先日、社内有志で開催していたDB自作本 Database Design and Implementation の輪読会ならぬ輪実装会がついに完結を迎えました。
RDBMSをゼロから、毎週一人ずつ、1章分を実装してPullRequestを出しつつ資料も準備して発表をこなすという一見ハードな勉強会で、完走できるか不安もありつつスタートしましたが、やってみるとめちゃくちゃ楽しく最後まで完走できました。
本記事ではみなさんに「うちでもやってみたい」と思ってもらえることを願って、読んだ本の推しポイントや、どのように勉強会を進めたかを紹介したいと思います。

Part1: おすすめポイント
本が良い
Edward Sciore『Database Design and Implementation』 が本当に良い本でした。
界隈では有名な本で、この本を参考にした「実装してみた」記事も既に多くあります。
ゼロから標準ライブラリのみを使ってシンプルなRDBMSを作っていく内容で、シンプルといいつつトランザクションやSQLの構文解析、インデックスや実行計画の最適化などまでしっかりカバーされています。
またJavaで実装したコードがセットで公開されており、正解コードを参考にしながら再実装できます(私たちはGoで実装しました)。
データベースの下位のレイヤから、章ごとに段階的にコンポーネントを組み上げていく構成で、特に、手前の章のコードにほぼ変更を加えずに進んでいく点が素晴らしかったです。
このおかげで章ごとに担当を分け実装するのが上手くハマり、輪実装会と非常に相性が良かったと感じています。
みんなでワイワイやるのが良い
上記のとおり素晴らしい本ですが、知る限り翻訳版は存在しておらず、洋書に挑むことになります。内容的にもかなり高カロリーなので、一人で読み切るのはかなり大変だったと思います。
その点、輪実装会という形のおかげで負荷が分散し、不明点は発表中の議論で解消しながら進めることが出来ました。
また普段あまりレビューしない他チームのメンバーとPullRequestのレビューをし合えるのも新鮮でした。
なにより、一人で読むより楽しいに尽きます。
3ヶ月で完走できるのがいい
週に一度開催のペースで、おおむね1回1章ずつ全14回を3ヶ月で完走することが出来ました。
正直、もっと時間がかかって中だるみしてしまうのでは、最悪途中で消滅するのではという心配もあったのですが、まったくの杞憂でした。
スピーディに進められたおかげで最初の方の低レイヤー部分の記憶が蒸発しないうちに後半を読むことが出来ましたし、準備期間を長く取るために隔週、よりも週一開催でちょうどよかったのかなと感じます。
完走後のモチベーションアップが良い
読破したことで、これまでブラックボックス的な理解だったデータベースについての解像度がかなり高まりました。
一方で、実装したものは基礎をおさえつつも「SimpleなDB」になっており、普段扱っている本物のDBとのギャップが気になってきます。
また書籍では完成したDBについて実際に利用してみる要素は少ないので、作り上げたものを実際にもっと使い倒してみたい気持ちが高まります。
- 本物のOSSのソースコードも読んで比較したい
- 作ったDBを使ってサンプルアプリケーションを作ってみたい
- パフォーマンスのベンチマークをとってみたい
- 章末課題にある機能拡張を実装したい
- 本番環境に投入したい
- とにかくまずは打ち上げがしたい
などなど、今この瞬間の私達のモチベーションはとどまるところを知りません。
Part2: 輪実装会
いかがでしょうか。やってみたくなって頂けたでしょうか。
Part2では、私たちがどんな感じで輪実装会を行ったかを紹介します。これから輪読会を開催してみる方の参考になれば幸いです。
募集
Slackで参加者募集のジャブ投稿を打ちつつ、社内で開催されているテックトークの場で勉強会開催をアナウンスして参加者を募りました。
「輪”読”会」だけではなく「輪”実装”会」をやってみたいとはしつつ「聴くだけの参加もOK」「忙しかったら発表延期OK」として精一杯ハードルを下げます(でも結局ほぼ全員が発表しました)
参加者
チーム関係なく興味のある人が集まり、結果的に6チーム11人がメインメンバーでした。
「自作できちゃうんだ!」「DBを一から作るのはロマン」「ブラックボックスで仕組みを知らない」「エンジニアたるもの一度は自作しておかねば」といった人たちが集まりました。
また、ちょうど時期が重なったインターン生も飛び入り参加していってくれました*1。
進め方・実装
前述のとおり、章ごとに担当者を決め、発表日までに実装&資料準備しつつ、当日はZoomでリモート発表していきました。
言語はGoを採用し、GitHubにリポジトリを用意して*2、PullRequestを出していきました。
勉強会の発表ではプレゼンテーション資料と合わせてPullRequestの実装コードを解説します。
