【QAチーム ブログリレー4日目】
はじめに
こんにちは、QAチームの草場です。
レーモン・クノーの『文体練習』という本をご存知でしょうか? 1947年に出版されたこの本は、とある短い1ストーリーを99通りの文体で書きわけるもので、語られるのは同じストーリーなのに文体を変えるだけで得られる情報や印象の変化を感じられる味わい深い本です。
今回は「文体練習」を参考に、システムの仕様を表す文体として最適なものは何か? もしくは文体による差は無いのか?をカジュアルに実験してみました。

仕様は、書き手や場面によって様々な文体で書かれることがあります。決められた書式で厳密に書かれた物、広く知られた記法では無いが構造的に整理された物、Slackに貼られたメモのような物、ユーザーからの口伝を文字起こしした物など、多種多様です。どのテキストでも同じ機能の話をしているとして、そこから読み取れる情報量やテスト観点の数は、同じなのでしょうか? 異なるのでしょうか?
このように、実験してみました。架空のフードデリバリーアプリの注文フローを11の文体で書き分け、それぞれをAIに読ませてテストケースを生成させ、事前に人間が作成したテストケースに対するカバレッジを比較するというものです。
結論を先に言うと、文体によるカバレッジの差はありました。ただし、それ以上にAIの実行ごとのブレや評価方法の影響が大きく、「文体にこだわる必要は薄い」という結果になりました。以下、実験の詳細と結果です。
- はじめに
- 実験の概要
- 同じシーンを11文体で書き分けると
- 結果: 確かに差は出た
- Top Tierの5文体はほぼ同じ結果
- 文体の差より効いたこと
- まとめ: AI時代の文体選びの考え方
- 余談
- We're hiring!
実験の概要
対象
架空のフードデリバリーアプリ「QuickEats」の注文フロー。レストラン検索からカート追加、決済、配達追跡、評価までを含みます。誰でも使ったことがあるサービスで、AIにも十分ドメイン知識があることを想定しています。
11の文体
現場で実際に見かける記述スタイルを11個用意しました。
Gherkin / 箇条書き / 散文調 / ユーザーストーリー / フローチャート / 会話形式 / 表形式 / 要件定義書風 / メモ書き / 契約による設計風(Design by Contract) / スクリーンショット指示
各文体の特性に従って「自然に」書くというルールにしました。あえて、その文体で書けば自然に抜け落ちる情報はそのままにします。「文体が情報の取捨選択に影響する」現象そのものを観測したいからです。
評価方法
各文体をClaude(Sonnet 4.6)のサブエージェントに入力し、同一プロンプトでテストケースを生成させます。生成されたテストケースを、事前に人間で用意した26個のテスト観点と照合し、カバレッジを測ります。
AIの確率性を見るため 各文体で5回ずつ実行。合計55回の実行です。また、同じAIに生成と評価の両方をさせると客観性に欠けるため、生成するAIエージェントと評価するAIエージェントを別にしました。
なお、本実験ではコンテキストエンジニアリングやプロンプトチューニングをいっさい行っていない「素のClaude Code」を使いました。システムプロンプトの仕込みも、few-shot例の追加も無しです。
同じシーンを11文体で書き分けると
結果を出す前に、文体の違いを体感してもらうために、1つ見てもらう実験があります。
「商品をカートに追加する」というシーンだけを取り出して、11文体がそれぞれどう書いているかを並べてみます。同じ出来事なのに、11通りに書き分けると、読む印象がこれほど違います。長くなりますが、クノーの『文体練習』を追体験する意味でもスクロールしながら眺めてください。
Gherkin
Scenario: 商品をカートに追加する Given レストラン「麺屋たろう」のメニュー画面を開いている When 「味噌ラーメン」を選択する And サイズ「大盛り」を選択する And トッピング「味玉」を追加する And 「カートに追加」ボタンを押す Then カートに「味噌ラーメン 大盛り 味玉」が追加される And カートアイコンに個数「1」が表示される
厳格で、テスト自動化にはそのまま使えそうです。一方で「売り切れだったらどうなる?」「価格はいくら?」には触れていません。
散文調
メニューをスクロールしていく。味噌ラーメン、醤油ラーメン、つけ麺。味噌ラーメンにしよう。タップすると、オプション画面が出てきた。サイズは大盛りにして、味玉もつけよう。合計980円。「カートに追加」を押す。
