デジカル開発メンバーの末永(@asmsuechan)です。電子カルテの開発を通して医師や医療事務の方の「書く」をサポートしています。
みなさん、マークダウンでテキストを書いていますか?私はマークダウンで書くことが好きで、プレーンテキストでもほとんどのメモをマークダウン記法で書いてしまいます。この記事もはてなのマークダウンを使って書いています。*1
マークダウンを使えるサービスを挙げていくとGitHubやStackOverflowなど開発者ならば誰しも知るサービスが多く出てきます。このことからもわかるように、マークダウンはもはや開発者とは縁の切れないものとなっています。
しかし、普段の開発時によく使うマークダウンですが、実際にはどのような仕組みで動いているのかを知る人は少ないのではないかと思います。
この記事ではオリジナルのマークダウンパーサ「minute」をTypeScriptを使ってハンズオン形式で作っていくことでマークダウンの内部実装への理解を深めます。
※マークダウンパーサの開発は筆者の趣味でありデジカルの業務とはなんの関係もありません。
- 1. マークダウンとは
- 2. マークダウンの方言
- 3. マークダウンパーサ概要
- 4. 処理系の概要
- 5. minute
- 6. パッケージの作成
- 7. トークンを作る
- 8. 字句解析器(Lexer)のひな型を作る
- 9. 構文解析器(Parser)のひな型を作る
- 10. 構文解析器の作り込み
- 11. コード生成器(Generator)を作る
- 12. リスト要素の実装
- 12.4 リストと太字の組み合わせ
- 13. 終わりに
- We are hiring!
この記事は先日弊社の社内勉強会(テックトーク)で発表したものを再構成したものとなっています。以下は発表時に使った資料です。(なお本記事で書いたソフトウェアの構成は発表時と比べて変わっております)
1. マークダウンとは
この記事を読んでおられる方はご存知の方が多いと思いますが、マークダウンとは何かについて触れておきます。
以下がマークダウンで書かれたテキストの例です。
# Heading 1 * List * nested List **bold**__italic__
こう書くと以下のようなHTMLに変換してくれます。
<h1>Heading 1</h1> <ul> <li>List <ul><li>nested List</li></ul> </li> </ul> <strong>bold</strong><i>italic</i>
実際にブラウザで表示するとこのようになります。

つまりマークダウンはHTMLを楽に生成するための記法と言えます。
2. マークダウンの方言
例に挙げたマークダウンはあくまで「よく使われるマークダウンの記法」でしかなく、マークダウンの文法として定められたものではありません。それ以前にマークダウンには定まった(きちんと合意の取られた)規格が存在しないのです。
ですのでマークダウンパーサごとに少しずつ記法に違いがあり、それが例えば以下に示すような方言として知られています。
- GitHub Flavored Markdown
- GitLab Flavored Markdown
- mrkdwn (Slack)
これらのマークダウンはだいたい同じ書き方になるように設計されていますが、それぞれ独自に拡張されており記法に若干の違いがあります。
2.1 CommonMark
この「サービスごとのマークダウンの微妙な違い」を解消するために生まれたのがCommonMarkです。ですが結局GitHub Flavored Markdownには勝てずCommonMarkはデファクトとはなりませんでした。
なおGitHub Flavored Markdownにもちゃんとした仕様が存在します。
このあたりの歴史の話は以下の2記事がとても分かりやすかったです。
3. マークダウンパーサ概要
上に書いたように、マークダウンの方言はそれぞれが独自の実装です。よってこの記事ではMinute Flavored Markdownの処理系を作っていくことになります。
マークダウンパーサを実装してみたくなったとき、よく「正規表現だけで十分」と判断して実装することがあります。実際にGoogleで検索すると正規表現を使ったマークダウンパーサの実装が結構な数出てきます。しかし、マークダウンは思ったよりも複雑なのです。以下に例を示します。
3.1 複数行に渡る要素、要素のネスト
|col1|col2|col3| |:-|:-:|-:| |**bold**|[link with ~~si~~](https://example.com)|__italic**bold**__| |left|center|right|
上のマークダウンはテーブル要素を表しています。テーブル要素は2行以上(最低行数1なら3行以上)で表現され、1行目がヘッダに表示される列名、2行目がalign指定、3行目以降が実際の行となっています。そしてこれらの行は任意の順番に入れ替えることができません。つまり行ごとの順番に意味が存在する要素ということです。
1行ごとに処理していく場合、このような要素はどうしても「状態」が必要となってきます。しかも列数は任意の数増やすことができるので、これを正規表現のみで抽出するとメンテナンス性が非常に悪くなってしまいそうです。
3.2 ぐちゃぐちゃのリスト
さて、以下のようなマークダウンで記されたリストを見てみましょう。
* 項目1
* 3文字インデント
* 1文字インデント
* 4文字インデント
マークダウンのリストはよくインデントの数でネストの深さを決めるのですが、上の例はインデントの文字数がぐちゃぐちゃです。このリストがどのように表示されるかはそれぞれのパーサの実装によります。が、一見してどのようなHTMLが出力されるかよく分かりませんね。
このぐちゃぐちゃのリストもどうにかHTMLに変換して欲しいのです。(もちろんインデントの文字数を固定してこのようなリストをパースできないようにするというのも手ではある)
このような入力もあることを考えると、正規表現だけでマークダウンパーサを実装するのは心もとなくなってきますね。
なおこのようなインデントが意味を持つ入力はリストだけではなく引用でも発生します。
4. 処理系の概要
