こんにちは!AI・機械学習チームの小栗です。普段は東京大学電子情報工学科で学生をしており、エムスリーには業務委託で参画しています。
今回はkannonというライブラリについて紹介します。kannonはgokartという機械学習向けパイプラインライブラリを分散並列化して実行できるようにするライブラリです。kannonは2023年3月に私が参加したAI・機械学習チームでのインターンで開発され、OSSとして現在も開発を続けています。
なお、本記事は「gokartで爆速開発!MLOps勉強会」の発表をもとに加筆したものになります。
発表資料も公開していますので、そちらも是非ご参照ください。
また、インターン参加報告として以前にもkannonについて解説しています。それに比べて本記事は、よりライブラリの仕組みやコンピュータサイエンスとしての面白さに重きを置いて解説しています。
以前の記事はインターンの流れや感想なども掲載しています。そちらにも興味のある方は是非ご覧ください!↓
kannonとは?
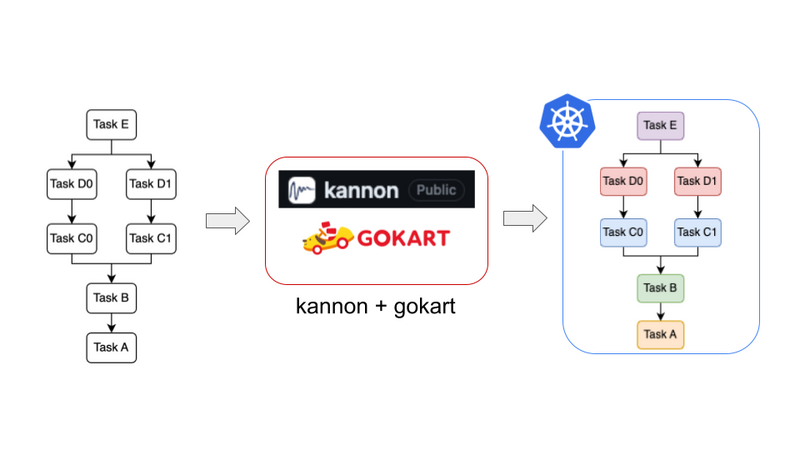
kannonはgokartという機械学習向けのデータパイプラインを構築できるライブラリのラッパです。gokartで定義されたTaskをKubernetes上で分散並列実行できるようにしてくれます。パイプラインは上図のように複数のTaskの依存関係を表したDAGとして表現されています。これをkannonが解析し、依存関係を保ちながらTaskをKubernetes環境下で分散並列実行します。
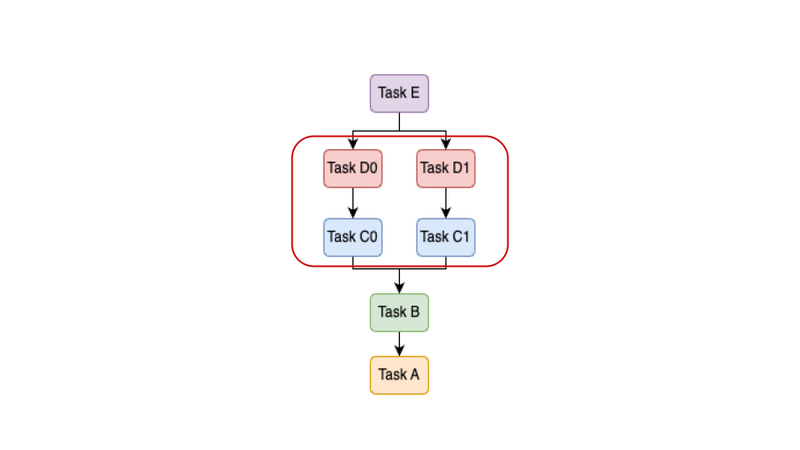
そもそもgokartを分散並列化するメリットは何でしょうか?それは機械学習パイプラインの特徴である「データ依存性の無い並列実行可能な箇所が多い」ことを最大限利用できることです。例えば上図では(C0, D0)と(C1, D1)との間にはデータ依存性がないため、それぞれのブランチをやろうと思えば並列に実行できます。機械学習の実運用では「N月分のデータのダウンロード・前処理」から「特徴量抽出」、「k-fold CV」などの並列化可能な処理が多く現れます。
実際、いくつかの社内のgokartを用いているプロジェクトでは一回のイテレーションにかかる時間が大きいことが問題になっており、上記のような並列化可能な部分を並列化して高速化を狙いたいという思いがありました。しかしながら、すでにgokartで実装されているものを並列化するにはいくつかの課題がありました。
