こんにちは、AI・機械学習チームの池嶋大樹です。
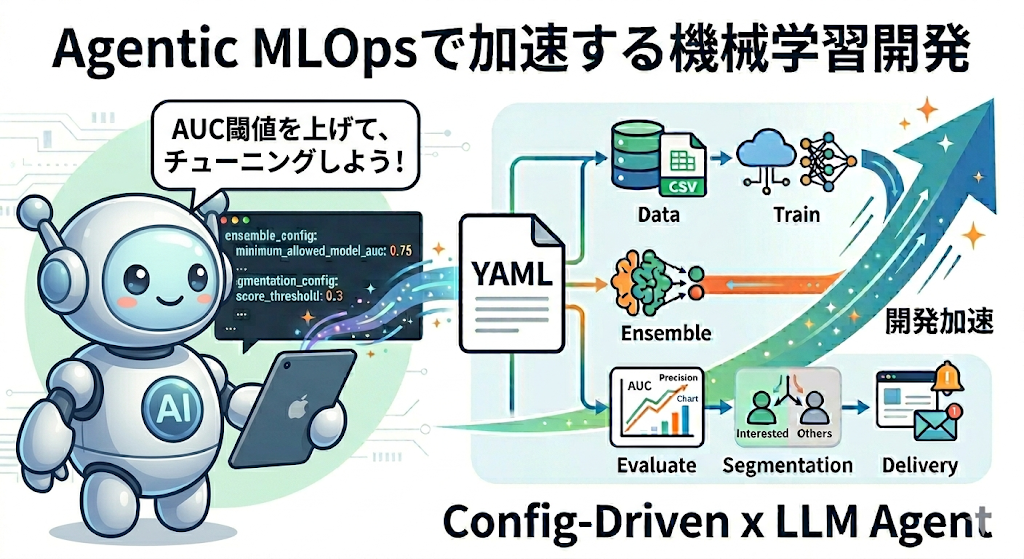
LLMエージェントがモデルの性能グラフを見ながら、YAMLの設定を自律的にチューニングしていく――そんなAgentic MLOpsを私たちのチームでは実践しています。
私たちのチームでは6年前から、YAMLで機械学習モデルの設定を管理し、設定を差し替えるだけで実験を回せるconfig-drivenな機械学習を実践してきました。 もともと実験管理やコードと設定の分離といったメリットがありましたが、LLMエージェントがYAMLの設定を自律的にチューニングできるようになったことで、開発がさらに加速しています。 本記事では機械学習におけるconfig-drivenのメリットと、Agentic MLOpsによってさらに生産性が向上した話を紹介します。
YAMLによるconfig-driven機械学習とは
m3.comでは、あるテーマに興味が高いユーザーに絞ってコンテンツを届けたい、という施策が頻繁に発生します。 例えば、ある疾患に興味がありそうなユーザーにだけ特集ページを案内する、といったケースです。 私たちのチームでは、こうした「XXXに興味が高いユーザー」をピックアップするための機械学習モデルを開発・運用しています。
対象となるテーマはさまざまな疾患や薬剤から、生活に関する情報まで多岐にわたり、テーマごとに教師データや最適化ロジックが異なります。 モデルもGBDTやNNなど複数を組み合わせたアンサンブルで構成されているため、テーマごとの設定に加え、モデルごとのハイパーパラメータや特徴量も必要になり、全体の設定項目はかなり多くなります。
そこで、これらの設定をすべてYAMLファイルに切り出し、コードを変えずに設定ファイルだけ差し替えて実験を回せるよう、config-driven機械学習を実践してきました。
例えば、次のようなYAMLファイルでモデルの構成を記述します。
# モデル設定YAMLの超抜粋(設定項目が多いと、実際には500行以上になることもある) project_config: project_name: recommend_toppage_A train_data_path: gs://bucket/train_data.csv loading_model_names: - model_a_pv_and_meta_nn - model_a_pv_and_meta_optuna_lgb - ... ensemble_config: - ensemble_name: ens_group_1 group_name: group_1 minimum_allowed_model_auc: 0.75 ensemble_max_model_counts: 15 auto_model_selection: true actual_label_columns: - actual_label_1 - ensemble_name: ens_group_2 group_name: group_2 minimum_allowed_model_auc: 0.77 ensemble_max_model_counts: 15 auto_model_selection: true actual_label_columns: - actual_label_1 segmentation_config: - group_name: group_1 single_segment_config: - ensemble_name: ens_group_1 should_extract_higher: true score_threshold: 0.3 assigned_segment: 1 - ensemble_name: ens_group_1 should_extract_higher: false score_threshold: 0.3 assigned_segment: 0
このYAMLファイルでは、project_configでプロジェクト名や学習データのパス、読み込むモデルの一覧を定義し、ensemble_configでグループごとのアンサンブル条件(どの教師ラベルで最適化するか、アンサンブルに使うモデルの最低AUC、最大モデル数など)を指定しています。
segmentation_configでは、アンサンブルモデルの予測スコアをもとにユーザーをセグメントに分割するルールを定義しています。
最終的にユーザーを「興味が高い/低い」といったセグメントに分け、興味が高いユーザーにだけ施策を配信します。
このYAMLを入力として、モデルの学習・推論・アンサンブル・セグメンテーションまでを自動実行するPythonのパイプラインスクリプトを整えているため、プロジェクトのたびにコードを触る必要はなく、YAMLを編集するだけで別プロジェクト用のモデル作成が可能になっています。
YAMLによるconfig-driven機械学習のメリット
