
エムスリーエンジニアリンググループ AI・機械学習チームでソフトウェアエンジニアをしている中村(po3rin) です。検索とGoが好きです。
最近エムスリーでは迅速かつ簡単に実装できるという観点から情報検索(IR)にバンディットアルゴリズムを適用する施策が進行中です。その過程でCascade Modelに多腕バンディットを適用したアルゴリズムを調べたので、Pythonによる実装とともに紹介していきます。
Introduction
バンディットアルゴリズムは迅速かつ簡単に実装でき、トレーニングデータを必要とせず、継続的なテスト/学習が可能であるため、あらゆるオンラインアプリケーションで適用される人気の高い手法です。
しかし、IRにバンディットアルゴリズムを適用しようとする場合、少し工夫する必要があります。その際の1つの方法がCascade Modelを仮定した上でのバンディットアルゴリズムの適用です。
IR×多腕バンディットについてはICTIR '17のチュートリアル[1]が非常に勉強になるのでおすすめで、Cascade Model以外にも様々なトピックに触れられています。今回はこちらで紹介されているアルゴリズムを中心に紹介していきます。
https://dl.acm.org/doi/10.1145/3121050.3121108
事前知識
この記事では、基本的な多腕バンディットアルゴリズムであるUpper Confidence Bound(UCB)アルゴリズムとThompson Sampling(TS)についての理解がある前提で進めます。
UCBやTSの解説にはさまざまな書籍やブログが大量にあるのでそちらを参照していただくのが良いでしょう。私のおすすめはPythonの実装もついている「ウェブ最適化ではじめる機械学習」です。

Cascade Model とは
Cascade Model は結果リストを順位の高いアイテムから順番に走査していくことを仮定したモデルでCraswell[2]らによって提案されました。さらに強力な仮定として、ユーザーがアイテムを好んでいた場合は必ずクリックを行い、その後の順位に並んでいるアイテムは全てユーザーに走査されないことを前提としています。後ほど詳しく見ていきますが、このモデルによりポジションバイアスを扱うのが簡単になります。
概要図は下記になります。この例ではユーザーがアイテム3をクリックしたのでアイテム4とアイテム5はユーザーに走査されません。
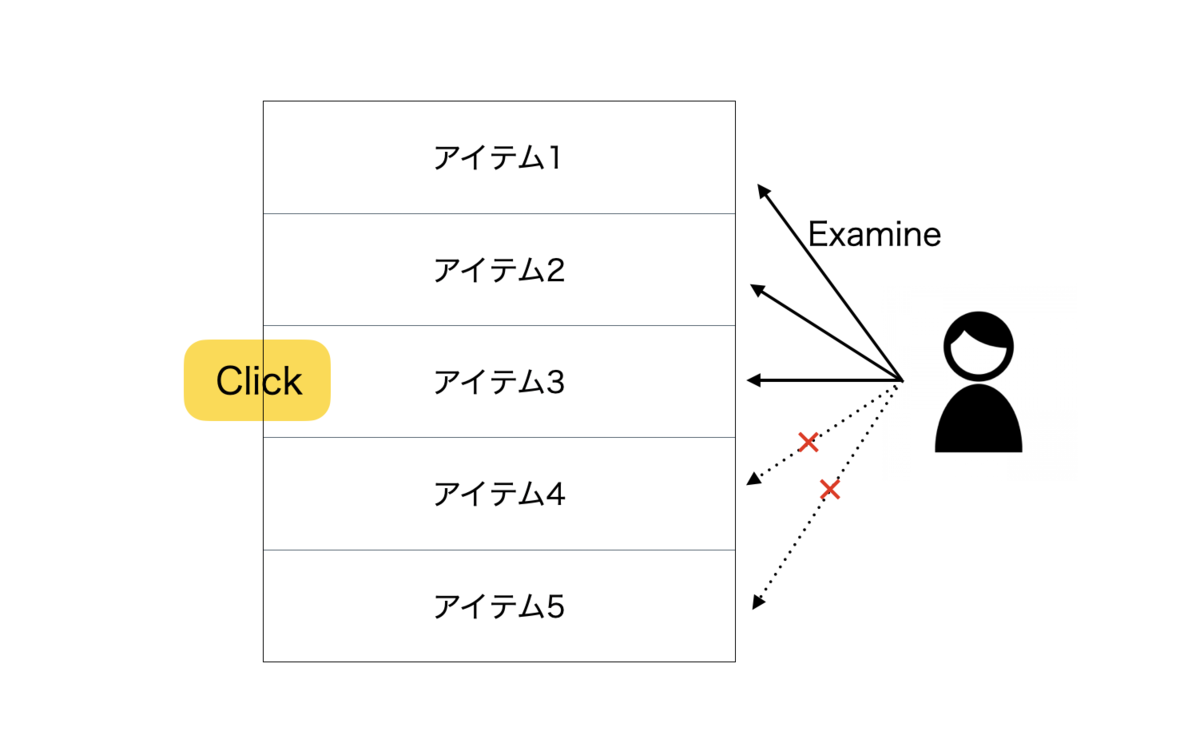
Cascade Modelは単純ですが、過去のクリックデータの位置バイアスを説明するのに効果的として多くのアルゴリズムのモデルとして採用されています。
全アイテム集合の中から
個のアイテムを選びランキングしたものを
とし、これをユーザーに表示する検索結果とします。
をアイテム
がユーザーにとって好みである確率(ここでは誘引確率と呼ぶ)とします。誘引確率は今回の設定ではクリック率です。
そうすると、がユーザーに走査される確率は
となります。よって、少なくとも1つのアイテムがクリックされる確率は
となります。
Cascade Model に適用する多腕バンディット
この章ではCascade Modelに適用する基本的な多腕バンディットアルゴリズムであるCascadeUCB1と、アイテムの特徴量を考慮するCascadeLinTSの2つを紹介します。
Cascading Bandits
Cascade Modelに多腕バンディットアルゴリズムを適用することを考えます。概要図は下記のようになります。
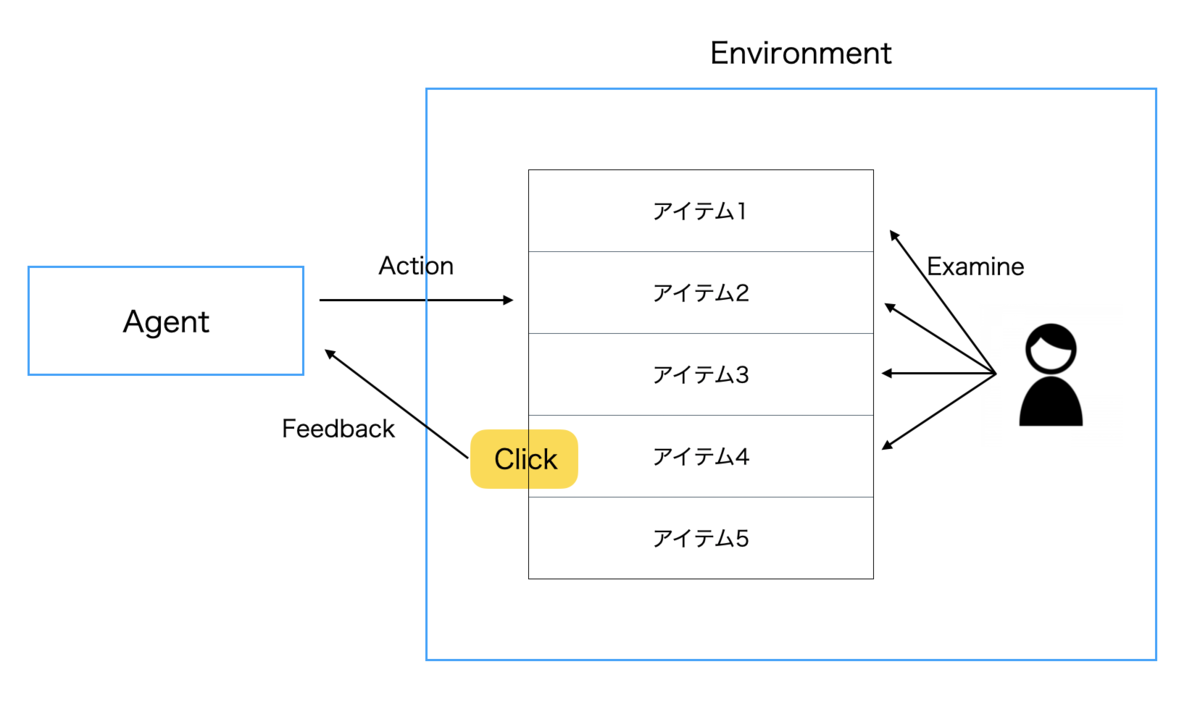
エージェントが全アイテムリストからユーザーに表出するアイテムを選びます。ユーザーからのクリックをフィードバックとして受け取り、次のリストを作成します。
Cascade Modelに最初に多腕バンディットを適用したKveton [3] らはCascadeUCB1とCascadeKL-UCBを提案しています。この2つの手法は主にupper confidence bound(UCB)の計算方法のみが異なります。
2つの提案手法は多腕バンディット問題でよく利用されるUCBがベースになっています。
