルについては参照・変更できる権限を厳密に管理する必要があります。 当初から様々なクレデンシャルを Ansible Vault で暗号化して管理していましたが、それらのパスワードを複数チームのチームSREを跨ってうまく管理するのは、将来的に複雑化することが目に見えていました。
そのため、単一の ansible リポジトリにまとまっていた playbook を各チーム用の ansible リポジトリとして分割することになりました。 各チームのチームSREには分割した ansible リポジトリのオーナーシップを持ってもらい、今後はチーム内でインフラを管理してもらうことになりました*3。 懸念されていたクレデンシャルについてはそれぞれのチームSRE(とコアSRE)だけが知っている新しいパスワードで再暗号化することで、チーム毎に権限を分けて管理できるようになりました。
3. チームSRE拡大、クラウド移行期
2019年の中盤の時点では、主にネットワーク的に独立できるサービスを新規開発する場合に限って、クラウドでのインフラ構築が選択されていました。 2019年終盤にオンプレと AWS とのネットワークに Transit Gateway (+Direct Connect)が導入されたことで、この状況が大きく変わりました。 こちらの記事 で刷新されたネットワーク環境の一部が紹介されています。
プライベートネットワークの境界を維持したままクラウド上でサービスを運用できるようになり、オンプレ環境で運用されている既存サービスを、他サービスとの連携を保ったままクラウドに移行できるようになりました。 これによって、(1)チームSREがクラウド上にインフラを新規構築し、(2)オンプレ&クラウドでサービスを並列に動作させ、(3)外部流入の経路をオンプレからクラウドに切り替える、といったような安定したパターンが成立するようになり、クラウド移行のハードルが大きく下がりました。
チームSREがクラウド上にインフラを構築する機会が大きく増えたことで、 IaC の実践領域もクラウドに移行していくこととなりました。 エムスリーではチーム毎に自由に技術選定する文化があり、この時点での AWS インフラ管理の全体傾向として Terraform が多く利用されていたため、各チームで Terraform リポジトリが構築・運用されるようになりました*4。
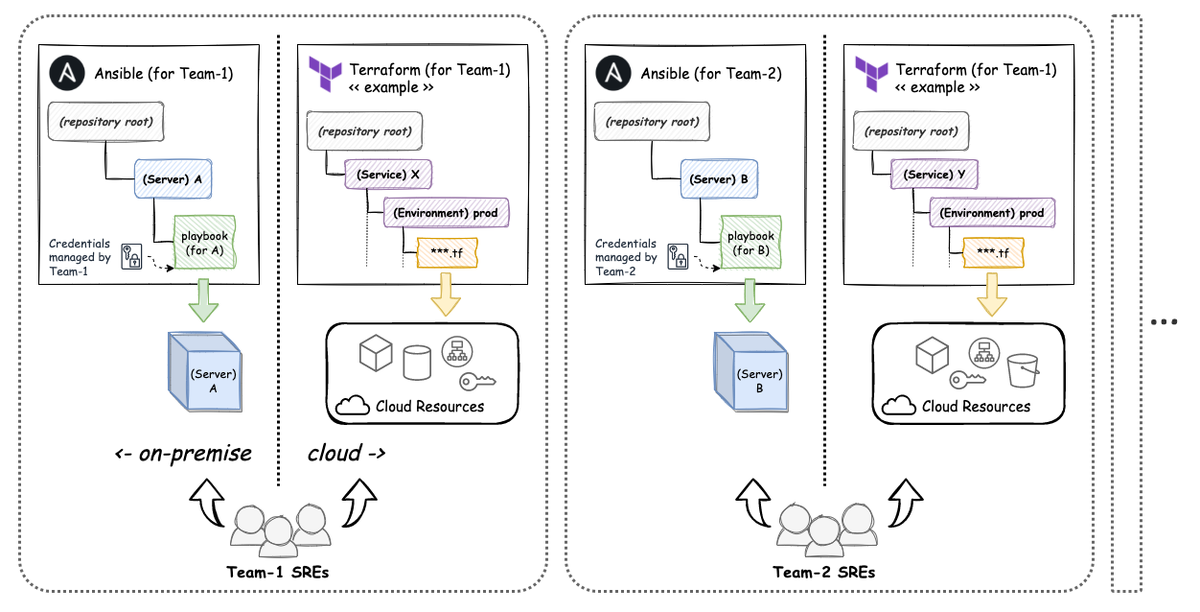
図ではチーム毎に単一の Terraform リポジトリがあるように表現していますが、実際のリポジトリ構成は各チームに完全に委ねられていますので、サービス毎に別のリポジトリにしている場合も多いです。 サービス自体のリポジトリとサービスを運用するインフラのリポジトリとでそれぞれ CI を実装できるようになったため、チームSREは、チーム内で自分らのデプロイプロセスを改善したり、インフラのサイジングを見直したりできるようになっています。
こういった変遷の結果、2021年12月現在、コアSREとチームSREとで凡そ以下のようにインフラ管理が分担されるようになり、それぞれで IaC が実践されるようになっています。
- チームSRE管理
- チームSREがクラウドに移行、あるいは新規構築して運用されているサービスの Terraform