それではようやくminute処理系の話をします。minute処理系の構成要素は3つで、字句解析器、構文解析器、コード生成器となっています。それぞれについて説明します。なお以下は概要図です。
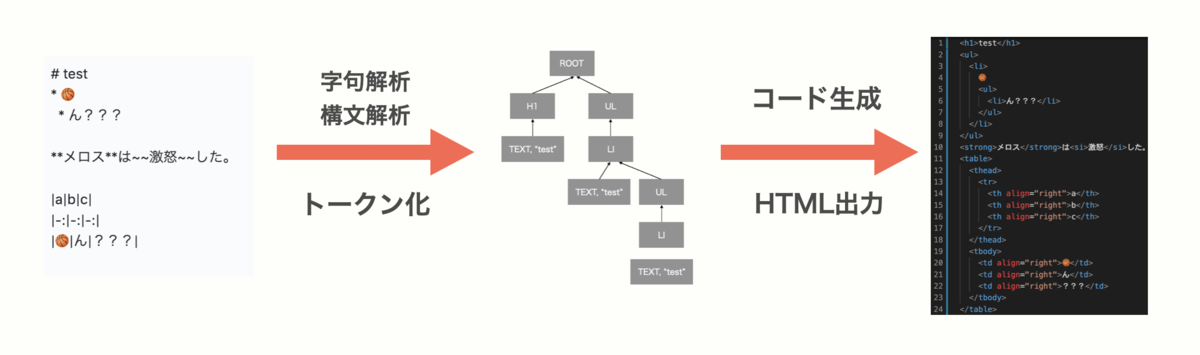
4.1 字句解析器(Lexer)
字句解析器は入力されたテキストをトークンと呼ばれるデータに変換する部分です。
一般的な処理系ではまずテキストを字句解析器でトークンに変換してそれを構文解析器に入力することが多いです。しかしminuteの字句解析器はトークン生成の便利関数を置くにとどめています。これはマークダウンには余分なスペースなどプログラミング言語によくある余分な文字が存在しないためです。
4.2 構文解析器(Parser)
構文解析器はトークン列を入力として抽象構文木(AST)を構築します。
ここがマークダウンの文法を解釈する部分です。一般的なコンパイラやインタプリタではここで構文エラーを発見するのですが、マークダウンは間違った構文はそのままのテキストとして出力します。
4.3 コード生成器(Generator)
コード生成器は抽象構文木を入力としてターゲットとなる言語のコードを生成します。ここではHTMLを出力します。
5. minute
では今から実際にハンズオン形式でminuteマークダウンパーサを作っていきます。
この記事では、マークダウンのすべての記法をカバーすると記事がとても長くなってしまう上に冗長な記述が多くなるため、太字(<strong>タグ)とリスト(<ul><li>タグ)に限定して実装していきます。
目標は以下のマークダウンが
* **bold** * list
以下のようなHTMLに変換されることです。
<ul> <li><strong>bold</strong></li> <li>list</li> </ul>
6. パッケージの作成
では実際にパッケージを作成していきます。
mkdir minute cd minute yarn init yarn add --dev typescript ts-node ./node_modules/.bin/tsc --init mkdir src
ts-nodeでTypeScriptのファイルを簡単に実行できるようにpackage.jsonのscriptsに以下を追加します。
"scripts": { "exec": "ts-node src/index.ts" },
そして次にsrc/index.tsを作成します。この関数がマークダウンをHTMLに変換する本体となっています。
// src/index.ts const convertToHTMLString = (markdown: string) => { return markdown; }
手始めにindex.tsの末尾に以下を追加してyarn run execがエラーなく実行されれば準備は完了です。
// src/index.ts (略) console.log(convertToHTMLString('Hello World!'))
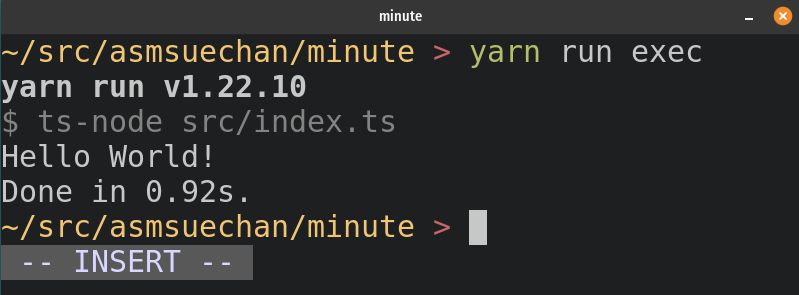
7. トークンを作る
トークンの型を作っていきます。トークンなどの型を定義するディレクトリとしてsrc/modelsを作成します。
mkdir src/models
src/models/token.tsに以下を定義してください。
// src/models/token.ts export type Token { id: number; parent: Token; elmType: string; content: string; }
それぞれの要素の説明は以下です。
| 属性名 | 説明 |
|---|---|
| id | その行を表すトークン列の中でユニークとなるidです。マージ済みトークンの位置を調べるため必要になります。(後述) |
| parent | 親トークンです |
| elmType | 要素の種別('bold'や'italic'など)です |
| content | トークンの中身です |
8. 字句解析器(Lexer)のひな型を作る
次に字句解析器を作ります。src/lexer.tsを作成します。minuteでの字句解析器の役割はあまり多くなく、正規表現といくつかの便利関数を置くにとどまります。
8.1 正規表現と便利関数たち
src/lexer.tsを以下のように変更します。STRONG_ELM_REGXPは太字(****)にマッチする正規表現となっています。
// src/lexer.ts import { Token } from './models/token' const TEXT = 'text'; const STRONG = 'strong'; const STRONG_ELM_REGXP = /\*\*(.*?)\*\*/ const genTextElement = (id: number, text: string, parent: Token): Token => { return { id, elmType: TEXT, content: text, parent, }; } const genStrongElement = (id: number, text: string, parent: Token): Token => { return { id, elmType: STRONG, content: '', parent, }; } const matchWithStrongRegxp = (text: string) => { return text.match(STRONG_ELM_REGXP); } export { genTextElement, genStrongElement, matchWithStrongRegxp }
これで字句解析器のひな型ができました。
9. 構文解析器(Parser)のひな型を作る
次に構文解析器(Parser)を作ります。src/parser.tsを作成します。このファイルにはparse()関数を置きます。
字句解析と構文解析はマークダウンテキスト1行ごとに合わせて行います。
この関数はマークダウンを1行ごとに構文解析器(Parser)にかけて、各行のトークンを木構造に並べた配列を返します。このトークンの配列が抽象構文木(AST)になります。