今回は実装が簡単なCascadeUCB1の例を見ていきます。
ステップでユーザーに
個のアイテム群
を表示することを考えます。何番目のアイテムがクリックされたかを
としてステップtでユーザーが走査したアイテムの観測された
がわかります。
ユーザーに表出するアイテムは下記の目的関数を最大化する形で決定することになります。これがCascade Model上にバンディットアルゴリズムを適用する際のポイントです。目的関数はCascade Modelでも解説したように、少なくとも1つのアイテムがクリックされる確率となっています。
CascadeUCB1において、オンラインで返すリストは探索のためにUCBの値であるで決定します。
ここで はアイテム
の観測された
個の重みの平均であり、
はアイテム
がステップ
までに観測された回数です。
は
ステップ時の
周りの信頼区間です。
最終的にフィードバックで更新したからユーザーへの推薦リストを決定します。
結果的にが高いものから順に推薦リストに加えていけば良いことになります。
ここまでの擬似コードを下記に引用します。

疑似コードでは平均の更新を直接行っていることに注意してください。
PythonによるCascadeUCB1の実装
今回の実装ではPython3.9を利用します。モジュールは下記を利用します。
import math import random from abc import ABC, abstractmethod import pandas as pd import numpy as np from matplotlib import pyplot as plt from scipy.stats import bernoulli from tqdm import tqdm
後ほど別のアルゴリズムとも比較するので、実装しやすいように抽象クラスを定義しておきます。
class Agent(ABC): @abstractmethod def get_list(self, k: int) -> list[int]: pass @abstractmethod def observe(self, a: list[int], click : int) -> None: pass class Env(ABC): @abstractmethod def click(self, A: list[int]) -> int: pass @abstractmethod def weights(self, A: list[int]) -> list[float]: pass @abstractmethod def optimal_weights(self, k: int) -> list[float]: pass
Agentクラスの解説をします。get_listメソッドはAgentがユーザーに見せるリストを生成します。observeはユーザーからのフィードバックからパラメータを更新します。
Envクラスではclickメソッドがを返します。もし何もクリックしなかった場合は
-1を返すようにします。weightsメソッドは、渡されたリストの重みを返し。optimal_weightsは理想リストの重みを返します。これら2つのメソッドはリグレットを計算するときに使います。後ほど詳しく説明しますが、リグレットはステップでの理想の方策との累積報酬の差です。
実際に今回シミュレートする環境を用意しましょう。Cascade ModelにならってCascadingModelEnvを実装します。
class CascadingModelEnv(Env): def __init__(self, E: list[float]): self.E = E def click(self, A: list[int]) -> int: for i, item in enumerate(A): if self.E[item] > np.random.random(): return i+1 return -1 def weights(self, A: list[int]) -> list[float]: return [self.E[i] for i in A] def optimal_weights(self, k: int) -> list[float]: return sorted(E, reverse=True)[:k]
