こちらはエムスリー Advent Calendar 2023 11日目の記事です。

Overview
A/Bテストをしまくっている、機械学習エンジニアの農見(@rookzeno)です。皆さんA/Bテストをしてますでしょうか。エムスリーでは色々な施策の効果を見るために沢山のA/Bテストをしています。そのためA/Bテストを簡易にできるような設計を作ることも大事なことです。
AI・機械学習チームには、Goで書かれた機械学習関連の機能を各サービスに提供するAPIサーバがあり、こちらのYAMLファイルを設定するだけでA/Bテストが出来るようにしました。
rules: - name: modelA random_seed: 42 threshold: 50 ctrl: weight: 0 test: weight: 1 - name: modelB weight: 1
このYAMLファイルをどのようにGoのAPIで使ってるかを今回は解説します。
はじめに : 全体の構成について
このYAMLファイルをGoのAPIでどう扱っているかという話の前に、AIチームのMLプロダクトの全体構成について説明します。
AIチームでは「バッチで学習・推論して結果をDBに保存しておき、APIはDBの参照のみ行う(リクエスト時に推論をしない)」という構成をよく採用しています。今回はこの構成であることを前提としたコードになりますが、リクエスト時に推論する場合でも同じやり方はできると思います。
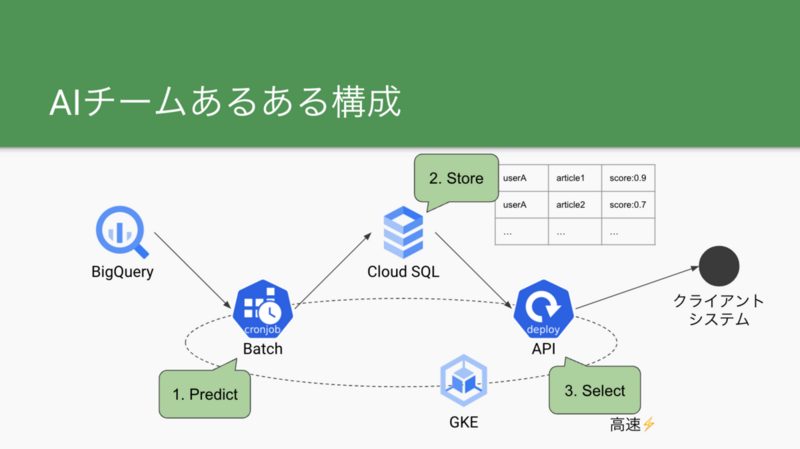
AI・機械学習チーム流MLOpsの歴史 - エムスリーテックブログより
0. YAMLファイルの解説
rules: - name: modelA randomseed: 42 threshold: 50 ctrl: weight: 0 test: weight: 1 - name: modelB weight: 1
まずこのYAMLファイルが何を示しているのかを説明します。ctrl50%ではmodelA × 0 + modelB × 1、test50%ではmodelA × 1 + modelB × 1のアンサンブルを行うという設定です。randomseedという設定があると思いますが、これはユーザーを分ける関数のseedになります。ctrlとtestには有意差がないように分ける必要があるので、適切なrandomseedを毎回選ぶ必要があります。エムスリーでは毎回そのA/Bテストにとって最適な任意の関数とrandomseedを選んでA/Bテストをしています。
このテーブルの例で具体的に説明します。
| id | modelA | modelB | ctrl | test |
|---|---|---|---|---|
| 1 | 100 | 10 | 10 | 110 |
| 2 | 0 | 15 | 15 | 15 |
modelAはid1に100点、id2に0点をつけています。modelBはid1に10点、id2に15点つけてます。この時ctrlではmodelBのみなのでid1に10点、id2に15点となりid2>id1なのでid2,id1という順番で表示します。一方でtestではmodelAとmodelBの足し算なのでid1に110点、id2に15点となりid1,id2という順番で出すことになります。このように新たなモデルを追加するとレコメンド結果が変わりその効果を見るのがA/Bテストです。
1. YAMLファイルを読み込む
ここからGoのコードでどのように処理してるかを見ていきます。まずはYAMLファイルを読み込むところからです。
YAMLファイルをGoで読み込みには以下のように書けばいいです。
import ( "context" "fmt" "io" "log/slog" "os" "gopkg.in/yaml.v3" ) type Config struct { Rules []ruleConfig `yaml:"rules"` } type ruleConfig struct { WeightValue `yaml:",inline"` Name string `yaml:"name"` RandomSeed *int `yaml:"randomseed"` Threshold *int `yaml:"threshold"` Ctrl WeightValue `yaml:"ctrl"` Test WeightValue `yaml:"test"` } type WeightValue struct { Weight *float64 `yaml:"weight"` } func ReadYaml(ctx context.Context, r io.Reader) (Config, error) { var config Config err := yaml.NewDecoder(r).Decode(&config) if err != nil { return config, fmt.Errorf("failed to decode yaml: %v", err) } return config, nil } func main() { logger := slog.New(slog.NewJSONHandler(os.Stdout, nil)) configFile, err := os.Open("config.yaml") if err != nil { logger.Error("Cannot open config file", err) } config, err := ReadYaml(context.Background(), configFile) configFile.Close() if err != nil { logger.Error("Cannot create config.Config", err) } fmt.Println(config) }
