AI・機械学習チームの丸尾 @snowhorkです。
業務では主に検索基盤の開発を担当しており、検索チームではElasticsearch・Luceneのコードリーディング勉強会が毎週行われています。
この勉強会は、実際の業務にも直接役立つことが多々ある素晴らしい勉強会となっています。過去には、クエリの挙動が想定と違うというバグ報告があがったのですが、その時はKuromoji AnalyzerとPhrase Queryの組み合わせの問題で挙動が意図しないものであったと内部実装レベルで理解できました。
今回は、私が読んだLuceneのインデックスのファイル構造の一部を読み解いたので、まとめを紹介したいと思います。
Luceneのインデックス構造
Elasticsearchなどで用いられる全文検索のためのLuceneのインデックスは、セグメントと呼ばれる最小単位で、ドキュメント群のインデックスを構成しています。
Lucene 8.8.1では、インデックスを作成すると、次のようなセグメントのファイルが作成されます。
_0.si _0.cfe _0.cfs
これらのファイルは、Codecと呼ばれる、インデックスの永続化のためのフォーマットに従って作成されます。
Codecは SegmentInfoFormat (セグメントの情報のためのCodec)や PostingsFormat (転置インデックスのためのCodec)などの種類があります。LuceneのバージョンによってCodecのバージョンも変わりますが、この記事ではLucene87Codecを用いています。
.si .cfe .cfs ファイル
これら3つのファイルはそれぞれ次の役割を果たします。
.siSegmentInfoFormatに従って、セグメントのメタ情報を格納します。.cfeCompoundFormatに従って、.cfsファイルのメタ情報を格納します。.cfsCompoundFormatに従って、他のCodecのファイルを結合します。
.si ファイルはセグメント全体のメタ情報を保持しており、 .cfs ファイルが転置インデックスの本体などの他のファイルを結合して1つのファイルとしています。
次のようなコードで .cfs ファイルに含まれるファイル一覧を出力してみましょう。
public class Demo { Codec codec = new Lucene87Codec(); public static void main(String[] args) throws IOException { var demo = new Demo(); var dir = FSDirectory.open(Paths.get("./data/index")); var sis = SegmentInfos.readCommit(dir, "segments_1"); var si = sis.info(0).info; // .siファイルの読み込み var cr = demo.codec.compoundFormat().getCompoundReader(dir, si, IOContext.DEFAULT); // .cfsファイルの読み込み for (String l : cr.listAll()) { System.out.println(l); } } }
出力