9.1 parse()関数
構文解析器の本体となる関数を実装します。この関数は1行のマークダウンを入力として、その行の抽象構文木を出力します。
// src/parser.ts export const parse = (markdownRow: string) => { return markdownRow }
そしてこの関数を使うようにsrc/index.tsも変更します。
// src/index.ts import { parse } from './parser' const convertToHTMLString = (markdown: string) => { const mdArray = markdown.split(/\r\n|\r|\n/); const asts = mdArray.map(md => parse(md)); return asts }
抽象構文木が複数あるのは、1行ごとに1つの抽象構文木が生成されるためです。
9.2 抽象構文木
これを見ている方は抽象構文木という言葉は耳にしたことがあるかもしれません。抽象構文木とは「入力から言語の意味に関係しない部分を取り除いたノードで構成した有向木」のことです。例えばテーブル要素を書くときに出てくる|はトークン化されるときに消される、などです。
この抽象構文木をコード生成器に入力して最終的な生成物であるHTMLを生成します。例えば以下のような有向木が抽象構文木です。
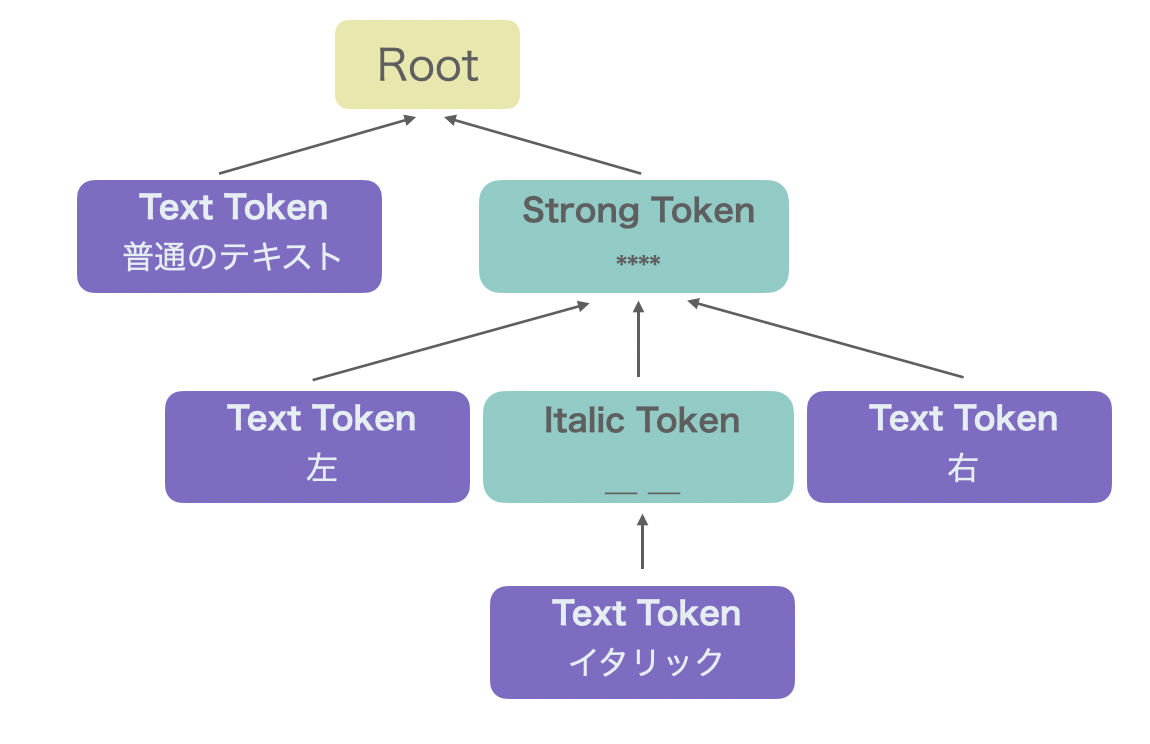
10. 構文解析器の作り込み
構文解析器を作り込んでいく前にちょっとした準備として構文木のルートを表すrootTokenを追加します。
// src/parser.ts import { Token } from './models/token' const rootToken: Token = { id: 0, elmType: 'root', content: '', parent: {} as Token, }; export const parse = (markdownRow: string) => { return markdownRow }
10.1 抽象構文木の生成(1) (****、空の太字)
まずは空の太字(****)にマッチするテキストをトークン化するコードを書いていきます。いきなりコード量が増えますが、src/parser.tsを以下のように変更します。
// src/parser.ts (前略) export const parse = (markdownRow: string) => { return _tokenizeText(markdownRow) // _tokenizeText()を使うように変更 } const _tokenizeText = ( textElement: string, initialId: number = 0, initialRoot: Token = rootToken ) => { let elements: Token[] = []; let parent: Token = initialRoot; let id = initialId; const _tokenize = (originalText: string, p: Token) => { let processingText = originalText; parent = p; // その行が空文字になるまで処理を繰り返す while (processingText.length !== 0) { const matchArray = matchWithStrongRegxp(processingText) as RegExpMatchArray; id += 1; const elm = genStrongElement(id, '', parent) // Set the outer element to parent parent = elm; elements.push(elm); processingText = processingText.replace(matchArray[0], ''); // 処理中のテキストからトークンにしたテキストを削除する _tokenize(matchArray[1], parent); // 再帰で掘る parent = p; } }; _tokenize(textElement, parent); return elements; };
_tokenizeText()関数の中にさらに_tokenize()関数を定義しています。この関数がトークン化の本体であり、再帰を使って要素を掘っています。このように再帰を用いる構文解析のことを再帰的下向き構文解析(recursive descent parsing)といいます。
また、配列elementsが抽象構文木を表す変数となっています。ここでこの配列に要素をpushしていき、コード生成器で使うときはpopで処理していくことでスタックのように扱います。
そしてsrc/index.tsの末尾に以下を追加してyarn run execを実行すると以下のような出力が得られます。
(前略) console.log(convertToHTMLString('****')

また、この出力の抽象構文木は以下のようなものになります。

10.2 抽象構文木の生成(2) (**bold**)
さて、空の太字はパースできました。では次に中身が入った**bold**をパースする処理を書きます。