その課題とは、gokartがシングルスレッド実行であることです。gokartはgokart.build()という1つの関数の中でTaskの依存関係を解決しながら、そして結果をキャッシュしながら逐次的にTaskを実行していきます。これに並列化を加えるとすると、Taskの依存関係を解決した上で、並列化するべきTaskを識別し、それを何らかの方法で並列実行する必要があります。この方法は自明ではありません。また、エムスリーではこのようなパイプラインをGKE上で運用しているため、Kubernetesフレンドリな分散並列化のアプローチを考える必要がありました。
そこで、kannonでは、並列化するべきTaskを複数のKubernetesのJob (以下k8s job)で分散並列実行するというアイデアを採用しました。gokartにはキャッシュやAWS, GCPなどのクラウドストレージとの連携など、多くの便利な機能が実装されています。これらを引き継ぎつつ、gokartをラップする形で分散並列化の機能を実装しています。
kannonのアーキテクチャ
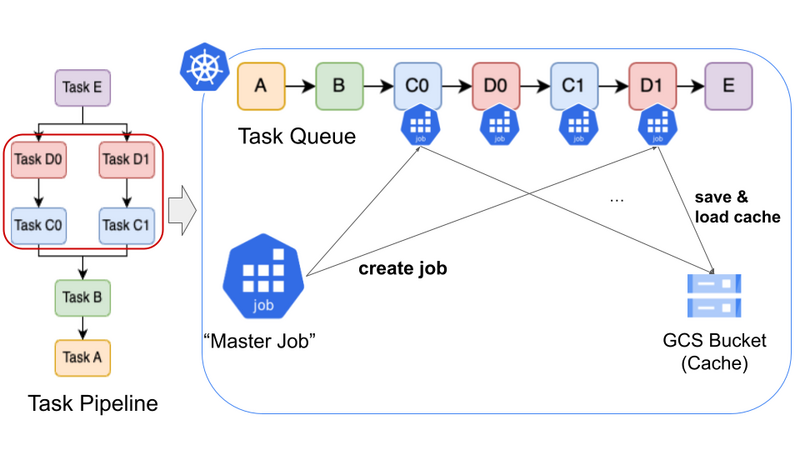
上図はkannonのアーキテクチャを示しています。赤枠で囲われているTaskC0, C1, D0, D1を複数のk8s jobに分散し並列に実行している様子を表しています。
まずkannonはMaster Jobという中央管理を担うk8s jobで動きます。Master JobはTaskパイプラインのDAGの依存関係を解析し、Task Queueを構築します。依存関係の解析はトポロジカルソートを用いています。基本はこのQueueを前から処理していくことになります。分散しないTask(例えばA, Bなど)は普通のgokartと同じように実行していきますが、分散するTask(C, D)に対しては、Master Jobが新たにChild Jobを生成しTaskを割り当てます。詳しいフローは後ほど説明します。
ここで重要になるのがキャッシュです。gokartは機械学習で重要となる再現性の担保や効率性のために、同じTaskとパラメータの組み合わせで実行した結果に対してキャッシュが使われます。この機能をkannonでも引き継ぐために、全てのJobから読み込み・書き込みが可能な共有ストレージをキャッシュとして用いる方針を採用しています。社内では上図に示されているようにGCS Bucketを用いています。これはAWSのS3など何らかのアクセス可能なストレージであればよいです。各Jobは実行に必要な依存先のTaskの結果をキャッシュから読み、自身の実行結果をキャッシュに書き込みます。これによりkannonでもgokartと全く同じキャッシュの運用ができるようになっています。
一方、複数のNodeが非同期に同じストレージにファイルを読み書きすることから、この状況は競合が起こりうるものであるといえます。そこでgokartではRedis Lockを用いる方法によりこの競合の問題を解決しています。これに関しては今回の勉強会でも当社の池嶋が紹介しています。そちらの記事も是非ご覧ください!