PRレビューは発表後に行いますが、同時に(マージを待たずに)次の人も準備を始めることになるのは本当にハードでした…。そのため全員のApprove必須などにはせず、レビュー出来た人のApproveだけでどんどんマージしていきました。
レビューとマージに1週間、次の準備にもう1週間としたい気持ちにもなりますが、乱暴めな短期レビューにしてでも1週間で進めた方がスピード感もって進められてよかったと思います。
期間
6月から開催し、先述のとおり、ほぼスキップすることなく3ヶ月で完走することが出来ました。
「すみません準備できてないのでスキップで」も全然アリで!としていましたが、結局ほぼスキップなく終わったのは全員の意欲と意地を感じました。
Part3: おれたちのDB実装戦記
最後に、実際にどのように実装がされていったのか、 各章ごとに担当者からの感想も交えて紹介します。
6/13 第1章〜第3章(担当:横本)
開幕の1章2章は「RDBMSとは」「JDBCとは」といった内容で、実装は3章から始まり、まずディスクアクセスする部分を作ります。
OS/ファイルシステムが提供してくれる「ファイル」より細かく制御を行うために自前のBlock、Pageを作るところから始まり「DBはじまったな」という気持ちでした。
6/20 第4章(担当:横本)
前章で作ったBlockをメモリ上にキャッシュしておくBufferPoolなどを作ります。
ここまではかなり「土台」という感じで、どう使われるのかはまだあまり見えてはきません。 しかし「如何にbufferpool等を駆使してBlockの読み書きを減らすか」は本書、そしてDBのキモになっていくことを強く予感出来てワクワクしました。
なお「言い出しっぺとしてスタートダッシュに最初2回くらい担当しておくか」と思って2枠担当しましたが激しく疲れました…。
6/27 第5章 前編(担当:北川)
5章はトランザクションを実装していく章でした。
ACID特性のこの部分はリカバリーでこの部分はトランザクションで担保するといった内容でした。まあまあの分量があったため、この章では2回に分割して行いました。
前編では障害発生時のリカバリーをどのように行うかという実装を行いました。
最近ではマネージドなRDBMSを使うことが多くなりあまり意識していませんでしたが、とても勉強になる章でした。
7/11 第5章 後編(担当:北川)
5章の後半はトランザクションを実装していく章でした。
トランザクションはDBの中でもかなり花形のイメージでした。そのため、この章を担当出来たのは個人的には楽しかったです。
後半ではSerializableなスケジュールは何かという定義の話から、どのように実装すればより堅牢なトランザクションを作ることが出来るのかという話から実装まで行いました。
このへんは授業や先人の技術ブログなどで分かったつもりになることが多い気がするのですが、改めて実装とセットで復習することによってより理解が深まった気がします。
7/18 第6章(担当:丸山)
6章は、これまでの章で作成した機能を使用してレコードやテーブルの概念を実装する章でした。
この章で初めて慣れ親しんだテーブルという概念が出てきたため、「これまでの実装がこうやってテーブルと繋がるのか!!!」と感動しました。
最初は聞く専で参加する予定でしたが、初回発表を聞いて「こんなに面白いなら発表しないと損」と思い発表することにしました。
本自体は全体を通して簡単な英語で書かれており、図による解説も多くあったため、当初の予想よりも読みやすかったです。その上で各章担当者が丁寧な解説をしてくださったので、データベースのお気持ちがちょっとわかるようになりました。

7/25 第7章(担当:松原)
7章は Metadata Manager というデータベース内部で使うメタデータを扱う章でした。
内部で扱うデータに対して、これまで作ってきたテーブルの実装をそのまま使っていくというドッグフーディング的なアツい章で、実際に他のデータベースでもそのような実装がされているという点が面白かったです。
担当した章以外は各担当者の発表がなければ理解できてなかったので、各担当で進められたのは本当に助かりました。参加した当初は本当に終わるのかと思っていましたが、なぜか毎回一章着実にパワープレイで進むので想像していた半分くらいの期間で終わったのが中弛みとかもなくとてもよかったです。
今までぼんやりとした理解だった部分も、本書でとっかかりを得ることができたので、よくあるシェルやオレオレ言語の再実装本としてもよかったなと思います。
8/1 第8章(担当:須藤)
8章はデータベース エンジンが SQL クエリを実行する方法、特に関係代数とその実装方法について解説している章でした。
Where句を使って条件に一致する行を取得したり、指定された列の値だけを取得する処理がデータベースエンジンの中でどのように実装されているのかについて理解を深めることができました。洋書かつ分量の多い本なのですべてを読むのは骨が折れますが、データベースの裏側を一通り理解できるとても良い本でした。
8/8 第9章(担当:永山)
9章はSQLの構文解析を題材とした章です。