**bold**を構成するトークンは**のタグトークンとboldのテキストトークンの2種類です。ですのでこの2種類に対応する必要があります。
// src/parser.ts (前略) const _tokenizeText = ( textElement: string, initialId: number = 0, initialRoot: Token = rootToken ) => { let elements: Token[] = []; let parent: Token = initialRoot; let id = initialId; const _tokenize = (originalText: string, p: Token) => { let processingText = originalText; parent = p; // その行が空文字になるまで処理を繰り返す while (processingText.length !== 0) { const matchArray = matchWithStrongRegxp(processingText); // ****にマッチしなかった要素、つまりここでテキストトークンを作る if (!matchArray) { id += 1; const onlyText = genTextElement(id, processingText, parent); processingText = ''; elements.push(onlyText); } else { id += 1; const elm = genStrongElement(id, '', parent) // Set the outer element to parent parent = elm; elements.push(elm); processingText = processingText.replace(matchArray[0], ''); // 処理中のテキストからトークンにしたテキストを削除する _tokenize(matchArray[1], parent); // 再帰で掘る parent = p; } } }; _tokenize(textElement, parent); return elements; };
src/index.tsの末尾に以下を追加してyarn run execを実行すると以下のような出力が得られます。
// src/index.ts console.log(convertToHTMLString('**bold**')

また、この出力の抽象構文木は以下のようなものになります。

10.3 抽象構文木の生成(3) (normal**bold**)
次に太字トークンの左にTextトークンが存在するマークダウンの抽象構文木を生成できるようにします。以下のif節をgenStrongElement() を実行している部分の上に配置します。
if (Number(matchArray.index) > 0) { // "aaa**bb**cc" -> TEXT Token + "**bb**cc" にする const text = processingText.substring(0, Number(matchArray.index)); id += 1; const textElm = genTextElement(id, text, parent); elements.push(textElm); processingText = processingText.replace(text, ''); // 処理中のテキストからトークンにしたテキストを削除する }
このif文はnormal**bold**のような場合にマッチするもので、このときmatchArray.indexには6が入っています。そしてgenTextElement()でnormalのTextトークンを作り、processingTextからnormalを除去して**bold**にします。
以下関数全文です。
// src/parser.ts (前略) const _tokenizeText = ( textElement: string, initialId: number = 0, initialRoot: Token = rootToken ) => { let elements: Token[] = []; let parent: Token = initialRoot; let id = initialId; const _tokenize = (originalText: string, p: Token) => { let processingText = originalText; parent = p; // その行が空文字になるまで処理を繰り返す while (processingText.length !== 0) { const matchArray = matchWithStrongRegxp(processingText); // ****にマッチしなかった要素、つまりここでテキストトークンを作る if (!matchArray) { id += 1; const onlyText = genTextElement(id, processingText, parent); processingText = ''; elements.push(onlyText); } else { // ここのif文が追加部分 if (Number(matchArray.index) > 0) { // "aaa**bb**cc" -> TEXT Token + "**bb**cc" にする const text = processingText.substring(0, Number(matchArray.index)); id += 1; const textElm = genTextElement(id, text, parent); elements.push(textElm); processingText = processingText.replace(text, ''); // 処理中のテキストからトークンにしたテキストを削除する } id += 1; const elm = genStrongElement(id, '', parent) // Set the outer element to parent parent = elm; elements.push(elm); processingText = processingText.replace(matchArray[0], ''); // 処理中のテキストからトークンにしたテキストを削除する _tokenize(matchArray[1], parent); // 再帰で掘る parent = p; } } }; _tokenize(textElement, parent); return elements; };
