エムスリーエンジニアリンググループ AI・機械学習チームの中村(@po3rin) です。 好きな言語はGo。仕事では主に検索周りを担当しています。
Overview
最近の仕事で医師に質問ができるサービスで「Elasticsearchを使ってなるべく低コストで関連キーワード機能を実装する」という案件に携わっていました。本記事では関連キーワード機能を低コストで実装するための技術調査の結果と、実際に採用した方法をご紹介します。
今回紹介する方法は機械学習などは使わず、なるべく低コストである程度の品質を目指すものです。この記事を読むことで検索アプリケーションにサクッと関連キーワード機能を実装できるようになるでしょう。
検索における関連キーワード機能とは
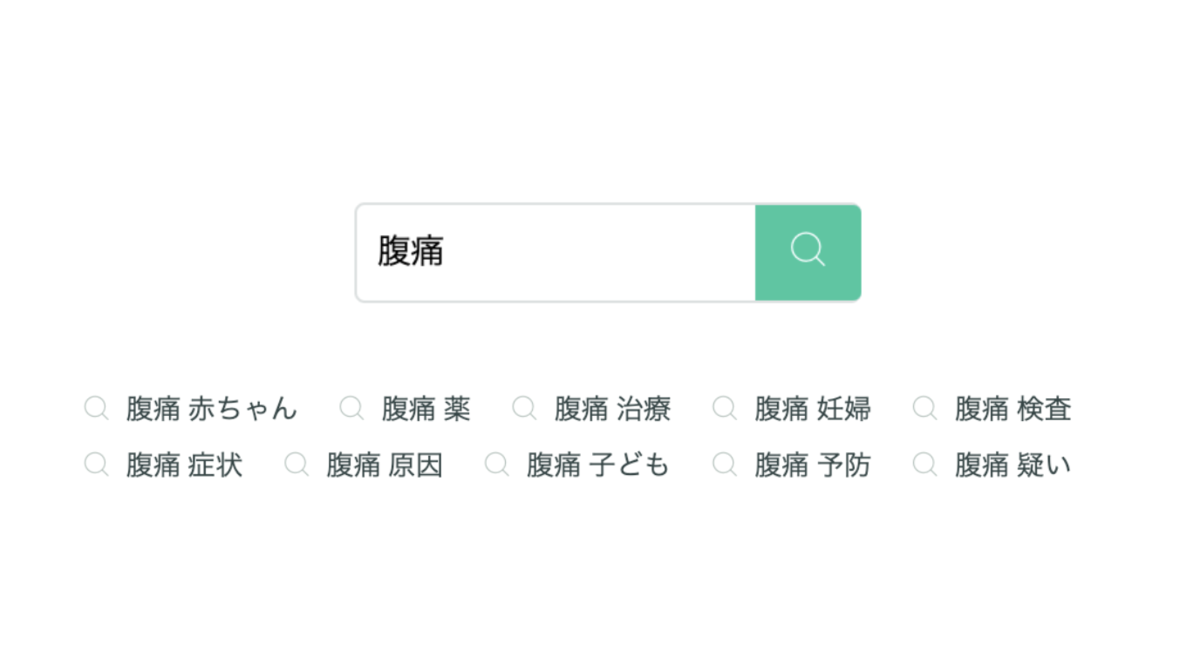
ユーザーの検索クエリに対して再検索する関連キーワードを推薦する機能です。下図のようにGoogleでは検索結果ページの下の方に関連キーワードが表示されています。

似た機能にクエリサジェストがあります。これは検索窓で入力されるキーワードの補完や一緒に検索するキーワードを推薦するものです。例えば「にほn」と検索窓に入力した場合、「日本」というクエリを推薦します。今回はこのような検索窓でのクエリサジェストは対象に含めません。Elasticsearchを使ったクエリサジェストの実装はElasticsearchの公式ブログ[1]が参考になるでしょう。
実装の前提条件
利用できるデータは下記のデータのみであるとします。
- ユーザーが検索で入力したクエリ文字列
- 過去の検索ログデータ
- 検索対象のドキュメント
もちろん検索にひもづくヒット数、クリック率などがあれば、より良い関連キーワードを算出できるはずですが、今回我々が関連キーワード機能を実装するアプリケーションは検索ログ収集基盤を絶賛構築中のサービスであり、実際に入力されたクエリ文字列しか利用できませんでした。そのため今回は上記のデータだけで実装できる方法を検討していきます。
実装パターンの紹介
今回我々が検討した手法4パターンを紹介します。
- (1) ログで出現した単語を数えあげる
- (2) ログに対するSignificant terms aggregation
- (3) ログに対してSignificant terms aggregation (形態素解析あり)
- (4) ドキュメントに対してSignificant terms aggregation (形態素解析あり)
(1) ログで出現した単語を数えあげる
こちらは検索ログをsplit tokenizerで分割したものに対してaggregations機能でクエリと一緒に出現した単語を数え上げていき、出現数上位k個を関連キーワードとする手法です。
split tokenizerは形態素解析をせず、単純にスペースや記号などで単語を分割するTokenizerです。詳しい情報は下記のドキュメントをご覧下さい。
split tokenizerを使うmappingは下記のように設定します。その他のfilterは検索アプリケーションに合わせて設定しましょう。
{ "settings": { "analysis": { "analyzer": { "split_analyzer": { "type": "custom", "tokenizer": "split_tokenizer", "char_filter": [ "html_strip", "standard_icu_filter" ], "filter": [ "trim", "ja_stop" ] } }, "tokenizer": { "split_tokenizer": { "type": "simple_pattern_split", "pattern": [ "_", " ", " ", "、", "。", "?", ",", "." ] } }, "char_filter": { "standard_icu_filter": { "type": "icu_normalizer" } }, "filter": { "ja_stop": { "type": "ja_stop", "stopwords": [ "_japanese_" ] } } } }, "mappings": { "properties": { "query_log": { "type": "text", "fielddata": true, "analyzer": "split_analyzer" } } } }