_0.nvm _0.fnm _0_Lucene84_0.tip _0_Lucene84_0.tmd _0.fdm _0_Lucene84_0.doc _0_Lucene84_0.tim _0.nvd _0.fdx _0_Lucene84_0.pos _0.fdt
これらのファイルがどういったCodecによりどういった役割を持つか、以下の表にまとめました。
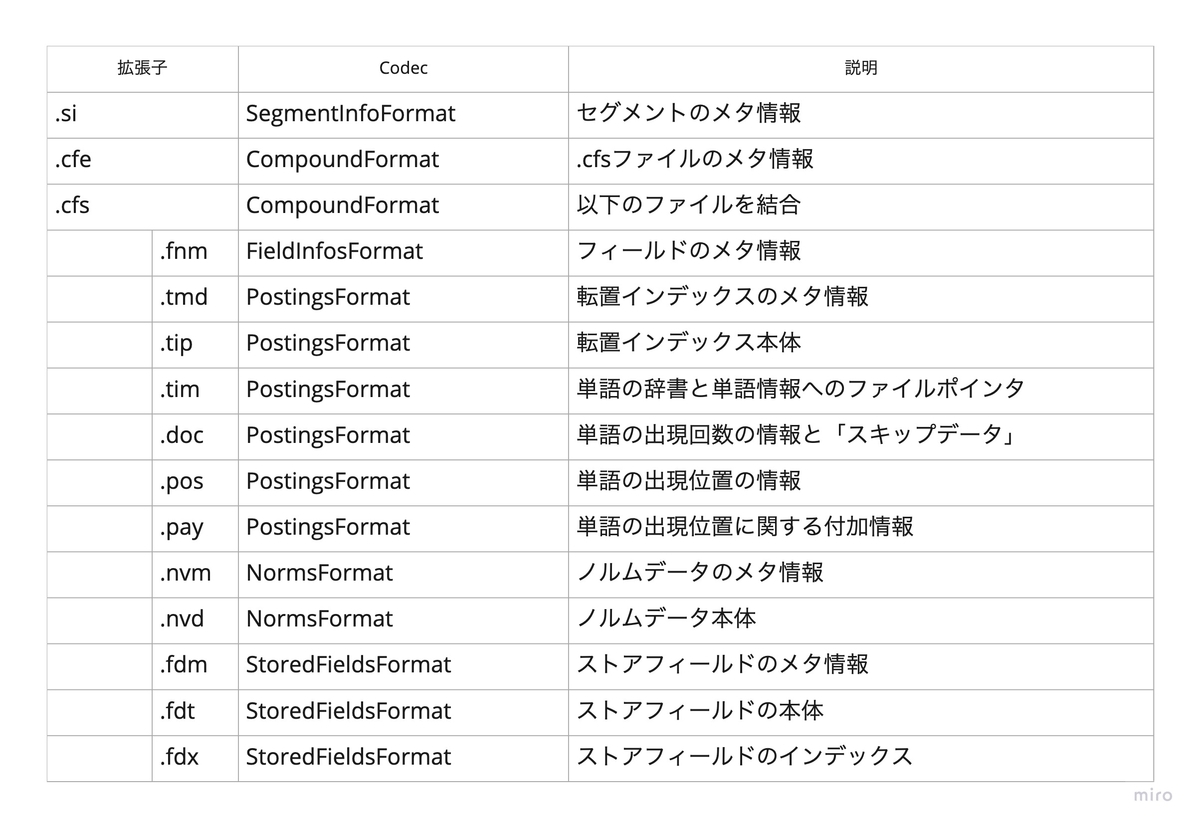
各ファイルの詳しい情報については、PostingsFormat や NormsFormat などのそれぞれのCodecのドキュメントを参照してください。
今回はさらに踏み込んで、これらのファイルの中でも、転置インデックスのための PostingsFormat のメタデータを保持する .tmd ファイルを覗いてみます。
.tmd ファイルの構造を読む
まず結論から述べると、.tmd ファイルは次の図のような構造になっています。

このファイルは、BlockTreeTermsReaderクラスによって読み取りが行われています。
例えば、次の箇所では .tmd ファイルからフィールド数を読み取り、その数だけループを行い、フィールドのメタデータを読み取っています。次のコードに現れる termsMetaIn が .tmd ファイルを参照しています。
final int numFields = termsMetaIn.readVInt(); if (numFields < 0) { throw new CorruptIndexException("invalid numFields: " + numFields, termsMetaIn); } fieldMap = new HashMap<>((int) (numFields / 0.75f) + 1); for (int i = 0; i < numFields; ++i) {
このソースコードを追っていくと、FieldReaderクラスのコンストラクタの内部で、.tip ファイルから読み取りを行い、単語の辞書のためのFST(有限状態トランスデューサ)*1をメモリに保持していることがわかります。
次のコードに現れる metaIn が .tmd ファイルを参照し、clone が .tip ファイルを参照しています。
index = new FST<>(metaIn, clone, ByteSequenceOutputs.getSingleton(), new OffHeapFSTStore());
まとめ
この記事では、セグメントファイルを開き、単語の辞書のためのFSTをメモリに保持するまでの流れを解説しました。
検索の実行時には、 .tim ファイルを読み取り、ファイルシークを効率化しながらドキュメントのIDを取得するという実装になっているのですが、その箇所についてはまだ深く読みきれていません。ですが、ここまで読んだだけでも、単語辞書自体はメモリに持っているということがわかり、大きな収穫だったと個人的には思います。
弊社では日頃からLuceneやElasticsearchの内部実装について調べており、過去にもメンバーの中村@po3rinが以下の記事も出していますので、よろしかったらそちらもご覧ください。
We are hiring!
エムスリーでは検索基盤の開発・精度向上に興味があるエンジニアを募集しています。自発的なソースコードリーディングや論文読み会などの勉強会も積極的に行われています。
カジュアル面談をこちらでお待ちしてます! jobs.m3.com