そしてsrc/index.tsの末尾に以下を追加してyarn run execを実行すると以下のような出力が得られます。
// src/index.ts console.log(convertToHTMLString('normal**bold**')
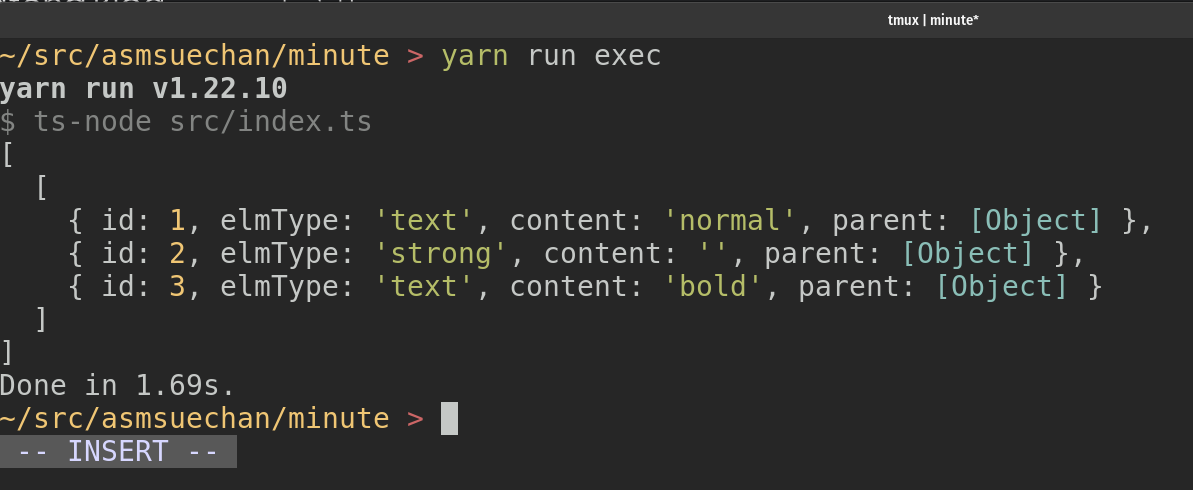
この抽象構文木は以下のような図になります。

11. コード生成器(Generator)を作る
では最後の工程としてコード生成器を作っていきます。コード生成器は抽象構文木を入力としてHTML文字列を出力するものです。
ここから創意工夫が出てくる部分ですので少し詳しく説明します。
11.1 処理の流れ
ざっくりと以下のような流れになっています。
- 抽象構文木からトークンをFILO順に取り出す
- トークンのcontentを見てHTMLのタグを生成する
- 親トークンとマージして親トークンをマージ済みトークンにする
- すべてのトークンの親がRootになるまで繰り返す
- Root以下のトークン列のcontentを結合する
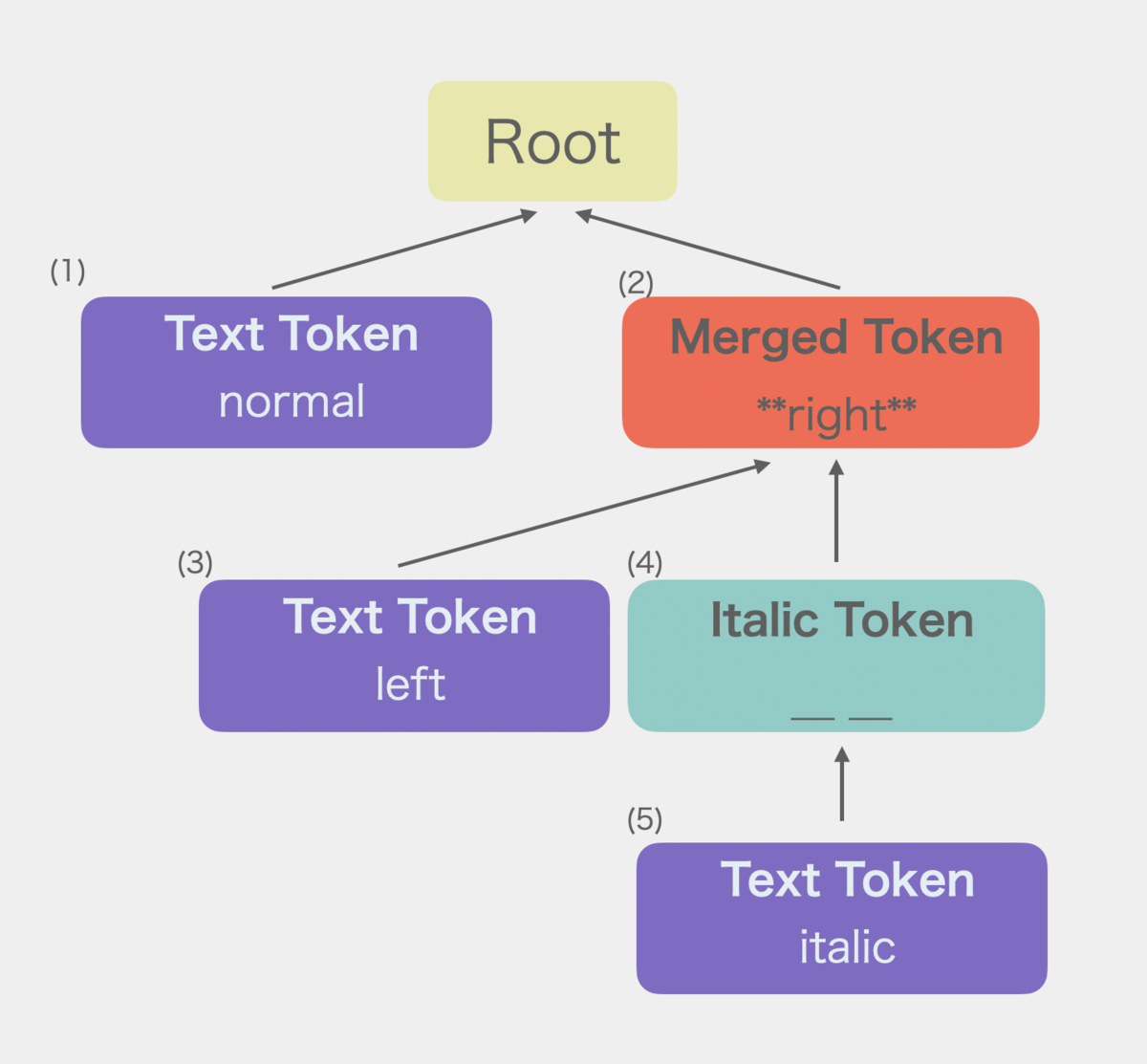
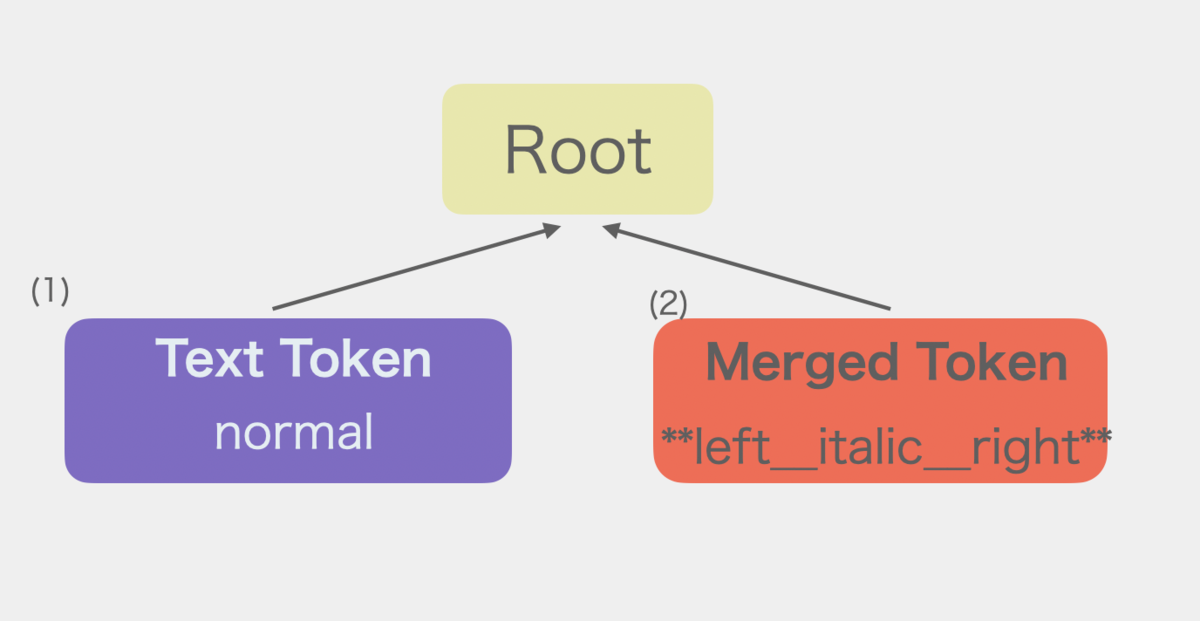
本記事ではイタリックを実装しませんが、ネストした時の様子が分かるようにnormal**left__italic__right**というマークダウンから得られた抽象構文木を例としてコード生成器の処理を追っていきます。
こちらがその抽象構文木となります。

ここでは抽象構文木を表すトークンの配列を後ろから処理していきます。後ろから処理することでFILOスタックの取り出し順でトークンを取り出すことができます。
なおトークンの配列は上の図の番号順に並んでいます(抽象構文木の配列は再帰を使って構築されているため深さ優先探索の順番に並んでいます)。
ここでマージ済みトークン(MergedToken)というものが出てきます。これは複数のトークンのcontentをマージしたトークンであり、elmType: 'merged'のものです。多分トークンをマージしてASTを作り替えていく仕組みは新規性があります。
そして抽象構文木を構成するトークンを親トークンとマージしてマージ済みトークンにしていきます。つまり構文木そのものを組み替えていきます。このマージ済みトークンを作成する際に(子)トークンのcontentからHTMLタグを生成します。
この処理はすべてのトークンの親がRootになるまで(つまり木の深さが2になるまで)行います。実際には以下のようなフローで抽象構文木を書き換えていきます。


11.2 マージ済みトークン(MergedToken)
上述のようにマージ済みトークンは子トークンのcontentがマージされた親トークンとなります。
ではsrc/models/merged_token.tsを以下のように作成します。データ構造はほとんどTokenと変わらないですが、parentがMergedTokenを取りうるという点が変わっています。
// src/models/merged_token.ts import { Token } from './token' export type MergedToken = { id: number; elmType: 'merged'; content: string; parent: Token | MergedToken; };
11.3 generator()の作成
src/generator.tsを作成します。まずはTextトークンをそのまま表示するようなものを実装します。まだ太字は無視されます。
generator()は引数としてToken[][]を取ります。これは1行ごとに1つの抽象構文木(Token[])が存在し、Token[][]はそのファイル全行分を表すためです。
この関数では1行ずつ抽象構文木を処理して結果のHTML文字列を結合していきます。
// src/generator.ts import { Token } from './models/token' import { MergedToken } from './models/merged_token' const _generateHtmlString = (tokens: Array<Token | MergedToken>) => { return tokens .map((t) => t.content) .reverse() .join(''); }; const generate = (asts: Token[][]) => { const htmlStrings = asts.map((lineTokens) => { let rearrangedAst: Array<Token | MergedToken> = lineTokens.reverse(); return _generateHtmlString(rearrangedAst); }); return htmlStrings.join(''); }; export { generate };
そしてgenerate()関数を使うようsrc/index.tsを変更します。
// src/index.ts import { parse } from './parser' import { generate } from './generator' const convertToHTMLString = (markdown: string) => { const mdArray = markdown.split(/\r\n|\r|\n/); const asts = mdArray.map(md => parse(md)); const htmlString = generate(asts) return htmlString }
src/index.tsの末尾にconsole.log(convertToHTMLString('normal')を追加してyarn run execして以下のような出力が得られれば成功です。

11.4 トークンをマージするしてASTを再構築する
ここでマージ済みトークンの作成と抽象構文木の作り変えを実装します。