Task Queueの処理方法
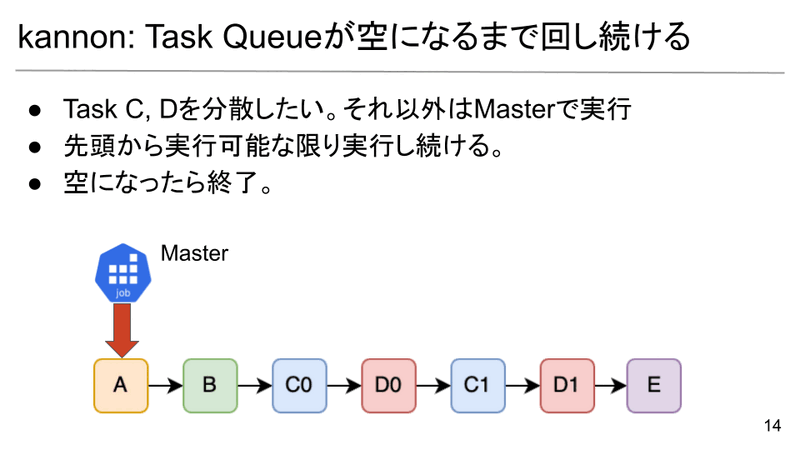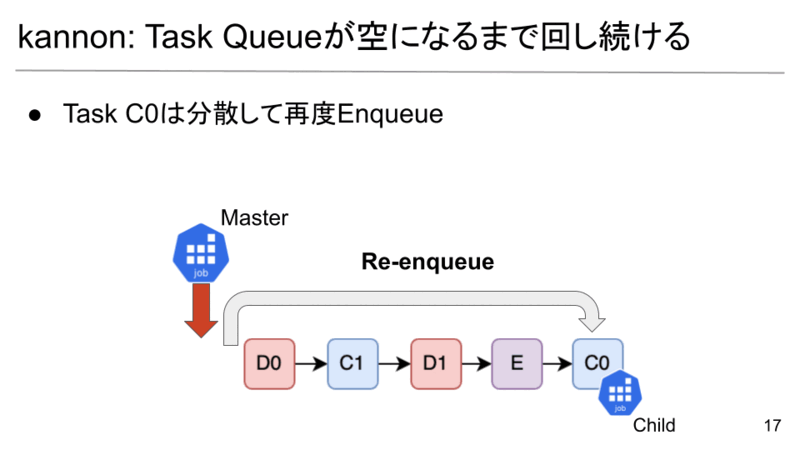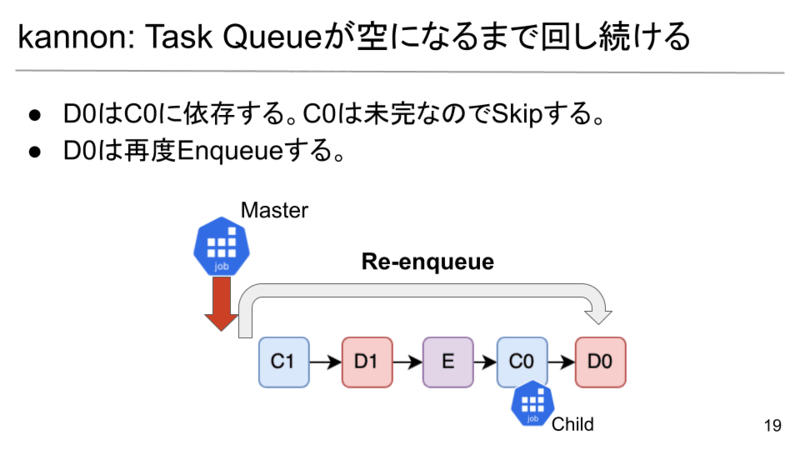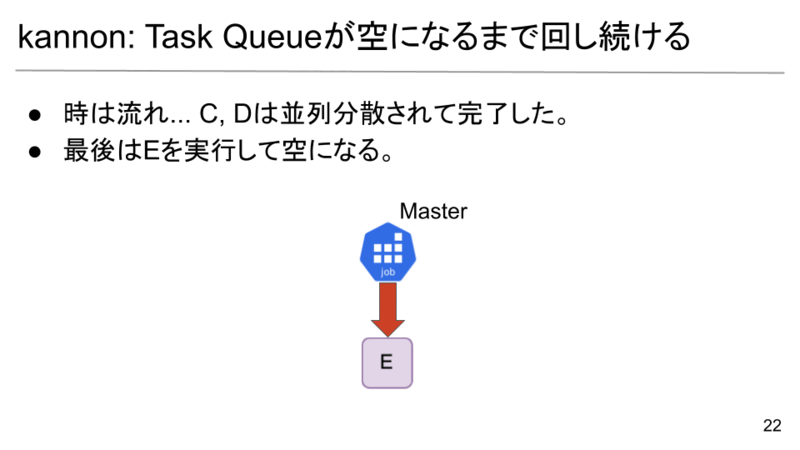
続いて、kannonの肝であるTask Queueの処理方法を解説します。基本的なポリシーは「Queueが空になるまで回し続ける」です。上のアニメーションに示されているように、Master JobがQueueを先頭から捌いていきます。途中で分散するべきTask(C0, C1, D0, D1)に出会ったら、それを新たなChild Jobに割り当てて分散させます。これを繰り返すだけでなぜうまくいくのかを詳しく説明していきます。 この動作を最後まで確かめると、OSのスケジューリングに似ていることがわかると思います!