"fielddata": trueはaggregationsを利用する場合は必須の設定なので入れておきます。
下記のようなクエリを投げれば「腹痛」の関連キーワードが取得できます。query部分のsizeを0に設定しているのは検索にヒットしたログが関連キーワード機能に不要だからです。
{ "size": 0, "query": { "match": { "query_log": { "query": "腹痛", "operator": "and" } } }, "aggs": { "keywords": { "terms": { "field": "query_log", "order": { "_count": "desc" }, "size": 10 } } } }
このクエリを投げるとクエリに基づいた関連キーワードを取得できます。下記は弊社の2年分のログデータに対する実行結果です。
{ // ... "aggregations": { "keywords": { // ... "buckets": [ { "key": "腹痛", // ... }, { "key": "下痢", // ... }, { "key": "妊娠初期", // ... }, { "key": "過敏性腸症候群", // ... }, { "key": "子供", // ... }, { "key": "妊娠", // ... }, { "key": "吐き気", // ... }, { "key": "腰痛", // ... }, { "key": "食後", // ... }, { "key": "便秘", // ... } ] } } }
この手法のメリットはクエリに付加する関連キーワードとして自然な日本語が取得できる点です(後ほど形態素解析を使った手法と比較していきます)。 デメリットとしては人気のキーワードで表記が揺れるもの(がん/ガン)などが関連キーワードとして一緒に返ってきてしまう可能性があります。また、split tokenizerでは品詞によるfilterができないため、関連キーワードとしてあまり意味をなさない数字や記号などのキーワードが返ってくる恐れがあります。
(2) ログに対するSignificant terms aggregation
この手法は単純に出現数上位を返すのではなく、ElasticsearchのSignificant Terms Aggregation機能を使います。
簡単に説明すると出現数だけでなく、全体での出現頻度を考慮した手法でなります。先ほど導入したindexに対してクエリを変えるだけで実行できます。significant terms aggregationではどのスコアリング手法を使うかを選べますが。今回はGoogle normalized distance [2]を利用します。
{ "size": 0, "query": { "match": { "query_log": "腹痛"} }, "aggregations": { "significant_crime_types": { "significant_terms": { "field": "query_log", "min_doc_count": 10, "size": 10, "gnd": { } } } } }
min_doc_countは関連キーワードとして返す単語の最低出現数を設定できます。sizeはレスポンスで返すキーワードの最大数です。下記は弊社の2年分のログデータに対する実行結果です。
{ // ... "aggregations": { "significant_crime_types": { // ... "buckets": [ { "key": "腹痛", // ... }, { "key": "下痢", // ... }, { "key": "過敏性腸症候群", // ... }, { "key": "胚移植後", // ... }, { "key": "排便前", // ... }, { "key": "排便後", // ... }, { "key": "ルトラール", // ... }, { "key": "食後", // ... }, { "key": "大腸内視鏡後", // ... } ] } } }