ReadYamlという関数でYAMLファイルを読み込んでます。Configという構造体を作ってタグをつけると、yaml.NewDecoder(r).Decode(&config)で自動的にパースして構造体に入れてくれるので便利です。
これでYAMLファイルをconfigという構造体に入れることができました。
このconfigを使ってDBに入ったデータを取ってきます。
2. DBからデータを取り出す
import ( "database/sql" "fmt" "strings" "github.com/jmoiron/sqlx" ) type Content struct { ID string `db:"id"` Score sql.NullFloat64 `db:"score"` } type Rule struct { Name string Weight float64 } type DB struct { pool *sqlx.DB } // テスト判定 簡易化のためuserIDにrandomSeed値を掛ける方法でやってますが、好きな方法でやってください func isTest(userID int, randomSeed int, threshold int) bool { return userID*randomSeed%100 < threshold } // user_idが属するruleのみを取得する func (c Config) GetRules(userID int) []Rule { result := make([]Rule, 0, len(c.Rules)) for _, r := range c.Rules { r, ok := r.GetRule(userID) if !ok { continue } result = append(result, r) } return result } func (r ruleConfig) GetRule(userID int) (Rule, bool) { rule := Rule{ Name: r.Name, } if r.Threshold == nil { rule.Weight = *r.Weight return rule, true } target := r.Ctrl if isTest(userID, *r.RandomSeed , *r.Threshold) { target = r.Test } if target.Weight == nil { return Rule{}, false } rule.Weight = *target.Weight return rule, true } func (d *DB) LoadScores(userID int, config Config) ([]Content, error) { rules := config.GetRules(userID) sqls := make([]string, 0, len(rules)) args := make([]any, 0) // rulesに書かれているscoreをUNION ALLで全て出す for _, c := range rules { sqls = append(sqls, fmt.Sprintf(`SELECT id, score * ? as score FROM %s_score WHERE user_id = ?`, c.Name)) args = append(args, c.Weight, userID) } sql := strings.Join(sqls, " UNION ALL ") // scoreを足し算する sql = fmt.Sprintf("SELECT id, SUM(score) AS score FROM (%s) GROUP BY id", sql) var contents []Content err := d.pool.Select(&contents, sql, args...) if err != nil { return nil, err } return contents, nil }
こちらは大きく分けて2段階に分かれています。最初がconfig構造体からuserに対するRuleのスライス(rules)を取得する部分。次がSQLにする部分です。
configにはtestやctrl等書いてありますが、ユーザー単位に落とすときにはその情報は必要ないです。なのでGetRulesでユーザーがtestかctrlどっちになるかを見て、NameとWeightのみをもつrulesにします。
rulesが出来たら後はSQLにするだけです。Goで見ると少し複雑ですが、SQLで書くとこんな感じです。
SELECT id, SUM(score) AS score FROM ( SELECT id, score * weight FROM modelA_score WHERE user_id = ? UNION ALL SELECT id, score * weight FROM modelB_score WHERE user_id = ? ) GROUP BY id
rulesに入っているモデルのscoreを全部出してgroupbyでsumしてるだけです。
これでYAMLファイルでA/Bテストができました。めでたしめでたし。
3. この方法の良い所と悪い所
良い所
- YAMLファイルを見るだけでテスト内容がわかる
- バッチ側が独立しているので好き勝手にモデルを作成して試すことができる
悪い所
- テーブル数が増えるにつれてDBの負荷が上がる
この方法の悪い所としてはバッチ側で1つのテーブルを作成してABする場合よりもDBの負荷が上がってしまうことですが、API側にロジックを持つことで、バッチ側の複雑性を下げることが出来ます。更に、今なんのモデルを試しているかをYAMLファイルを見るだけでわかるので良いかなと思ってます。
We are hiring!
AI・機械学習チームでは、A/Bテストしやすい環境を整える事も大事にしています。 環境を整えるのが好きな人はもちろん、A/Bテストするための高精度なモデルを作る人も募集しています!