1. 先頭から処理する
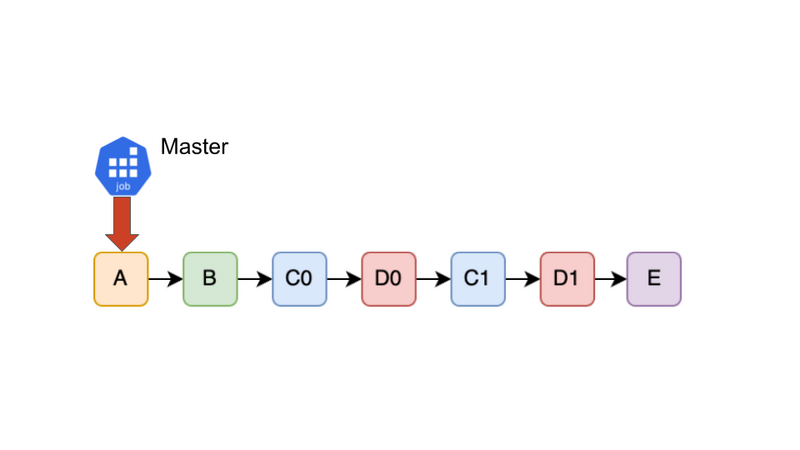
Master JobはQueueを先頭から処理していきます。A, Bは分散しない通常のTaskであるためMaster Jobが逐次的に実行します。実行が終わったらQueueからDequeueします。
2. 分散するべきTask(C0)に出会った
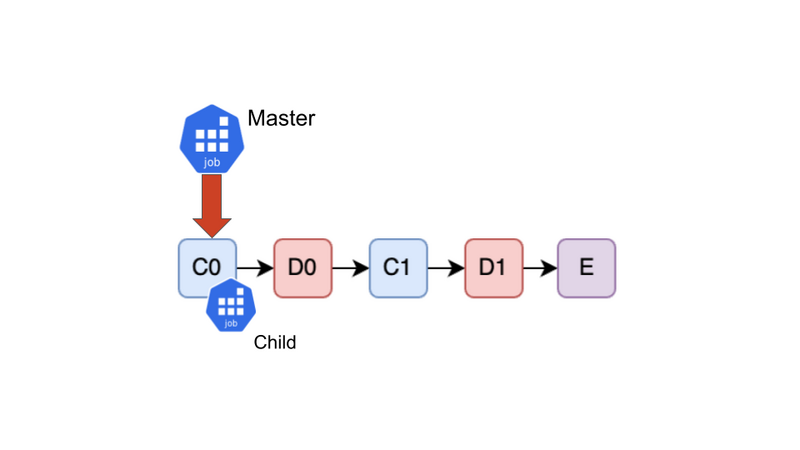
A, Bの処理が終わり、C0がやってきました。C0は分散するべきTaskのため、Master JobがChild Jobを新たに作成し、C0を割り当てます。C0は裏で実行が開始されます。ここで、C0はBの結果に依存していますが、Bはすでに実行が終わりキャッシュに結果が保存されているため、問題ありません。
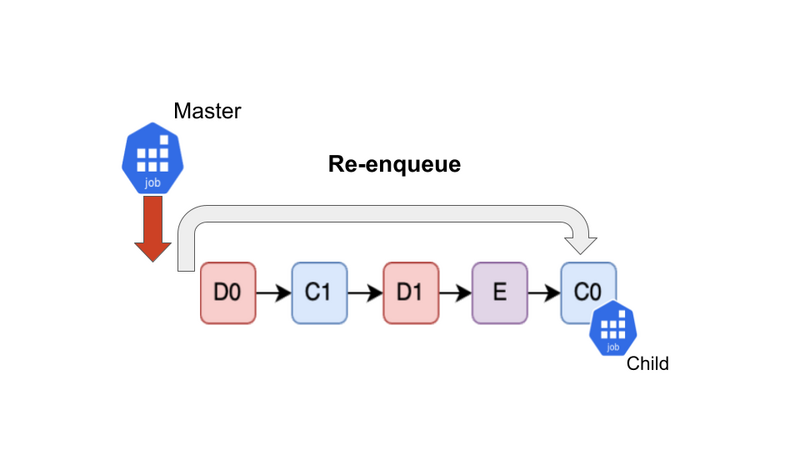
C0は今後終了を待つために、再度末尾にEnqueueします。
3. Childで実行中のTask(C0)に依存するTask(D0)に出会った
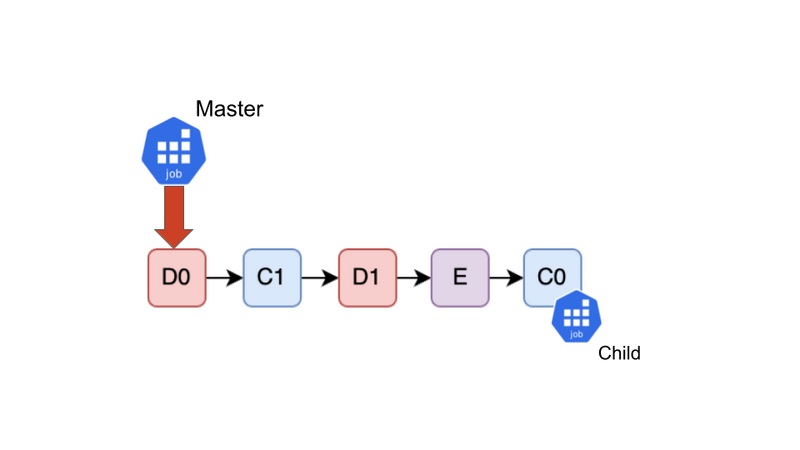
D0がやってきました。D0はC0に依存していますが、C0はChild Jobでまだ実行中です。それを検知し、D0の実行をSkipします。
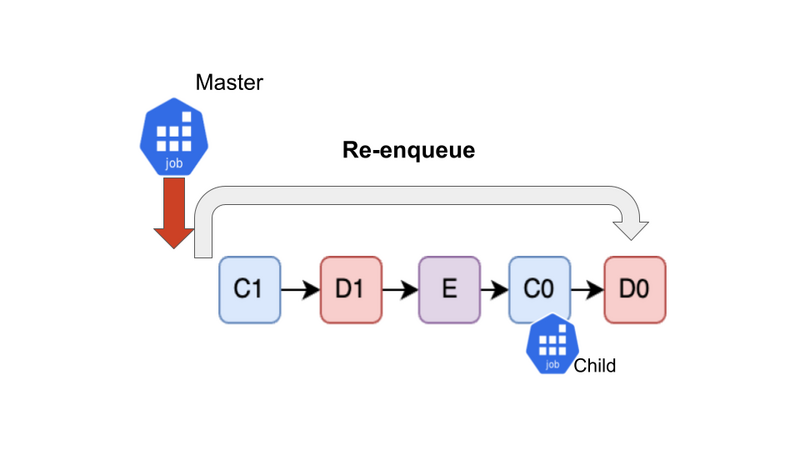
D0はあとで処理する必要があるので末尾にEnqueueします。