ユーザーの気持ちの流れは伝わります。でも操作手順の境界が曖昧で、テスト設計には使いにくそうです。
要件定義書風
3.3 メニュー閲覧及び商品選択(REQ-ORD-003)
(2)利用者が商品を選択した場合、本アプリは当該商品に関するオプション(サイズ、トッピング、調理方法の指定等。以下、「商品オプション」という。)の選択画面を表示するものとする。商品オプションの内容及び価格は、各レストランパートナーが設定するものとする。
(3)利用者は、商品及び商品オプションの選択を完了した後、当該商品をカートに追加することができるものとする。
(4)商品が売り切れ(在庫切れ)の状態にある場合、本アプリは当該商品が現在利用できない旨を表示するとともに、可能な範囲において代替商品の提案を行うものとする。
厳密なようで厳密ではない文体ですが、売り切れ時の代替商品提案といった観点が定義されています。他の文体では触れられていない観点です。
極端に簡潔(メモ書き)
商品選ぶ → オプション(サイズ、トッピング等)→ カート追加
時間がない時にSlackに書き殴ったような3行メモ。
残り7文体
箇条書きステップ
5. 商品を選ぶ 6. オプションを指定する(サイズ、トッピング、辛さ 等) 7. 「カートに追加」を押す(複数商品を追加する場合は手順5〜7を繰り返す)
ユーザーストーリー形式
US-004: 商品オプション指定とカート追加
ユーザーとして、商品のサイズやトッピングを選んでカートに追加したい。なぜなら、自分好みにカスタマイズした商品を注文したいから。
受け入れ条件: - サイズを選択できる(例: 並盛り/大盛り) - トッピングを追加できる(複数選択可) - オプション選択後の合計金額がリアルタイムで表示される - 「カートに追加」で商品がカートに入る - カートアイコンに商品数が表示される
フローチャート
SelectItem[商品を選択]
↓
SetOptions[オプション指定\nサイズ/トッピング等]
↓
AddToCart[カートに追加]
↓
Continue{買い物を続ける?}
Yes → BrowseMenu に戻る
No → ReviewCart[カート確認]
会話形式
ユーザー: 「マルゲリータ」を選択
システム: 商品詳細を表示。サイズ(S/M/L)とトッピング(チーズ追加、バジル増量 etc.)のオプションを提示。
ユーザー: Mサイズ、チーズ追加を選んで「カートに追加」をタップ
システム: カートに追加完了。画面下部にカートアイコン(1点、合計1,580円)を表示。メニュー画面に戻る。
表形式
| # | ステップ | 操作 | 入力データ | 期待結果 |
|---|---|---|---|---|
| 4 | 商品選択 | メニューから商品をタップ | - | 商品詳細画面が表示される。オプション選択UIが表示される |
| 5 | オプション指定 | サイズ・トッピング等を選択 | サイズ: M, トッピング: チーズ追加 | 選択内容に応じて価格が更新される |
| 6 | カート追加 | 「カートに追加」ボタンをタップ | 数量: 1 | カートに商品が追加される。カートアイコンに件数と合計金額が表示される |
契約による設計風(Design by Contract)
Operation: AddToCart Pre-condition: - selectedRestaurant ≠ null - item ∈ selectedRestaurant.menu - item.isAvailable = true Trigger: - ユーザーが商品を選択し、オプション(サイズ、トッピング等)を指定してカートに追加する Post-condition: - cart.items.contains(item, selectedOptions) - cart.totalAmount が再計算されている Exception: - item.isAvailable = false → 売り切れ通知を表示する
スクリーンショット指示
1. 注文したい商品をタップしてください 2. 商品詳細のモーダルが画面下部からスライドアップします 3. サイズ選択がある場合、ラジオボタンで「S / M / L」等が表示されます。希望のサイズをタップしてください 4. トッピング選択がある場合、チェックボックスのリストが表示されます。追加したいトッピングをタップしてチェックを入れてください 5. モーダル下部の「-」「+」ボタンで数量を調整してください 6. 画面最下部の緑色のボタン「カートに追加 ¥XXX」をタップしてください
文体を比較してみると、「拾えている観点」に違いが見えてきます。
