こんにちは、基盤チームでエンジニアをやっている桑原です。
エムスリー Advent Calendar 2022 の22日目の記事です。
今日はモニタリング環境を整えた結果エラー解決できたケースをご紹介します。
概要
とあるプロジェクトにて、リクエストが増えるタイミングで不定期にDBコネクションエラーが発生しました。
アプリログからだけだと原因究明が全く進まなかった状況で、モニタリング環境を整備していくことで解決の糸口を見つけることができました。
どのような調査を進めて解決の糸口を見つけることができたかをご紹介したいと思います。
前提環境
歴史的経緯から1つのデータベースに複数のサービス用テーブルがありました。データベースの共有はよくないので個別のサービス用のデータベースへ分離するプロジェクトを進めています。
データベースの分離プロジェクト
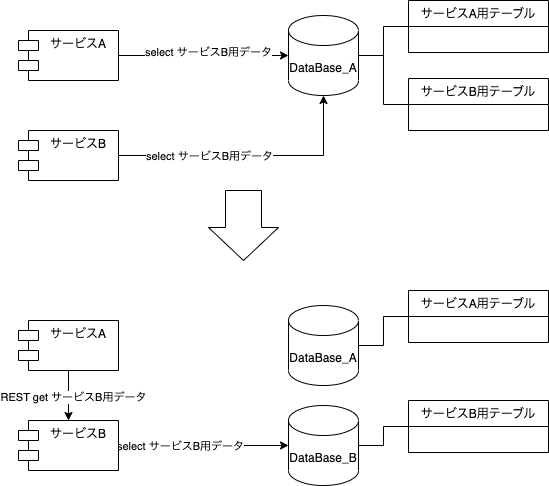
サービスAはサービスB用データを必要としているため、データベースを直接参照せず、サービスBからREST APIで取得するようにしました。
サービスのモニタリング環境
着手当初のサービスBのモニタリングは以下の状況でした。
- nインスタンスあるサービスを合計したDBへの全体のコネクション数のモニタリングが存在
- 各インスタンスごとのアクティブコネクション数やアイドル状態コネクション数はモニタリングなし
問題発生
上述のデータベース分離プロジェクトを本番環境へデプロイしたところ、不定期にエラーが多発することがありました。 アプリログ、前述のモニタリングから以下のことはわかりました。
- サービスBにてDBコネクション取得失敗が多発
- アクセス数が増える時間帯に発生。ただし毎日ではなく不定期に発生
- DBの負荷は多少上がっているがDB側にアラート出ていない
厄介なことに、アクセス数が増えたからといって必ずエラーが発生するわけではないため再現性がない上に、ログからはDBコネクション取得の失敗程度の情報しか取れなかったため原因の根本がつかめずにいました。
まず、DBコネクション取得失敗というところから、APIリクエスト数が増えすぎて「 DBコネクションのプールを使い切ってしまった 」ことを疑い、優先的に調査しました。
DBコネクションとAPIリクエスト数の調査
前述の通りDBへの全体のコネクション数のモニタリングが存在していたため確認したところ、以下の状況でした。

アラート数として設定している900に対して使用数は500程度と、余裕はまだまだありそうです。
ここから読み取れる情報としては、APIリクエスト数が多すぎてDBコネクションを使い切ってしまったことは考えにくいです。
特定のインスタンスの調査
- 全体のDBコネクションが使い切られているわけではなさそう
- LBによる振り分け先の偏りがあるわでけもなさそう
といった事実から、特定のインスタンスのみで問題が発生していることを疑いました。
その観点でログを横断検索したところ、
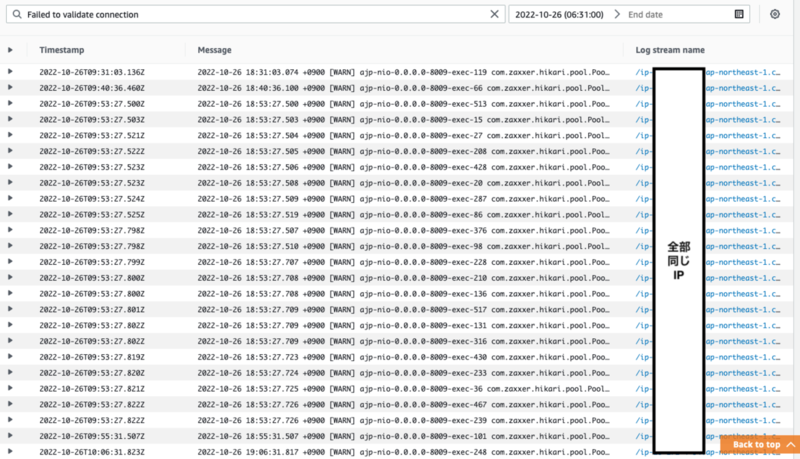
どうやら、特定のインスタンスでコネクションが取得できなかったためエラーが多発していたことがわかりました。
しかし、
- なぜこれが発生したのか
- なぜ特定のインスタンスだけ発生したのか
- エラーが発生してないインスタンスは、発生していないだけで実際には不安定になっていたのか? それともエラーが発生したインスタンスのみ何か起こったのか?