4. 分散するべきTask(C1)に出会った
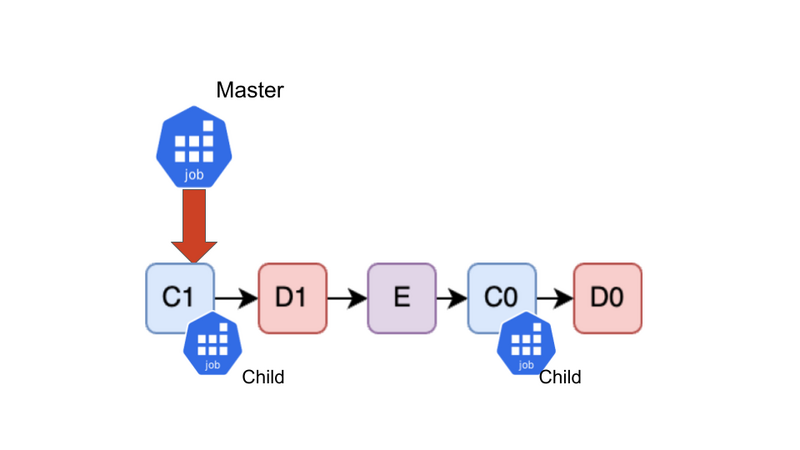
C1がやってきました。C1は分散するべきTaskです。依存先のBは完了しているので、新たにChild Jobを作成してC1を割り当てます。 この時点で、C0, C1が別々のJobで同時に実行されていることが確認できます。すなわち、C0とC1が分散並列実行されています!
5. Childで実行中のTask(C0)に出会った
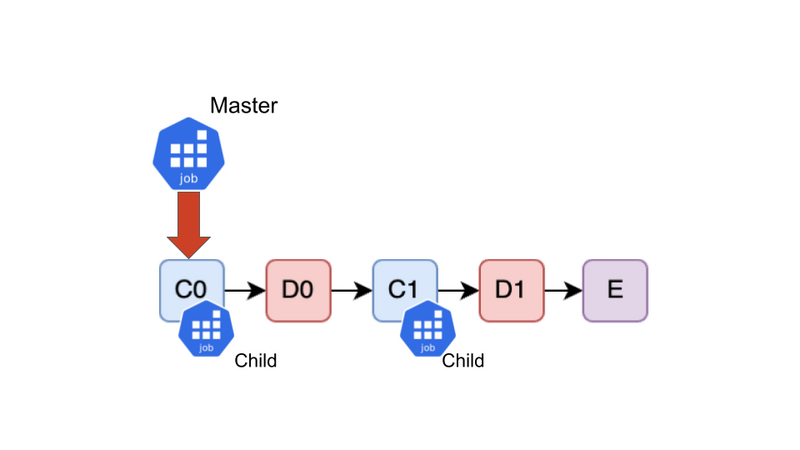
再びC0がやってきました。C0はChild Job上で実行されているため、そのStatusを確認しにいきます。 まだC0が実行中であれば、再び末尾にEnqueueします。逆にC0が完了していれば、C0をDequeueします。 こうして完了したTaskがQueueからDequeueされていき、やがて数が減っていきます。
6. 時間が経過し、Queueが空になった
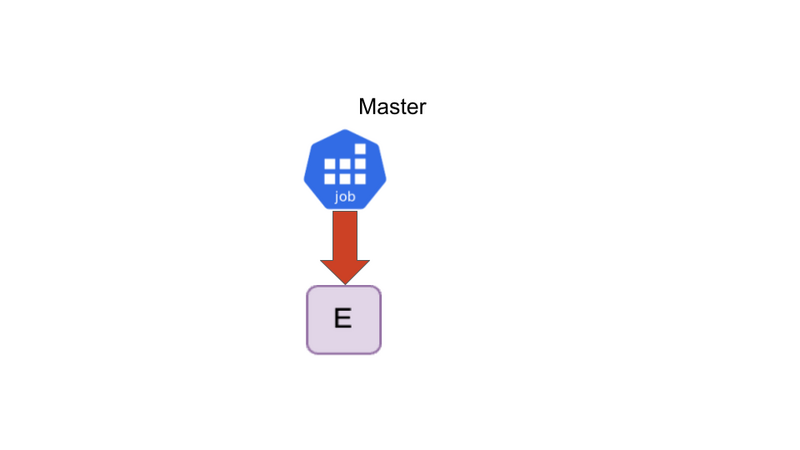
時は流れて、C0, C1, D0, D1は分散並列実行されてQueueからDequeueされました。 最後はEを実行してQueueが空になります。空になったら全ての処理が終了します。
Child Jobの作成方法
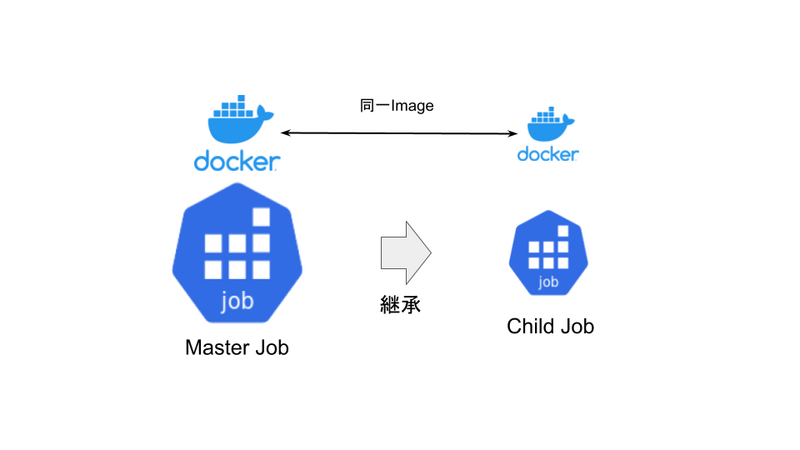