最初に紹介した手法と比べて、腹痛により関係のあるキーワードを取得できています。一方で「妊娠」などの「腹痛」以外のキーワードとも共起する確率が高いキーワードは出現しにくくなります。そのため少し珍しいキーワードが返ってくることがあります。これは検索アプリケーション次第ではデメリットになります。またこの方法でも先ほどの手法と同じように品詞でフィルターできないなどのデメリットが残ります。
(3) ログに対してSignificant terms aggregation (形態素解析あり)
今まで紹介した2つの手法は主にsplit tokenizerを使う手法でした。ここで紹介する手法はkuromojiなどの日本語形態素解析と併用するものです。
やることはsplit_analyzerをお好みのanalzyerに差し替えるだけです。この手法のメリットは品詞によるフィルタなどが利用できる点です。
一方でこの手法のデメリットをわかりやすくお伝えするために、今回は2年分のログデータに対して「生理痛」でaggregationを行ったをお見せします。
{ // ... "aggregations": { "significant_crime_types": { // ... "buckets": [ { "key": "生理痛", // ... }, { "key": "ひどい", // ... }, { "key": "下腹部", // ... }, { "key": "酷い", // ... }, { "key": "改善", // ... }, { "key": "テグレトール", // ... }, { "key": "リー", // ... }, { "key": "マス", // ... }, { "key": "緩和", // ... }, { "key": "書", // ... } ] } } }
日本語として不自然な結果が返ってきています。特に「リー」と「マス」が不自然です。これは「リーマス」という医薬品が未知語であるために形態素解析されてしまった結果です。このように形態素解析を使った手法では未知語を不自然な日本語に分割してしまう可能性があります。
(4) ドキュメントに対してSignificant terms aggregation (形態素解析あり)
今まで紹介した3つの手法では関連キーワードをクエリに付加して再検索をかけるとヒット数が0になってしまう可能性があります(ログごとのヒット数を利用すれば回避できますが、今回はクエリ文字列だけを利用するという前提があります)。絶対にヒット数が0の関連キーワードを生成したくない場合はドキュメントに対するSignificant terms aggregationが一考に値します。
ドキュメントに対するSignificant terms aggregationはログデータを利用せずに検索対象のドキュメントデータだけを利用する手法で、検索で上位にヒットしたドキュメントには関連のあるキーワードが含まれているという仮定で成立する手法です。ドキュメントに含まれるキーワードは基本的にスペース区切りではないため必然的に形態素解析の利用が必須になります。
「生理痛」で検索した結果を示します。クエリは対象のフィールドをログからドキュメントに変えるだけで実行できます。
{ // ... "aggregations": { "significant_crime_types": { // ... "buckets": [ { "key": "生理痛", // ... }, { "key": "部", // ... }, { "key": "周期", // ... }, { "key": "膜", // ... }, { "key": "婦人", // ... }, { "key": "腰痛", // ... }, { "key": "排卵", // ... }, { "key": "不正", // ... }, { "key": "筋腫", // ... }, { "key": "子宮", // ... }, { "key": "卵巣", // ... } ] } } }