CascadingModelEnvの初期化時に全てのアイテム集合のクリック確率を渡します。EのindexをそのアイテムのIDとして利用します。
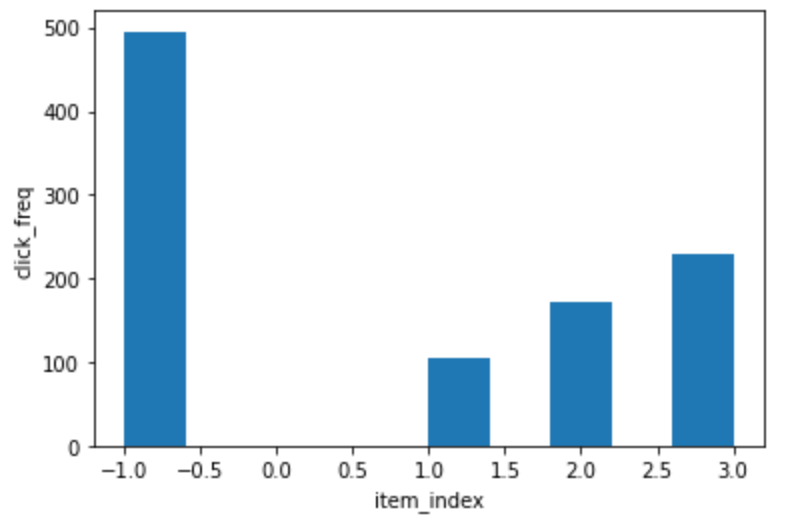
動作確認しておくと、狙ったようなヒストグラムになっていることがわかります。
## test E = [0, 0.1, 0.2, 0.3] env = CascadingModelEnv(E) results = [] for i in range(1000): results.append(env.click([1,2,3])) plt.xlabel("item_index") plt.ylabel("click_freq") plt.hist(results)
次にエージェントを作りましょう。上で紹介した疑似コードを淡々と実装します。UCB計算の部分はCascadeUCB1を使っていることに注意しましょう。
class CascadeUCB1Agent(Agent): def __init__(self, E: list[float], p: float): self.t = 1 self.counts = [1 for _ in range(len(E))] self.weights = [bernoulli.rvs(p=p) for _ in range(len(E))] def ucb(self, e: int): return self.weights[e] + math.sqrt(1.5*math.log(self.t - 1)/self.counts[e]) def get_list(self, k: int) -> list[int]: self.t += 1 ucbs = [self.ucb(e) for e in range(len(E))] return sorted(range(len(ucbs)), key=lambda i: ucbs[i], reverse=True)[:k] def is_click(self, click: int, k: int) -> int: return 1 if click == k else 0 def observe(self, a: list[int], click : int) -> None: if click == -1: click = len(a) for i in range(min(len(a), click)): e = a[i] before_count = self.counts[e] self.counts[e] += 1 self.weights[e] = ( (before_count * self.weights[e]) + self.is_click(click, i+1) ) / self.counts[e]
これでCascadeUCB1を実行する準備ができました。このエージェントのポリシーはリグレットの累積によって評価できます。リグレットは論文 3 と同じように
として計算します。ここでは理想リストであり、ユーザーに最もクリックされやすい
個のアイテムの集合です。今回実装したエージェントの評価のためにリグレットを計算する
regret関数を定義します。
def f(weights: list[float]) -> float: v = 1 for w in weights: v *= (1-w) return 1-v def regret(optimal_weights: list[float], weights: list[float]) -> float: return f(optimal_weights) - f(weights)
評価の準備ができたので、次に実際にシミュレーションする関数を用意します。