コードと設定の分離
設定をYAMLに切り出しているため、ハイパーパラメータや特徴量を変えたいときにコードを触る必要がありません。 同じコードベースのまま、YAMLを差し替えるだけで複数のプロジェクトや実験構成を管理できるようになりました。
レビューの負担も軽くなります。 コード側はテスト済みの安全なものをそのまま使うため、レビューでは設定ファイルの内容が適切かどうかだけを確認すれば済みます。
実験管理で有利
実験条件がYAMLファイルとしてそのまま残るため、再現性が高く保てます。 「あの施策/実験の設定なんだっけ?」と振り返りたいときも、YAMLを見るだけで分かります。
YAMLをGitで管理すれば、「前回の実験から何を変えたか」が差分で一目瞭然です。 実験ごとにYAMLファイルを残しておけば、それ自体が実験ログとして機能します。
LLMを使ったAgentic MLOpsへ
ここまでのメリットは以前からあったものですが、課題もありました。 実際のYAMLは学習・モデルアンサンブル・ユーザーセグメンテーションのハイパーパラメータを細かく設定しています。 さらに、ユーザーを属性ごとに分けたグループごとにこれらを設定するため、完成版のYAMLは数百行に及びます。 グループごとに設定を分けることで推計結果の偏りを防げていましたが、設定項目が多い分、新しいメンバーにとっては慣れるまでに時間がかかる面もありました。
LLMエージェントがYAMLの設定を自律的に編集・チューニングできるようになり、この課題が大きく解消されました。 「モデルにAUCの閾値をXXXに上げて」「新しいグループを追加して」と自然言語で指示するだけで、LLMがYAMLの該当箇所を正しい書き方で修正してくれます。 設定YAMLの書き方ドキュメントを完全には理解しなくても、LLMが設定の構造を解釈した上で生成・修正してくれるため、慣れていないメンバーの学習コストが大幅に下がりました。
さらに、Claude CodeのSkillsを活用して、チューニング作業自体の自動化にも取り組んでいます。 例えば、ユーザーセグメンテーションのパラメータチューニング手順を次のようにSkillとして定義しています。
# セグメンテーション閾値チューニング スキル ## 核心原則: inference推論分布とprecisionのバランス チューニングでは以下の2つを同時に満たすことを目指す: 1. inferenceの各セグメント人数比率が、教師データの人数比率に近いこと 2. 各セグメントのprecision(positive rate)が良好であること ## Step 1: ベースライン実行 `segmentation_config` で全員を同一セグメントに割り当てて実行し、モデル性能を確認する。 ## Step 2: グラフからの閾値決定 `grouped_performance_rank_1.png` のビン境界値をもとに閾値を決定する。 ## Step 3: YAMLの編集と再実行 閾値を高い順に設定する。セグメント数は3〜4が現実的。 ## Step 4: 評価と反復 inference推論分布とprecisionの両方を確認し、必要に応じて閾値を調整する。 ...
実際のSkillはより詳細ですが、LLMがこのSkillに従い、YAMLの閾値を編集 → パイプラインを実行 → 結果を評価 → 再調整、というサイクルを自動で回してくれます。 LLMが実際にモデルの性能グラフを見て、precisionやセグメント割合を分析しながら閾値を調整していく様子は、見ていても面白いものです。
LLMの操作対象がYAMLに限定されており、モデル実行はテスト済みの既存Pythonスクリプトなので、安心して任せられます。
現状では局所解にハマることもあり、教師データの作り方を変えるといった判断にはまだ人間が必要です。 しかし、チューニングのサイクルをLLMが高速で回してくれるおかげで、最適な閾値を見つけるまでの効率は大幅に向上しました。
まとめ
YAMLによるconfig-driven機械学習は、コードと設定の分離や実験管理といった従来のメリットがあります。 そしてAgentic MLOpsの時代になり、自然言語での設定編集やSkillsによる自動チューニングなど、YAMLの扱いやすさがさらに活きるようになりました。
設定ファイルの複雑さという課題も、LLMエージェントが正しい書き方で生成・修正してくれることで解消されつつあります。 config-drivenで設計しておくと、エージェントの操作対象をYAMLに限定できるため安全に自動化しやすい、というのも大きな学びでした。
機械学習の設定管理にお悩みの方は、config-driven機械学習 × Agentic MLOpsをぜひ試してみてはいかがでしょうか。
We are hiring!
エムスリーでは、AI・機械学習を活用したプロダクト開発を一緒に進めてくれるエンジニアを募集しています。 興味のある方は、ぜひ次のリンクからご応募ください。