_createMergedContent()はマージ済みトークンを作成するときにトークンのcontentからHTMLタグを生成、もしくは親トークンとcontentをマージした結果を返します。
抽象構文木を構成するすべてのトークンの親がRootになる(抽象構文木の深さが2になる)まで繰り返します。
// src/generator.ts const isAllElmParentRoot = (tokens: Array<Token | MergedToken>) => { return tokens.map((t) => t.parent?.elmType).every((val) => val === 'root'); }; const _getInsertPosition = (content: string) => { let state = 0; const closeTagParentheses = ['<', '>']; let position = 0; content.split('').some((c, i) => { if (state === 1 && c === closeTagParentheses[state]) { position = i; return true; } else if (state === 0 && c === closeTagParentheses[state]) { state++; } }); return position + 1; }; const _createMergedContent = ( currentToken: Token | MergedToken, parentToken: Token | MergedToken ) => { let content = ''; switch (parentToken.elmType) { case 'strong': content = `<strong>${currentToken.content}</strong>`; break; case 'merged': const position = _getInsertPosition(parentToken.content); content = `${parentToken.content.slice(0, position)}${ currentToken.content }${parentToken.content.slice(position)}`; } return content; }; const generate = (asts: Token[][]) => { const htmlStrings = asts.map((lineTokens) => { let rearrangedAst: Array<Token | MergedToken> = lineTokens.reverse(); // すべてのトークンがRootの下に付くまでマージを繰り返す while (!isAllElmParentRoot(rearrangedAst)) { let index = 0; while (index < rearrangedAst.length) { if (rearrangedAst[index].parent?.elmType === 'root') { // Rootにあるトークンの場合何もしない。 index++; } else { const currentToken = rearrangedAst[index]; rearrangedAst = rearrangedAst.filter((_, t) => t !== index); // Remove current token const parentIndex = rearrangedAst.findIndex((t) => t.id === currentToken.parent.id); const parentToken = rearrangedAst[parentIndex]; const mergedToken: MergedToken = { id: parentToken.id, elmType: 'merged', content: _createMergedContent(currentToken, parentToken), parent: parentToken.parent, }; rearrangedAst.splice(parentIndex, 1, mergedToken); // parentとマージする。 // つまり2つ変更する。子は削除。親は置き換え。 // 1つ親と合成したら1つ要素を消す。のでindexは変わらず。なのでマージしない時のみindex++する。 } } } return _generateHtmlString(rearrangedAst); }); return htmlStrings.join(''); };
ここでようやくidが出てきます。idは抽象構文木から親要素のインデックスを探すために使われます。
12. リスト要素の実装
ここまでで本記事の目標とする太字、リストの実装のうち太字部分が終わりました。では次にリストを実装していきます。以下のようなマークダウンを
* list1 * list2
このようなHTMLに変換します。
<ul> <li>list1</li> <li>list2</li> </ul>
なおリストのネストを実装すると複雑になりすぎるため、ここでは実装しないこととします(私が作った完成形には実装されてます)。リストのネストに使われるインデントの文字数は任意だしインデントが減ったり増えたりするしで、ややこしい部分です。
12.1 処理の流れ
まず、このリスト要素なのですが、先程実装した太字とは大きく違う部分があります。それは複数行にまたがっているということです。
以下のような太字とリストの混じったマークダウンがあるとき、リストをみつけたら<ul>タグを開始し内部に<li>タグを配置し、その後空行を見つけたタイミングで</ul>タグで閉じなければいけません。
normal**bold** * list1 * list2 **bold2**
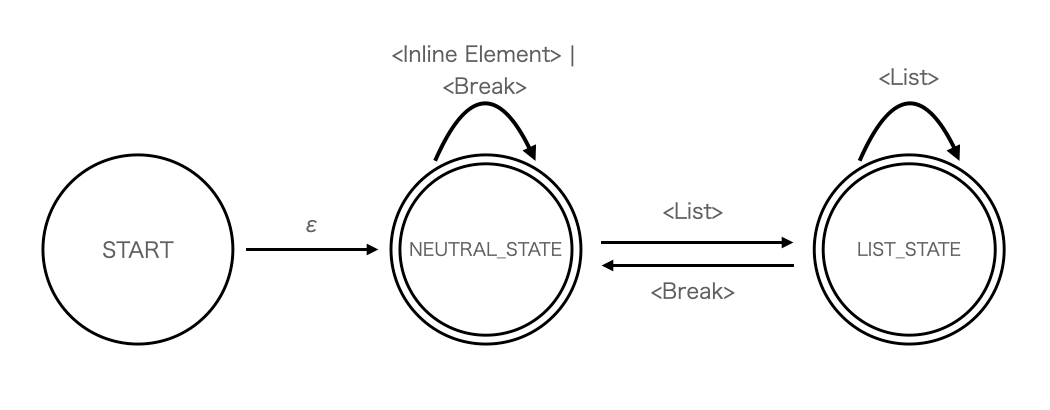
これを実現するためにはマークダウンの解釈中に現在の状態を持つ必要があります。
