AI・機械学習チームで2021年新卒の北川(@kitagry)です。
最近Zigが流行っている感じがしますね。僕もちょっとずつ勉強し始めています。 今日はZigではなく、BigQueryとPythonのお話をします。

ライブラリについて
弊チームで使っているBigQuery向けクエリのPythonライブラリについて説明します。
弊チームではバッチ処理など多くの用途でBigQueryを使用しています。 多くの場合は弊社謹製のライブラリであるgokartと組み合わせて使うことによって、結果をキャッシュして使えます。 これはスキャン量課金であるBigQueryとの相性が良く、お財布に優しく使うことができます。
そして、チーム内でよく使うクエリについてはPythonライブラリとして社内PyPiでライブラリとして使用しています。 このライブラリの利点としては
- 同じようなクエリを何度も書かなくて良い
- 修正時に一箇所の変更で済む
- 改善施策をまとめて出来る
ということが挙げられます。
しかし、いくつかの問題が発生したため今回それらの対策を打つことにしました。
問題1: BigQueryでフルスキャンが走って料金が高くなる
先ほども述べた通り、BigQueryはスキャン量ベースで料金がかかるサービスになっています。 そこで、料金を抑える方法としてよくあるのがワイルドカードテーブルを使用してスキャン量を抑える方法です。
例えばテーブルの設計が table20180101 ~ table20220101 のようなテーブルがあるとします。 ある期間のデータを取りたい場合は以下のようにSQLを叩きます。
SELECT * FROM `table*` WHERE _TABLE_SUFFIX BETWEEN from_date AND to_date
このように書くことによって、スキャン量は from_date ~ to_date までのテーブルしかスキャンしないので全tableのスキャンすることを防ぐことができます。 しかし、このワイルドカードテーブルへのクエリにサブクエリなどの定数式でない条件を使ってしまうと、途端にフルスキャンを行ってしまいます.
SELECT * FROM `table*` WHERE _TABLE_SUFFIX BETWEEN from_date AND (SELECT max(date) FROM other_table) -- この書き方を行うとtable*をフルスキャンしてしまう。
今回のライブラリでも、いくつかのクエリで誤ってフルスキャンをしてしまっているクエリがありました。 再発防止のためにCIにいくつかの変更を導入しました.
bqvalidでフルスキャンを検知する
フルスキャンを行うクエリをCIで検知するために、チームメンバーが開発したツールであるbqvalidを使用しました。 これを使うことで、上記のようなフルスキャンを行ってしまいそうなSQLをCIで防ぎます。
$ bqvalid ./sql/ one.sql:6:6: Full scan will cause! Should not compare _TABLE_SUFFIX with subquery three.sql:5:19: Full scan will cause! Should not compare _TABLE_SUFFIX with subquery
ちなみにこのエラーの防ぐ方法の一例としては以下の方法があります。
DECLARE to_date DEFAULT (SELECT max(date) FROM other_table); SELECT * FROM `table*` WHERE _TABLE_SUFFIX BETWEEN from_date AND to_date
reviewdogでCIが落ちたときに見やすくする
前述のbqvalidに加えて、Pythonに使用するflake8,mypyなどのlinterが増えてきたためローカルで全てを揃えて実行するのが少し難しくなってきます。 そのため、Pull Request内でコメントとしてlinterのエラー内容を知るために、reviewdogというツールを導入しました。