- 売り切れの扱い: 要件定義書風と契約による設計風だけが明示。散文やメモ書きは触れていない
- 具体的な数値: 散文は「980円」、会話形式は「1,580円」と自然に書かれるが、価格に触れていない文体が多い
- UIの見た目: スクリーンショット指示だけが「緑色のボタン」「モーダル」に言及
- ユーザーの動機: ユーザーストーリーの「なぜなら〜」だけが「なぜ」を説明している
同じことを書こうとしているが、拾える観点が違う。これは確かに文体でテスト観点のカバレッジに差が出そうです。実際、AIに読ませてテストケースを生成させたら、どれだけの差が出るでしょうか。
結果: 確かに差は出た
55回の実行結果を人間が準備したテストケースと照合したところ、カバレッジに差が出ました。2層に整理したのが以下です。
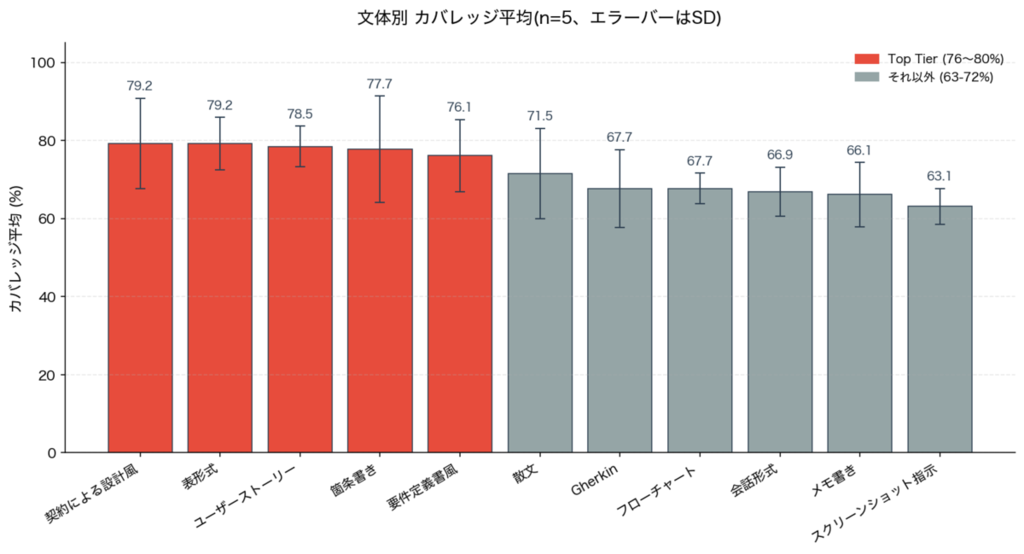
- Top Tier(76〜80%): 契約による設計風・表形式・ユーザーストーリー・箇条書き・要件定義書風
- それ以外(63〜72%): 散文・Gherkin・フローチャート・会話形式・メモ書き・スクリーンショット指示
上位と下位の差は最大16ポイント(契約による設計風 79.24% vs スクリーンショット指示 63.08%)。文体がテスト観点に影響を与えているように見えます。
ただし、ここで注意が必要です。今回の実験はAIにテストケースを生成させたものです。AIは確率的に動作するため、同じ入力でも毎回結果が変わります。もしルールベースのツール(たとえばGherkinパーサーでGiven-When-Thenを機械的にテストケースに変換するもの)を使えば、文体の差は決定的に効くでしょう。そもそもGherkin以外の文体はパースできません。以降の分析と結論は、あくまで「AIにテストケース生成を任せる場合」に限定した話です。
その前提で、結果をもう少し詳しく見てみます。
Top Tierの5文体はほぼ同じ結果
| 順位 | 文体 | 平均 | SD |
|---|---|---|---|
| 1 | 契約による設計風 | 79.24% | 11.6 |
| 2 | 表形式 | 79.22% | 6.7 |
| 3 | ユーザーストーリー | 78.46% | 5.2 |
| 4 | 箇条書き | 77.70% | 13.6 |
| 5 | 要件定義書風 | 76.14% | 9.3 |
| 6 | 散文 | 71.54% | 11.6 |
| 7 | Gherkin | 67.68% | 10.0 |
| 7 | フローチャート | 67.68% | 3.9 |
| 9 | 会話形式 | 66.92% | 6.3 |
| 10 | メモ書き | 66.14% | 8.2 |
| 11 | スクリーンショット指示 | 63.08% | 4.6 |
1位(契約による設計風)と2位(表形式)の差は0.02ポイント。1位と5位の差も約3ポイントです。一方で、同じ文体でも実行ごとのバラつき(SD)が5〜13ポイントあります。文体間の差よりも、同じ文体内のブレの方が大きいため、5回の実行ではこの順位に意味があるかどうかを判断できません。
また、同じ文体・同じプロンプト・同じ入力でも実行ごとに結果がブレます。たとえば箇条書きは61.5%〜100%の間を行き来しました。5回の実行で毎回上位5文体の順位が入れ替わるため、この実験からは「Top Tier内のどれが優れているか」は言えません。
一方で、Top Tier(76〜80%)とそれ以外(63〜72%)の間には傾向としての差が見えます。ただしこれもn=5での観察であり、サンプルを増やせば変わる可能性があります。
ここから言えるのは、AIにテストケース生成を任せる場合、Top Tierの5文体の中ではどれを選んでも大きな差はなさそうだということです。だとすれば、文体の微妙な優劣を追求するよりも、AIの運用の仕方に時間を使う方が実質的な改善につながるのではないか。実験の中で、文体の差以上に結果を左右する要因が3つ見えてきました。
文体の差より効いたこと
1. 実行ごとのブレが大きい
各Runの全文体平均カバレッジを並べるとこうなります。
| Run | 平均カバレッジ |
|---|---|
| Run1 | 59.3% |
| Run2 | 79.8% |
| Run3 | 69.6% |
| Run4 | 74.7% |
| Run5 | 70.5% |
Run1とRun2では 20ポイント の差があります。同じプロンプト、同じモデル、同じ入力です。Run1がなぜこれほど低かったのかは正直分かりません。