といったデータは取ることができずに未解決なままでした。 これでは次のアクションが取れません。
この時点では「 DBコネクションプールからのコネクションの取得失敗 」が原因であることを想定していました。
モニタリング環境整備
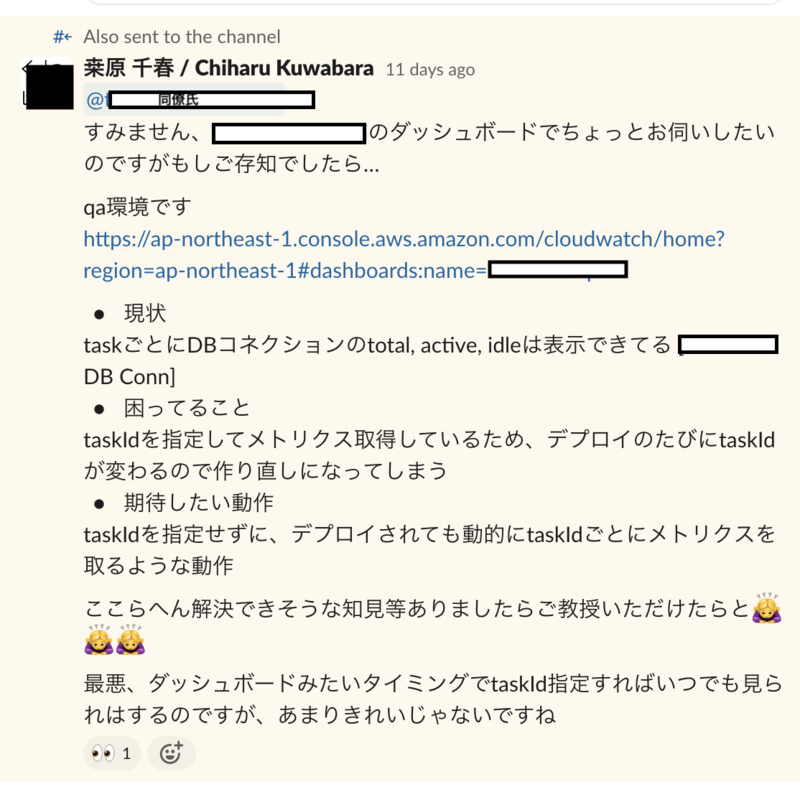
まずエラー発生しているときに、インスタンスで何が起こっているか? を正確に認識する必要があります。
今回の問題ではインスタンスごとのDBのコネクション関連、「全体のコネクション数」、 「アイドリング数」、 「アクティブ数」をモニタリングすれば何かわかるかもしれないと想定し、それぞれのモニタリング環境を整えることを優先タスクにしました。
taskId単位のモニタリング方法
JMXを使用して、 追加の Prometheus ソースのスクレイピングと、それらのメトリクスのインポート を参考に CloudWatch dashboards にメトリクスをグラフ表示させました。
複数のECSタスクに対する 「全体のコネクション数」、 「アイドリング数」、 「アクティブ数」 を1つのグラフにまとめるところで少々苦戦しましたが、ここは同僚の助けを借り解決できました。
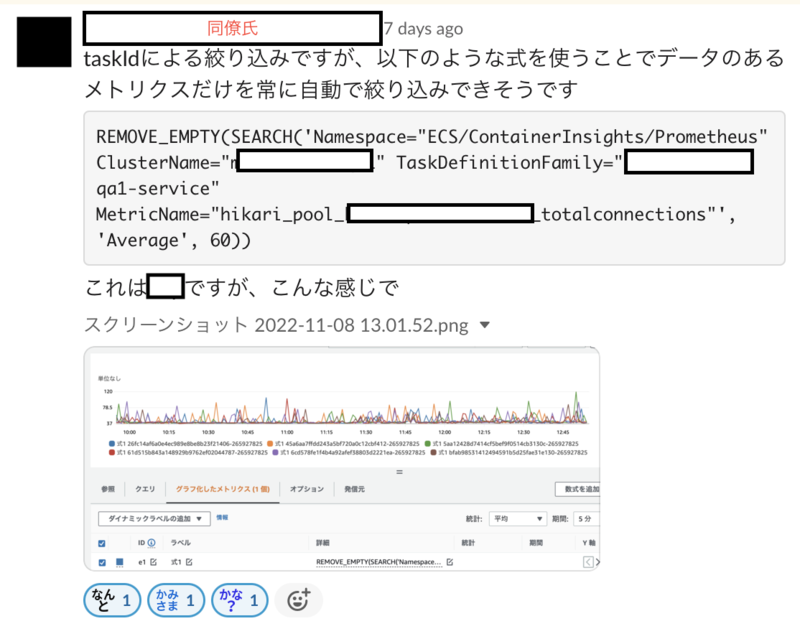
ポイントは metric_declaration の dimensions を
"metric_declaration": [
{
...(略)
"dimensions":[
["ClusterName", "TaskDefinitionFamily", "TaskId"]
],
...(略)
]
とした上で、
メトリクスのexpression に
REMOVE_EMPTY(SEARCH('Namespace="ECS/ContainerInsights/Prometheus" ClusterName="対象のClusterName" TaskDefinitionFamily="対象のTaskDefinitionFamily" MetricName="メトリクス名"', 'Average', 60))