次に、Child Jobをどのように作成するのかについて説明します。 Master JobとChild Jobは同一のDocker Image上で動くようになっています。Master JobがChild Jobを作成する際に、動作に必要な環境変数をChild Jobに引き継ぎます。ここで引き継ぐべき環境変数はgokartのキャッシュの保存先など色々ありますが、全ての環境変数を引き継げばよいというものではありません。闇雲にMasterのシステム環境変数まで引き継ぐのはよろしくないため、ユーザ側がどの環境変数を引き継ぐべきかを指定するようになっています。 この継承の操作はおおまかに親プロセスが子プロセスを生成するようなイメージに近い操作です。スケジューリングや子プロセスなど、コンピュータの動作原理に非常に近い抽象化をしていることがわかると思います。
kannonの使い方

kannonを利用するには、gokartで定義されたTaskに対して上図ような変更を加えます。分散したいTaskが継承するクラスを gokart.TaskOnKartからkannon.TaskOnBulletに変更するだけです!

タスクの実行側は上図のように、いくつかのKubernetes関連、環境変数関連の引数を与えたのちに、gokart.build()と同様にKannon(**).build()を実行します。このスクリプトはMaster Jobとしてデプロイされている想定です。このようにすることで、これまで説明してきたようなQueueの構築・処理が走り、分散並列実行しながらタスクパイプラインを捌いていきます。