この事実は、「AIにテスト生成を1回だけ任せて、その結果を鵜呑みにする」のが危険であることを示しています。1回の実行結果は±20ポイントのブレを含みうるのです。
対策: 重要な仕様については最低3〜5回実行して、結果を比較する。これだけで文体の差よりも大きな改善が見込めます。
2. 生成と評価を分離する
当初は生成と評価の両方を同じAIエージェントに任せていました。「この仕様からテストケースを作って、照合してください」というプロンプトです。その結果、要件定義書風はRun2で100%を記録し、1位候補になっていました。
しかし、同じAIに生成と評価の両方をさせると客観性に欠けるため、生成するAIと評価するAIを別エージェントに分けて再計算しました。すると、要件定義書風の同じ結果は84.6%まで下がりました。同じ生成結果を、違うエージェントが評価すると15ポイント動いたことになります。
原因が「最初のエージェントの判定が甘かった」のか、「別エージェントの判定が厳しすぎた」のかは特定できません。ただ、AIに品質を測らせるときは、評価者が1つだと結果が大きく動くという事実は確認できました。
対策: AIに品質を測らせる時は、生成と評価を別エージェント・別プロンプトで分離する。
3. 文体で拾えない観点を別添えする
実験で用意した26観点のうち、どの文体を使っても一貫して拾えなかった観点が5つありました。
| ID | 観点 | missingになりやすい理由 |
|---|---|---|
| E01 | 異なるレストランの商品をカートに追加 | どの文体でも例示されない |
| E02 | 注文中にレストランが閉店 | タイミング依存のエッジケース |
| E06 | 注文確定後の配達先住所変更 | 後工程の話題 |
| N02 | 検索応答速度 | 非機能要件は機能フローに書かれない |
| N04 | 決済セキュリティ | 同上 |
これらは文体を変えても解決しません。元のユースケース記述に書かれていないので、どれだけ綺麗な文体で書いてもAIは拾えません。
対策: エッジケースと非機能要件は、仕様書本体ではなく別のチェックリストとして用意する。
まとめ: AI時代の文体選びの考え方
55回の実験を経て得られた結論をまとめます。繰り返しになりますが、これはAIにテストケース生成を任せる場合の話です。
- Top Tierの5文体(契約による設計風・表形式・ユーザーストーリー・箇条書き・要件定義書風)は実質同値。どれを選んでも結果は変わらなかった
- それ以外(散文・Gherkin・フローチャート・会話形式・メモ書き・スクリーンショット指示)は単体使用には弱いものが多かった。ただし、要件定義書風のように「単体で完結する前提ではなく、関連文書とセットで使う」という前提の文体もあり、単純な優劣で判断するのは避けたい
- Top Tierの中からは、書き手と読み手が上手く扱えるものを選ぶ
- その時間を、複数回実行・評価の分離・エッジケース別添えの3つに振り向ける
余談
クノーの『文体練習』は、同じ出来事でも語り方で意味が変わることを見せてくれる本でした。仕様書でも確かに語り方で意味は変わります。ですが、AIにテストケース生成を任せる場合、Top Tier内での文体の差よりも、実行ごとのブレや評価者による判定の揺れの方が大きな影響を持っていました。
もちろん、ルールベースのツール(Gherkinパーサー等)を使う場面では、文体の選択が決定的に重要です。ただ、AIを活用してテストケースを生成する場面では、Top Tierの中からチームが慣れているものを選び、浮いた時間を複数回実行の自動化やエッジケース・非機能要件のチェックリスト整備に振り向ける方が、品質への寄与は大きいと考えています。
この記事の社内レビューで、「以前の会社でオフショアにテストタスクを出していた頃は、文章を丁寧に練り上げないと抜け漏れが出ていた。AIだとその辺りのレベルは上がってますね」というコメントをもらいました。確かにその通りで、AIは事前学習知識でドメインの常識をある程度埋めてくれます。だからこそ、文体の最適化より、文体では解決できない部分への投資が重要になっているのだと思います。
今回はフードデリバリーという誰もが知っているドメインを使ったため、AIが事前学習知識で補完できた面があります。AIが馴染みのない特有ドメインでは、仕様書に書いてあることだけが頼りになるので、文体の差がもっと開く可能性があります。どのような記載が適しているかは、開発チームで評価する必要があるでしょう。
We're hiring!
エムスリーでは、QAも大絶賛募集しています! 少しでも興味をお持ちでしたら、ぜひカジュアル面談などでお話しましょう!