def simulate(agent: Agent, env: Env, k: int, steps: int) -> list[float]: optimal_weights = env.optimal_weights(k=k) cumulative_regret = 0 regret_cumulative_history = [] for i in tqdm(range(steps)): a = agent.get_list(k=k) click = env.click(a) agent.observe(a, click) setting_weights = env.weights(a) cumulative_regret += regret(optimal_weights, setting_weights) regret_cumulative_history.append(cumulative_regret) return regret_cumulative_history
最終的に累積リグレットを返すのは、後でグラフとして描写して、正しく動いていることを確認するためです。
早速今回のシミュレーション用の環境で動かしてみます。今回の設定では、
、
で行います。
E = [0.3, 0.2, 0.25, 0.1, 0.1, 0.24, 0.2, 0.1, 0.21, 0.1] env = CascadingModelEnv(E=E) agent = CascadeUCB1Agent(E=E, p=0.2) regret_cumulative_history = simulate(agent=agent, env=env, k=3, steps=100000) plt.xlabel("step t") plt.ylabel("Regret") plt.plot(regret_cumulative_history)
結果は下記になります。
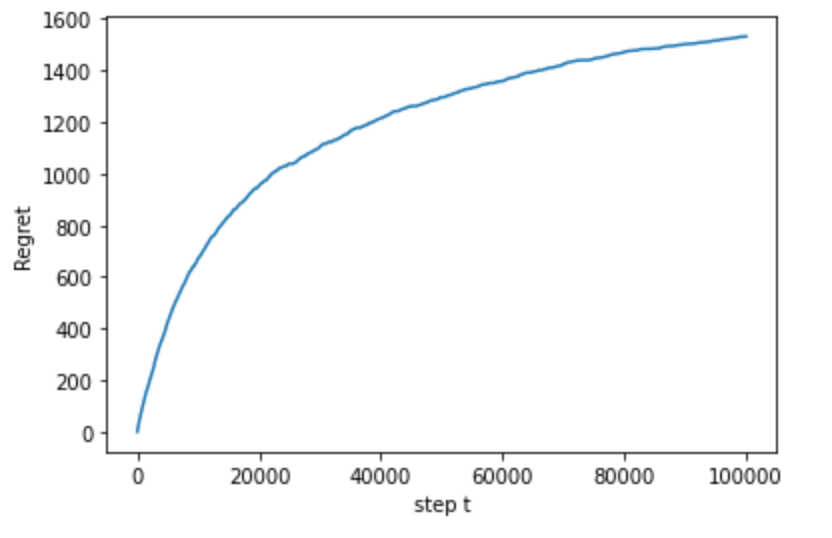
リグレットが収束しています。正しくクリック率の高いリストを生成してくれているようです。
Linear Cascading Bandits
探索対象のドキュメント数が大きい場合、ユーザーにデータセット内のすべてのアイテムを少なくとも1回は表示する必要があるため、日々たくさんのアイテムが現れるメディアサイトなどではCascadeUCB1は実用的ではありません。そこでZongら[4]はlinear cascading banditsというアプローチを提案しています。これはアイテムの引力確率がアイテムの特徴から線形関数で出力されると仮定する手法です。
Zongらの論文ではCascadeLinTSとCascadeLinUCBという手法を提案しています。今回は論文内で評価の高かったCascadeLinTSの例を追っていきます。
CascadeLinTSは Thompson Sampling(TS)[5]がベースになっており、LinTS[6]はTSの文脈バンディットへの拡張になっており、アイテムなどの素性を考慮できます。CascadeLinTSはLinTSをCascade Modelに適用した手法です。
アイテムごとの誘引確率の推定値はは下記のように定義します。
が大きいものを上から順にユーザーに表示するリストとして並てユーザーに表示します。
ここではアイテム
の
次元の特徴ベクトル
であり、
は
次元のパラメータベクトル
です。
は全てのアイテムについて共通に利用されます。
CascadeLinTSは、多次元正規分布からパラメーターベクトルをサンプリングします。
および、ベクトル
は多次元正規分布の事後分布のパラメータを求める際に出現するいつもの形です。詳しい導出は長くなるので他の文献を参照してください。僕のおすすめはオライリーの「ウェブ最適化ではじめる機械学習」の文脈付きバンディットの章です。この章では文脈付きバンディットの導出の流れで、多次元正規分布の紹介、事後分布のパラメータの導出、更新式の導出を行っています。
補足しておくと、行列は行をステップ
で観測されたすべてのアイテムの特徴ベクトルとし、
をステップ
で観測されたすべての引力確率の列ベクトルとします。
は
単位行列であり、
は学習率を制御するパラメータで、理想的には観測ノイズの分散であることが望ましいと論文で説明されています。
ここまでで、と
がわかれば、
をサンプリングできることがわかりました。あとは、ステップごとに
と
を更新していく必要があります。
と
は下記のように更新します。
擬似コードは下記になります。CascadeLinTSの全体像がAlgorithm1になり、事後分布のパラメータ更新部分がAlgorithm3です。