まとめ
kannonはgokartをより効率的に利用するためのライブラリで、分散並列といった難しい概念を簡潔なインタフェースの裏に押し込めて抽象化しています。その裏には今回説明したような仕組みが隠されています。Queueなどのデータ構造による制御や、子プロセスの作成に似た操作、スケジューリングに似た操作、分散キャッシュ、ファイル競合など、CSの原理的な話も多く登場します。gokartを日頃から使っている方はもちろんのこと、gokartをまだ使ったことがない方でも、純粋にトピックとしてお楽しみいただけたのではないかと思います。
kannonは現在もOSSとして開発が続けられています。手軽にkannonの効力を実感できるTutorialを作成しているので、是非お試しください!Issue, PRでのフィードバック、Starもお待ちしております!
また、併せてgokartをまだ使ったことがないという方も、是非この機会に入門してみてください!
We're hiring!
AI・機械学習チームでは、gokartを用いてMLプロダクトを開発しつつも、kannonのような新たなライブラリを生み出し、OSSとして開発するという活動も行っています。私自身、学部3年生のときにインターンに参加しkannonをゼロから開発するという経験をしましたが、非常に勉強になり、やりがいのあるものでした。新卒・中途の方はもちろんですが、ML・MLOpsやOSS開発に興味のある学生の方も是非インターンに応募してみてください!お待ちしております!