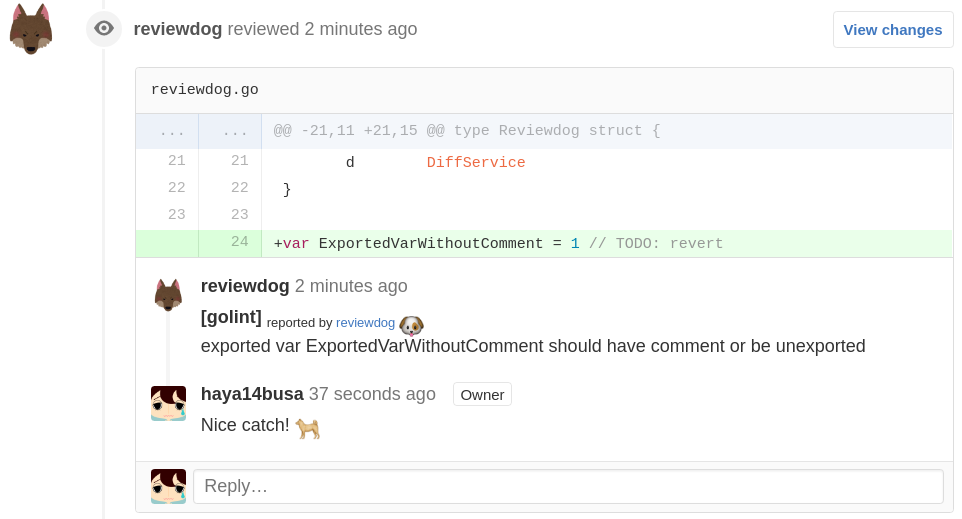
上記のbqvalidをreviewdogで使いたい場合は .reviewdog.yml に以下のように書くことによって設定できます。
runner: bqvalid: name: bqvalid cmd: bqvalid . errorformat: - "%f:%l:%c: %m" level: error
問題2: SQLのテストができない
SQLのテストをすることは多くの場合難しくなかなかテストができません。 現在使っているライブラリでも実際にリリースしたはいいが実はSQLに誤りが含まれていたということが何度かありました。 今回のようにライブラリとして使う場合、このように実際にリリースしてからエラーに気づくと解決までに時間がかかってしまうという問題があります。
CIでこのSQLの誤りを検知するためにBigQueryのdryrunというオプションを使いました。 dryrunには以下の機能が含まれます。
- SQLに文法的な誤りが含まれていた場合にはエラー箇所などを返す。
- SQLの結果のカラム名とその型まで返す。
- 実際のデータは見ないのでスキャン課金料金がかからない
- 何バイトスキャンを行いそうかのデータは返してくれる。
まさに神機能です。 エラーが起こらないかチェックしつつ、望んでいるデータ型が返ってくるかまで確認できます。
from google.cloud import bigquery from pandas_gbq.gbq import _bqschema_to_nullsafe_dtypes # private関数を使っていることに注意 class DryRunBigQueryClient: def download(self, sql: str, project_id: str, **kwargs) -> pd.DataFrame: client = bigquery.Client(project=project_id) job_config = bigquery.QueryJobConfig(dry_run=True) qb = client.query(sql, job_config=job_config) assert qb.errors is None, f'errors: {qb.errors}' columns = [s.name for s in qb.schema] astype = _bqschema_to_nullsafe_dtypes(qb._job_statistics().get("schema").get("fields", [])) return pd.DataFrame([], columns=columns).astype(astype)
上のようなClientを用意し、テスト時にDIすることによってテストの時だけdryrunで実行できます。 これによって
- SQLに文法的な誤りがないこと
- 意図したカラムが意図した型で返ってくること
の2点がテストできます。
注意点としては、毎回APIを呼び出すため非常にテストが重たくなります。(簡単なクエリなら1, 2秒くらい) そこで、pytest-xdistのようにテストの並列化を入れることによって少しでもテストの速度がましになります。 基本的にはI/OバウンドなのでCPU数よりも多くしても高速化できます。
この変更ではSQLのロジックのテストまではできませんが、弊チームでは基本的にはSQLはロジックは最小限に抑えてgokartでロジックを書く運用が主なので現在は問題はなさそうです。
まとめ
BigQuery向けクエリの社内ライブラリで長年問題と思われていたけれど手をつけられなかった問題を解決しました。
今回の取り組みでテストカバレッジを50%ほどから、78%まであげることができました。 この記事がBigQueryを使っている方の参考になればと思います。
We are hiring!!
弊社では社内で使うライブラリなどを整備してチームの生産性を爆増させるエンジニアを募集してます! 以下のURLからカジュアル面談をお待ちしています!