- サービス間の連携などの都合により、まだオンプレでの運用を継続しているサービスの ansible
- コアSRE管理
- 先に紹介したオンプレ↔クラウドのネットワーク基幹設定や、CI実行基盤などの、全てのチームで横断的に利用されるものの Terraform
- インフラの監視基盤などの、オンプレで共通利用されているサーバの ansible
- その他、特別な事情でチームSREに権限移譲できないサーバの ansible
従来からあった、「コアSREが共通の仕組みを提供し、各チームが自らのサービスを自主的に開発する」という組織の機能分担が、インフラ管理についても言えるようになってきている、というのがエムスリーの現在の形です。
エムスリーのインフラこれから
ここまで、3年間で3つの期間がはっきりと分かれているような体で説明しましたが、実際はそれぞれの期間の状況が並行して存在しており、ずっと過渡期であり続けています。 複数のインフラ施策が並列で進んでいるため、全体のインフラ管理としてはオンプレ・クラウドの双方で新旧入り混じった状態が続いています。
……とだけ言ってしまうと良くないように聞こえてしまうかもしれませんが、実際は、旧い環境をできるだけ少ないコストで刷新するため、その時とれる最善の施策を段階的に進めている、というのが真実です。 インフラの全てが均一な状態になることは理想ではありますが、時間が経つことでその状態が一気に陳腐化しかねないという点で、継続的な改善を続けている状態こそが健全であるように思います。 月並みな言葉ではありますが、「運用を継続しながら、理想的な状態を目指して地道に改善を積み重ねていく」というのが、この3年を経て学んだインフラ管理の基本的姿勢だと思っています。
さて、 2022年以降のエムスリーのインフラ改善のテーマは「クラウド移行 第二弾」として、サービスで共用・集約されているデータストアの分割とクラウド移行を進めていこうとしています。 また、クラウドへの依存が強くなっていく一方、クラウドでの障害発生時のダメージをいかに減らせるか、ということも、近い将来のテーマになっていくのではと感じています。 エムスリーでチームSREが当たり前の存在となった今、コア/チームSREの各々がインフラの改善に自ら取り組んでいくことで、組織全体の SRE 力を高めていきたいと思います!(自分も頑張ります!)
We are hiring!
というわけで、エムスリーではサービスの開発とそのインフラの継続的な改善に取り組みたいエンジニアを募集しています。 我こそはという方は、ぜひとも以下のリンクからお問い合わせ下さい!
*1:調べてみたところ First Commit は 2014/3 でした。 Ansible Advent Calendar 2014 を見てみると当時の雰囲気がわかって面白いです。
*2:と言っても、すぐに全てのユニットチームでチーム SRE がアサインされたわけではなく、既存メンバーのインフラスキルが十分にありそうな数チームから始まり、徐々に他チームにも導入されていきました。
*3:とは言え、みんながみんな ansible の利用経験があるわけではなかったため、コアSREが手助けしながら徐々に管理を担ってもらえるように進めました。
*4:GCP については一部のチームで多用されてこそいますが、こと IaC の点に関して言うと、現在でも明確な傾向は現れていないように感じます。