これらのキーワードはドキュメントから引っ張ってきているので検索結果が0件になることはありません。一方で形態素解析を行うので不自然な日本語が出てくる可能性は残ります。また、初期クエリの検索結果top-kから関連キーワードを持ってくるのでkの値次第では関連キーワードで検索しても初期クエリと比較して検索結果があまり変わらない恐れもあります。
実装パターンの比較
今まで紹介した方法を比較していきます。比較には下記の環境を用意しました。
* Elasticsearch v7.10.1 * Analyzerはkuromojiを利用 * 1クエリで返る関連キーワード数は最大10件と設定 * 過去のクエリからランダムに100件を評価用に利用 * 利用するログデータは2年分のデータ
ログデータに関しては弊社で開発、運営しているAskDoctorsのログデータ2年分を使って評価します。AskDoctorsは医師に質問できるサービスで、相談事例を検索できる機能があるのでそのログを利用します。
評価指標設定
下記は実際に我々が関連キーワード機能を実装するに当たって設定した指標になります。
1: 関連キーワード総数 2: 日本語として不自然な関連キーワードの出現確率 3: ヒット数が0件になる関連キーワードの出現確率 4: 初期クエリの結果top10件のうち8件以上同じコンテンツが表示される関連キーワードの出現確率 5: ある関連キーワードに対して8件以上結果が重複する関連キーワードが出現する確率 6: 実装、運用コスト(5段階)
上3つは分かりやすい指標かと思います。
4つ目の指標は、初期クエリの結果との重複率が高いと関連キーワードとして推薦してもあまり意味がないためです。
5つ目の指標は、似たキーワードで検索すると似た結果が返るという仮説に基づいて、関連キーワードリストの中に類似語などが入ってしまっているケース等を測るための指標です。推薦する関連キーワードリストに「痛い」と「痛み」が入っているとユーザーにとって関連キーワードが重複しているように見えてしまうので類似語、活用が違うだけのキーワードなどはリストから取り除く必要があります。
6つ目の指標は、主観でざっくりと実装運用コストを5段階で見積もったものです。
ちなみに2つ目の指標の「日本語として不自然な関連キーワード」は全件目視で確認しました。
実装4パターンをこの指標で測った結果は下表になります。

この結果から、日本語として不自然な結果を含んでしまう③と④は選択から除外しました。残るは(1)と(2)です。ぱっと見は(2)の方が良さそうですが、(2)で得られる関連キーワード数が(1)より明らかに少ないこと、また(2)は手法紹介の節でもお話ししましたが、関連キーワードの中でも初期クエリ"だけ"に関連が強いキーワードしか返ってこないという点から、今回我々は(1)の手法を選択しました。
類似語の除去についての考察
ここまで4つの実装パターンを検討しましたが、全ての手法で類似語や活用だけの差があるキーワードなどが発生する可能性があります。例えば「痛み/痛い」「妊娠/妊娠中」などです。これらのキーワードがあるとユーザーにとって同じキーワードが並んでいるだけに見えてしまい非常に見栄えが悪いだけでなく、関連キーワードとして提案できる幅が減ってしまいます。
これらをシノニム辞書で全て吸収するのは困難なので、何かしら別の手を打つ必要があります。
単語分散表現を使った類似語判定
この問題の解決策として単語分散表現を使うという選択肢があります。例えば日本語単語ベクトルとして公開されているchiVe [3]を利用すると類似語や活用だけの差があるキーワードをある程度見つけることが可能です。
chiVeはMagnitudeという分散表現を扱うPythonライブラリ経由で利用するのが簡単です。こちらの記事が参考になるでしょう。
例えば下記のコードで単語ごとの類似度を取得できます。