を定義することで、1つのグラフでまとめることができました。
複数のexpressionを1つの widget にまとめることで、視認性があがりました。
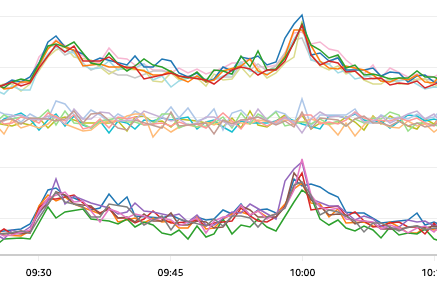
再発から原因究明
モニタリング環境を整えたあとに、再発したタイミングですぐモニタリング確認しました。

グラフを見ると、特定のインスタンスのみで アイドルコネクション数が跳ね上がっていた ことがわかります。
ログと突合したところ、エラーが発生しているインスタンスとアイドルコネクションが跳ね上がったインスタンスが同じことも判明したため、例外発生とアイドルコネクション数の急増は関係ありそうに想像できました。
そもそもアイドルコネクション数が跳ね上がっているという想定をしていなかったため、意外な現象が発生していたことがわかります。
しばらくモニタリングを続けていると、
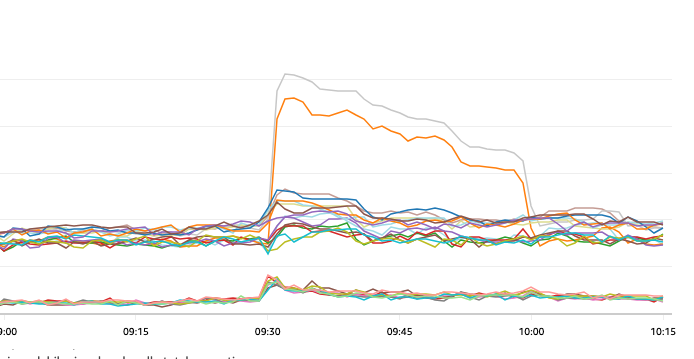
アイドルコネクション数が30分で落ち着いたようにみえます(それに伴い全体のコネクション数も落ち着いているように見られます) 。
ここで想像できるのが、 「 アイドルコネクション数が急増したことを契機としてDBコネクションが取得できなくなってしまった。 」 ということです。
仮に接続に失敗したゾンビコネクションが生き残り続けたとしたら、アイドルコネクション数が急増し、更にアクティブコネクションとして使用を試みた際にエラーが発生するのも納得できます。
この現象を調査するために、プロジェクトで使用している HikariCP のプロパティから 30分というキーワード に関連しそうなプロパティを調べたところ、maxLifetime という設定を見つけられることができました。
We strongly recommend setting this value, and it should be several seconds shorter than any database or infrastructure imposed connection time limit.