再帰下降によるシンプルなパーサーを実装する一方、やはり他章との接続が少ないためか説明は最低限という印象でした。
この章に限らず、この本は各章で前章までのコードに変更を加える必要がほぼないように綿密に設計されて書かれている印象があり、輪読など多人数で順に実装していく今回のような進め方には非常に向いているなと感じました。
また、技術書にとってはお約束とも言える「実装は読者の宿題とします」な部分についても説明を省略せず、しっかり紙面が割かれている点で非常におすすめできるとても良い本でした。
8/15 第10章(担当:木田)
第10章はPlannerの実装がテーマでした。
DBMSが実行計画を作成する過程について理解が深まりました。この章の実装段階になると以前の章で作成されたコードを組み合わせることが中心で、I/Oに近いところの実装をしていた前半に比べて一気に抽象度が上がったなと感じました。
この章の実装を終えるとシンプルなSQLが実際に実行できるようになるのですがその時の感動はひとしおです。
本書においても現実のDBと同様実行コストの見積もり根拠として統計情報を参照しており、正確な統計情報が適切な実行計画を立てるのに重要であることがわかります。統計情報の更新はくれぐれも怠らないように。
8/22 第11章(担当:高島)
第11章は、これまで実装してきたデータベースを、JavaのJDBCインタフェースを通じて操作できるようにする章です。
今回はJavaではなくGoを採用したので、JDBCインタフェースの代わりにGoのdatabase/sqlインタフェースで操作できるようにしました。
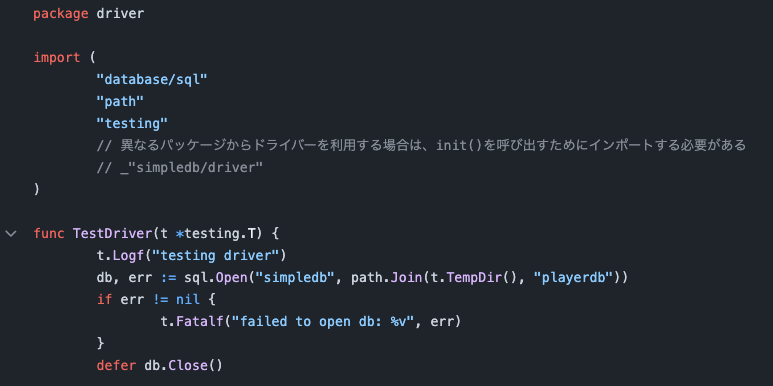
トランザクションやコネクションの扱いなど各々のインタフェースで扱いが異なる部分もあり、本書の意図を必ずしも十分に再現できていませんが、今回実装したデータベースを他の商用データベースと同じように操作できる喜びや、それを実現する仕組みを提供している言語処理系の凄さを味わうことができました。
8/29 第12章(担当:山本)
12章はIndexを実装する章です。まずはHashを使ったIndexについて紹介し、その後BTreeによるIndex実装を行いました。
計算量における効率面を主眼にするアルゴリズム系の本と異なり、DB実装本らしく実際にファイルシステムへのアクセス量も踏まえて比較していたのが印象的でした。また、よく考えると当然ではあるのですが、Indexで利用するメタデータ自体もDB内のテーブルのレコードと同様同じファイルシステムに書き込むという点が興味深かったです。というのも、インデックスの保存もレコードの保存も、前章で作成した同じファイルシステムのI/O機構を利用するというのは目から鱗でした。
9/5 第13章(担当:河井)
13章はSortをベースにGroupByやJoinを実装する章です。
私はこの勉強会に途中から参加したのですが、この章はこれまで実装した内容を活用する内容だったので、キャッチアップするのにも良かったです。これらのクエリの裏側が理解できただけでなく、クエリコストの見積もりも扱っていて、実際のデータベースの EXPLAIN の結果の解像度が高まったのも嬉しい点でした。
9/12 第14章(担当:横本)
この章では前章のロジックをBufferPoolを駆使してさらにディスクアクセスが少なくなるよう進化させます。ロジックが最適化され現実のDBに近づいている感覚も大きい章でした。
一方で、紹介されているロジックの3つのうち2つが練習問題枠としてソースコードが付属していないハードな章でもありました…。
9/19 第15章(担当:横本)
いよいよ最終章では、さらなる最適化として10章で作ったクエリプランナーを効率的な実行計画を作成できるように進化させます。
元のプランナーでは1000年かかっても終わらなかったJOIN(薄々感じていました…おバカ過ぎないかと…)が7秒で終わるようになります。理屈上では。なったはずです。実測せねば。
さらに、12章〜14章で作成した賢いロジック達もここで結合され、これまでに作ったすべてのテクニックが結集した私たちのデータベースがついに完成しました!!!


おわりに
一人だと心が折れるかもしれなくても、みんなで戦えば完走もできて、戦友も得られます。
輪"実装"会、おすすめです。
We are hiring !!
エムスリーではDB自作も辞さないギークな仲間たちで日々開発を行っています。 そんなチームの雰囲気に少しでも興味がある方は、ぜひ次のURLからカジュアル面談をご応募ください!
また新卒・中途それぞれの採用はもちろん、インターンも常時募集しています!
カジュアル面談お気軽にどうぞ
エンジニア採用ページはこちら
インターンも常時募集しています
*1:本ブログにプレッシャーを書けられる図 https://www.m3tech.blog/entry/2024/09/02/174905#f-0a7484bf
*2:メインリポジトリとは独立に、自前のリポジトリにすべて実装しながら並走する猛者もいました。すごすぎ