このマークダウンにおいて2行目まではNEUTRAL状態だったのが3行目から4行目ではLIST状態に入り5行目でNEUTRALに戻る、といった具合です。
この状態遷移図を非決定性有限オートマトン(NFA)として書くと以下のようになります。これは「12.3 リスト要素の実装(複数行のリスト)」で実装します。
12.2 リスト要素の実装(1行のリスト)
まず最初に以下のリスト要素を実装していきます。
* list1
このマークダウンは以下のように解釈されるようにします。
<ul><li>list1</li></ul>
まずは以下のようにlexer.tsに追記します。
// src/lexer.ts (略) const LIST_REGEXP = /^( *)([-|\*|\+] (.+))$/m; const matchWithListRegxp = (text: string) => { return text.match(LIST_REGEXP); } export { genTextElement, genStrongElement, matchWithStrongRegxp, matchWithListRegxp }
そしてparser.tsにtokenizeList()関数を追加します。
// src/parser.ts (略) export const _tokenizeList = (listString: string) => { const UL = 'ul'; const LIST = 'li'; let id = 1; const rootUlToken: Token = { id, elmType: UL, content: '', parent: rootToken, }; let parent = rootUlToken; let tokens: Token[] = [rootUlToken]; const match = matchWithListRegxp(listString) as RegExpMatchArray id += 1; const listToken: Token = { id, elmType: LIST, content: '', // Indent level parent, }; tokens.push(listToken); const listText: Token[] = _tokenizeText4(match[3], id, listToken); id += listText.length; tokens.push(...listText); return tokens; };
そしてparse()関数でこれを使うよう変更します
// src/parser.ts export const parse = (markdownRow: string) => { if (matchWithListRegxp(markdownRow)) { return _tokenizeList(markdownRow) } return _tokenizeText(markdownRow) }
次にコード生成器を作ります。_createMergedContent()関数を以下のように変更してください。
// src/generator.ts const _createMergedContent = ( currentToken: Token | MergedToken, parentToken: Token | MergedToken ) => { let content = ''; switch (parentToken.elmType) { case 'li': content = `<li>${currentToken.content}</li>`; break; case 'ul': content = `<ul>${currentToken.content}</ul>`; break; case 'strong': content = `<strong>${currentToken.content}</strong>`; break; case 'merged': const position = _getInsertPosition(parentToken.content); content = `${parentToken.content.slice(0, position)}${ currentToken.content }${parentToken.content.slice(position)}`; } return content; };
これでindex.tsにconsole.log(convertToHTMLString('* list1'))を追記して以下のような出力が得られれば成功です。

なおここで複数行リストを入力(console.log(convertToHTMLString('* list1\n* list2')))すると以下のようにulタグが複数作られてしまいます。

12.3 リスト要素の実装(複数行のリスト)
次にリスト要素を2行にします。
* list1 * list2
このマークダウンは以下のように解釈されるようにします。
<ul><li>list1</li><li>list2</li></ul>
リスト要素全体で1つのulタグを持ち、その中に各行をliタグとして入れ込む形になります。なお、ネストをするためにはこの中で更にulタグを使うことになります。
改行を含んだリスト全体の文字列
「_tokenizeList()関数には改行文字を含んだリストの全体を入力するようにする」を実装のアイデアとします。
_tokenizeList()関数を以下のように変更します。