実装の観点では逆行列の計算が重そうです。そこで実戦では下記の更新式でを直接更新します。
こちらはウッドベリーの公式から導けます。Pythonによる実装のフェーズではこちらの更新式を使います。
CascadeLinTSのPython実装
今回の実装では、アイテムの特徴ベクトルを表現するために、技術ブログサイトの記事を推薦する施策を仮定します。それぞれの記事にはタグが1~3個付与され、タグによってクリックされる確率が変わります。今回はタグを特徴量としてCascadeLinTSを動かします。
まずは今回のシュミレーション用の記事を生成します。タグそれぞれのクリック率の線形結合で実際のクリック率を設定します。それぞれのタグのクリック率は正規分布からサンプリングします。
def gen_items(tags: dict[str, float], L: int, sigma=0.01)-> pd.DataFrame: tag_ids = list(tags.keys()) weights = [] features = [] for i in range(L): n = random.randint(1, 3) tag_samples = random.sample(tag_ids, n) w = 0 one_hot = [] for t in tag_ids: if t in tag_samples: w += random.gauss(tags[t], sigma) one_hot.append(1) else: one_hot.append(0) vec = np.array(one_hot) features.append(vec.reshape(len(vec),1)) weights.append(w) df = pd.DataFrame({'id': list(range(len(weights))), 'weight' : weights, 'feature' : features}) return df
実際にgen_itemsを動かしてみます。
tags_with_weight = {
'AWS': 0.03,
'Docker': 0.2,
'Elasticsearch': 0.15,
'GCP': 0.08,
'Git': 0.05,
'NLP': 0.19,
'Rust': 0.23,
'Scala': 0.14,
'機械学習': 0.15,
'強化学習': 0.20
}
df = gen_items(tags=tags_with_weight, L=10)
df.head(5)
結果、下記のようなアイテムID、クリック率、特徴量ベクトルが出来ます。タグはmulti-hot encodingしています。特徴量は論文に合わせての形で持っています。

環境の実装はCascadingModelEnvと同じなのでそのまま利用します。続いてCascadeLinTSAgentを実装します。疑似コードを参考に実装していきます。
class CascadeLinTSAgent(Agent): def __init__(self, d: int, sigma: float, features: pd.DataFrame): self.sigma = sigma self.features = features self.InvM = np.eye(d) self.B = np.zeros(d).reshape(d, 1) def get_list(self, k: int) -> list[int]: before_theta = (self.sigma**-2) * self.InvM.dot(self.B) theta = np.random.multivariate_normal(mean=before_theta.ravel(), cov=self.InvM) weights = self.features['feature'].apply(lambda x: x.T.dot(theta)).to_list() return sorted(range(len(weights)), key=lambda i: weights[i], reverse=True)[:k] def is_click(self, click: int, k: int) -> int: return 1 if click == k else 0 def observe(self, a: list[int], click : int) -> None: if click == -1: click = len(a) for i in range(min(len(a), click)): e = a[i] x = self.features[self.features['id']==e]['feature'].to_list()[0] self.InvM = self.InvM - ( self.InvM.dot(x).dot(x.T).dot(self.InvM) )/( x.T.dot(self.InvM).dot(x) + self.sigma**2 ) if self.is_click(click, i+1): self.B = self.B + x
この実装ではを直接更新していることに注意してください。
ではCascadeLinTSAgentを動かしてみます。論文の実験に合わせて、推薦するアイテム数
、特徴量の次元
で実験します。全アイテム数
は
で実験します。今回の実験では先ほど実装したCascadeUCB1と比較していきます。
k=4 L=[16, 256, 3000] steps=10000
早速実行してみます。
tags_with_weight = {
'AWS': 0.1,
'Docker': 0.2,
'Elasticsearch': 0.15,
'GCP': 0.08,
'Git': 0.05,
'NLP': 0.23,
'Rust': 0.3,
'Scala': 0.18,
'機械学習': 0.25,
'強化学習': 0.2,
}
fig = plt.figure(figsize=(13,4))
fig.suptitle('The n-steps regret of CascadeUCB1, CascadeLinTS')
for i, l in enumerate(L):
df = gen_items(tags=tags_with_weight, L=l)
E = df['weight'].to_list()
env = CascadingModelEnv(E=E)
cascadelints_agent = CascadeLinTSAgent(d=len(tags_with_weight), sigma=1, features=df.drop('weight', axis=1))
cascadeucb_agent = CascadeUCB1Agent(E=E, p=0.2)
cascadeucb1_regret_cumulative_history = simulate(agent=cascadeucb_agent, env=env, k=k, steps=steps)
cascadelints_regret_cumulative_history = simulate(agent=cascadelints_agent, env=env, k=k, steps=steps)
ax = fig.add_subplot(1,3, i+1)
ax.set_title(f'L={l}, k=4')
ax.plot(cascadeucb1_regret_cumulative_history, label='CascadeUCB1')
ax.plot(cascadelints_regret_cumulative_history, label='CascadeLinTS')
fig.legend(['CascadeUCB1', 'CascadeLinTS'], loc='upper center', borderaxespad=0.1, title="Algorithm", bbox_to_anchor=(0.5, -0.02), ncol=2)
fig.tight_layout()
plt.show()
結果は次のようになりました。
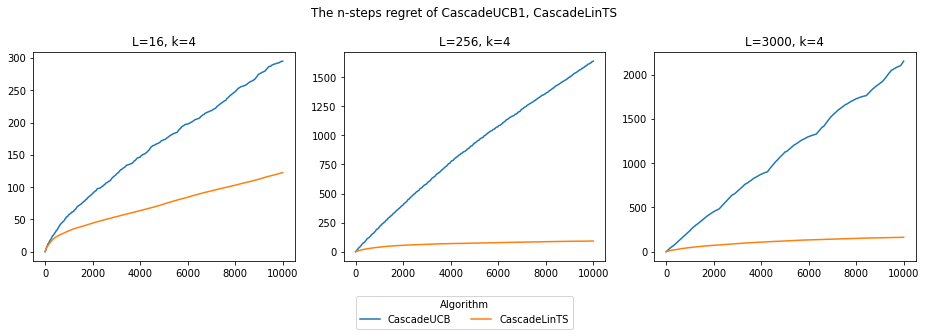
アイテムの特徴量を取り入れたCascadeLinTSの方がリグレットが少ないことがわかります。特にLが大きいほどCascadeUCB1のリグレットが大きく、収束しない結果を確認できます。