from pymagnitude import Magnitude, MagnitudeUtils # リモートでのロード vectors = Magnitude( "https://sudachi.s3-ap-northeast-1.amazonaws.com/chive/chive-1.2-mc15.magnitude") print(vectors.similarity("痛み", "病気")) print(vectors.similarity("痛み", "痛い")) print(vectors.similarity("妊娠中", "妊娠")) print(vectors.similarity("ぶつけた", "ぶつける"))
これを実行すると単語の類似度が0~1の範囲で取得できます。
python chive.py 0.4237097 0.66561085 0.8114295 0.7468979274167429
類似度の閾値を設定することで関連キーワードのリストから似た単語を削除することが可能です。
採用した類似語のルールベース除去
単語の分散表現を利用しない方法として、とりあえず目に見えている発生パターンをルールベースで除去することが考えられます。このルールベースの実装では「疑わしきは除去」の精神でガンガン除去していきます。
ここからは我々が用意した除去ルールを簡単に紹介します。
- 1文字目の漢字が一致し、後続が任意のひらがなだった場合は活用が違うシノニムと判断して除去
- ひらがな/カタカナの差だけのものを除去
- サブ文字列の部分一致を除去
1つ目のルールでは「痛い/痛み」「張る/張り」などの重複をリストから取り除きます。このルールにより活用が違うだけのものや、品詞が違うだけのものを取り除けます。
2つ目のルールでは「胃がん/胃ガン」などの重複をリストから取り除きます。特に医療用語ではカタカナ/ひらがなの揺れが大きいため、これらの対応が必要です。
3つ目のルールでは「妊娠/妊娠中」「鬱/鬱病」などの重複をリストから取り除きます。これは違う意味の単語もリストから除去してしまう可能性があります。例えばこのルールだと「癌/抗癌剤」の組み合わせも削られてしまいます。しかし「疑わしきは除去」の精神でこれらもガンガン除去しております。
類似語の除去のまとめ
手法(1)に対して(1-1)類似語の除去なし、(1-2)単語分散表現の利用、(1-3)ルールベースの除去の3つの方法で評価したものが下表になります。

単語分散表現を利用した際には「ある関連キーワードに対して8件以上結果が重複する関連キーワードが出現する確率」が5.11%から3.48%にまで落とすことが出来ました。一方でルールベースの類似語除去では5.11%だったのを2.54%にまで落とすことが出来ました。単語分散表現の方法よりもルールベースの方が1%ほど改善しています。
また実装コストを考えると我々のチームで単語分散表現を利用しようとするとPythonのマイクロサービスを立てる開発コストが発生するため。今回の実装ではルールベースでの除去を採用しました。
一旦採用を見送った単語分散表現ですがルールベースでは捉えられないパターンがあるため、今後パラメータ調整などで精度を改善していった上で実践投入することは十分にありえます。
検討結果
結果的に、実装コストが低いながらも初回リリースに出せるだけの品質があると判断し「ログで出現した単語を数えあげる」手法に「ルールベースの類似語除去」を組み合わせた手法を採用しました。
まとめ
今回はElasticsearchを使った関連キーワード機能がどれだけ低コストで実装できるかを調査し、実際に採用した手法をご紹介しました。検索アプリケーションによっては我々が採用した手法が合わないケースもあるのでご注意ください。
今後はクエリ文字列以外のデータ(ヒット数、CV数、パーソナルデータ)も考慮した関連キーワードが推薦できるようにアルゴリズムをアップデートしていきたいと考えています。
We're hiring !!!
エムスリーでは検索基盤の開発&改善を通して医療を前進させるエンジニアを募集しています! 社内では最近、検索チームを中心に「Elasticsearch & Lucene コードリーディング会」が発足し、検索の仕組みに関する議論も活発です。
「ちょっと話を聞いてみたいかも」という人はこちらから!
Reference
[1] Elasticsearchで日本語のサジェストの機能を実装する