// src/parser.ts export const _tokenizeList = (listString: string) => { const UL = 'ul'; const LIST = 'li'; let id = 1; const rootUlToken: Token = { id, elmType: UL, content: '', parent: rootToken, }; let parent = rootUlToken; let tokens: Token[] = [rootUlToken]; listString.split(/\r\n|\r|\n/).filter(Boolean).forEach((l) => { const match = matchWithListRegxp(l) as RegExpMatchArray id += 1; const listToken: Token = { id, elmType: LIST, content: '', // Indent level parent, }; tokens.push(listToken); const listText: Token[] = _tokenizeText4(match[3], id, listToken); id += listText.length; tokens.push(...listText); }); return tokens; };
これから字句解析器を編集していくのですが、ここでようやく字句解析器に状態管理という新しい役割が追加されます。
では実際に上で貼ったリストに関するステートマシンをsrc/lexer.tsにanalize()関数に実装していきます。
// src/lexer.ts const analize = (markdown: string) => { const NEUTRAL_STATE = 'neutral_state'; const LIST_STATE = 'list_state'; let state = NEUTRAL_STATE; let lists = ''; const rawMdArray = markdown.split(/\r\n|\r|\n/); let mdArray: Array<string> = []; rawMdArray.forEach((md, index) => { const listMatch = md.match(LIST_REGEXP); if (state === NEUTRAL_STATE && listMatch) { state = LIST_STATE; lists += `${md}\n`; } else if (state === LIST_STATE && listMatch) { // 最後の行がリストだった場合 if (index === rawMdArray.length - 1) { lists += `${md}`; mdArray.push(lists) } else { lists += `${md}\n`; } } else if (state === LIST_STATE && !listMatch) { state = NEUTRAL_STATE; mdArray.push(lists) lists = ''; // 複数のリストがあった場合のためリスト変数をリセットする } if (lists.length === 0) mdArray.push(md); }); return mdArray; };
最後にindex.tsでこれを使うようにします。
// src/index.ts import { parse } from './parser' import { generate } from './generator' import { analize } from './lexer' const convertToHTMLString = (markdown: string) => { const mdArray = analize(markdown); const asts = mdArray.map(md => parse(md)); const htmlString = generate(asts) return htmlString }
さて、これで完成しました。src/index.tsにconsole.log(convertToHTMLString('* list1\n* list2'))を追記してyarn run execを実行します。

12.4 リストと太字の組み合わせ
ついでにリストと太字の組み合わせを試してみましょう。実装はこれまでで完了しています。
normal text * **boldlist1** * list2
この場合以下のHTMLが出力されるのが期待値です。
normal text <ul> <li><strong>boldlist1</strong></li> <li>list2</li> </ul>
ではsrc/index.tsにconsole.log(convertToHTMLString('normal text\n \n * **boldlist1**\n * list2'))を追記してyarn run execを実行します。
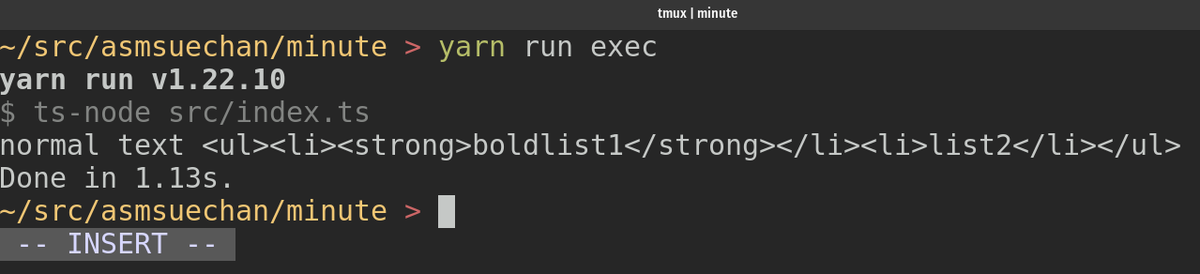
無事に期待するHTMLが出力されました。これでリストの実装は終わりになります。
13. 終わりに
この記事で作ったminuteマークダウンパーサの完全版はGitHubで公開されています。またminuteを使えるプレイグラウンドも準備しています。
この記事は私が弊社のテックトークで話した内容をベースにしています。処理系の実装が初めてだったこともあり、テックトーク時は手探りで実装した内容を調べもせずになんとなく発表しました(今資料を見返すと違和感ある部分が多い)。しかしこのテックブログを書くにあたっては的を外した記述をなるべく避けるため、しっかりと何冊かの技術書を読み理解を深めながら執筆していきました。ここで私が参考にした4冊の本を紹介しておきます。
- コンパイラ (新コンピュータサイエンス講座) | 中田 育男
- Go言語でつくるインタプリタ | Thorsten Ball, 設樂 洋爾
- 低レベルプログラミング | Igor Zhirkov, 吉川 邦夫
- 計算理論の基礎 [原著第2版] 1.オートマトンと言語 | Michael Sipser
We are hiring!
エムスリーでは医療現場の「書く」をサポートしたい人を絶賛募集中です。「処理系の話をしたい」「ちょっと話を聞いてみたいかも」「エムスリーって内資?外資?」などなどカジュアルに話をしてみたい方は以下のリンクより応募してください!
*1:ちなみに筆者は以前Boostnoteというマークダウンメモアプリのコミッターとして活動していました。