ちなみに10000stepの速度は下記のようになりました。
| CascadeUCB1 | CascadeLinTS | |
|---|---|---|
| |
0.00002秒 | 15秒 |
| |
3秒 | 24秒 |
| |
28秒 | 4分46秒 |
実装の下手さもあるかもですが、さすがにCascadeLinTSの方が遅いです。私の方で調査したところ、CascadeLinTSのget_listで100msオーダーの時間がかかっていました。
ただ、CascadeLinTSが相対的に遅いといってもで1回のstepが大体28msくらいなので、充分オンラインで動作するスピードです。
まとめ
今回はCascade Modelに多腕バンディットを適用するアルゴリズムであるCascadeUCB1とCascadeLinTSを紹介しました。
ここから更にユーザーの特徴量を考慮したパーソナライズをCascade Model上で行うアルゴリズムもあるので、もし余裕があれば次回以降のブログで実装とともに紹介します。
We're hiring !!!
エムスリーでは検索&推薦基盤の開発&改善を通して医療を前進させるエンジニアを募集しています!社内では日々検索や推薦についての議論が活発に行われています。各週で情報/推薦論文読み会も開催されています。
「ちょっと話を聞いてみたいかも」という人はこちらから! jobs.m3.com
Reference
-
Dorota Glowacka. 2017. Bandit Algorithms in Interactive Information Retrieval. In Proceedings of the ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR 2017, Amsterdam, The Netherlands, October 1-4, 2017, Jaap Kamps, Evangelos Kanoulas, Maarten de Rijke, Hui Fang, and Emine Yilmaz (Eds.). ACM, 327–328.↩
-
Craswell, N., O. Zoeter, M. Taylor, and B. Ramsey. 2008. “An experimental comparison of click position-bias models”. In: Proceedings of the 2008 international conference on web search and data mining. ACM. 87–94.↩
-
Kveton, B., C. Szepesvari, Z. Wen, and A. Ashkan. 2015a. “Cascading Bandits: Learning to Rank in the Cascade Model”. In: Proceedings of the 32nd International Conference on Machine Learning (ICML-15). 767–776↩
-
Zong, S., H. Ni, K. Sung, N. R. Ke, Z. Wen, and B. Kveton. 2016. “Cascading Bandits for Large-Scale Recommendation Problems”. arXiv preprint arXiv:1603.05359 - Proc. UAI.↩
-
Thompson, W. R. 1933. “On the likelihood that one unknown probability exceeds another in view of the evidence of two samples”. Biometrika. 25(¾): 285–294.↩
-
Shipra Agrawal and Navin Goyal. Thompson sampling for contextual bandits with linear payoffs. In International Conference on Machine Learning, pages 127–135, 2013.↩