設定してなくてごめんなさいをして、適切な値に設定しました。
みんなで原因調査していたときの会話
結果
HikariCPの maxLifetime プロパティを適切に設定したところ、たまにアイドルコネクション数が一瞬跳ね上がることはあるのですが、すぐに想定通りの範囲に収まるようになりました。
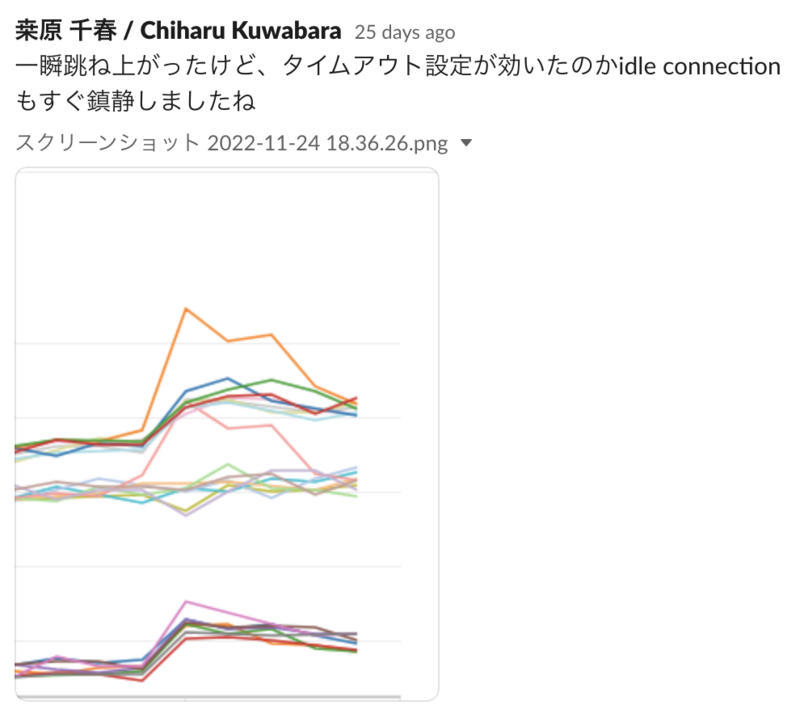
この対応が効いているのか、リクエスト数が急増してもエラーは発生していません。
まとめと今後
アイドルコネクション数が急増していることは全くイメージできておらず、モニタリング環境の整備を進めていなければ発見できなかったと思います。
また、モニタリングで見えた「30分」という数値を元に検索することで、設定すべきプロパティを見つけることができたことは想像以上のモニタリング環境の恩恵を受けられたと思います。
そして、maxLifetime の設定によりエラーの発生は抑えられてます。
しかしながら、なぜアイドルコネクション数の急増が発生しているかは未だ原因がわかっていません。
今は対処療法としての対応ができているだけですので、そもそもの原因究明を考えてます。今後 JDK Flight Recorder を導入することで解決の糸口になることを期待して、導入するための環境準備を進めています。
We are Hiring
日々改善を繰り返してより良い環境を目指してます。そして一緒に働くメンバーを募集してます! 是非このページをご覧ください!