【Unit1 ブログリレー3日目】こんにちは。エンジニアリンググループ Unit1 の 河野那緒 です。ブログリレーではココまで生成AI活用に関する記事が続いておりましたが、本日は チームSRE が行なっている活動の一つを取り上げたいと思います。
Unit1 (MR君ファミリー開発チーム) では Web講演会 という医師に向けた情報の講演会ライブ配信サービスや MR君 という製薬会社の MR と医師とのコミュニケーションを支えるサービスをはじめとして、多様なサービスおよびその社内向け管理ツールを開発・運用しております。
詳細はこちらをご覧いただけたらと思います。 speakerdeck.com
当チームのサービスについては現在主に AWS を利用しており、またアプリケーションサーバーについては ECS(Fargate) を採用しております。 ソースコードの管理としては GitLab を採用しております。
これまでデプロイで ECS タスクの起動などに失敗した場合にすぐ気付けるようにして信頼性を高めるため、主要なサービスでは GitLab の CI ツールを通じて aws ecs wait services-stable コマンドを利用してデプロイの成功を監視し、デプロイ失敗時には通知する処理を追加しておりました。
例:
script:
- aws ecs update-service --service "<<ECSサービス名>>" --cluster "<<ECSクラスタ名>>" --force-new-deployment
# 15秒間隔 * 最大40回 ステータスチェックを行い、デプロイが完了するまで待つコマンドを実行する。それが正常終了したかタイムアウトしたかで成功判定する。
- |-
aws ecs wait services-stable --services "<<ECSサービス名>>" --cluster "<<ECSクラスタ名>>" || FAILED=true
if ! [ $FAILED ]; then
# 成功時の処理を記述
else
# 失敗時の処理を記述
exit 1
fi
一方で現在運用している ECS クラスタは、Unit1 だけでも本番環境で約 25 個、開発環境で約 70 個もある状況となっております。
多様なサービスを展開している状況下で全てのサービスに追加しようとした場合に、次の問題を抱えることになりました。
- 各サービスのリポジトリ全てのCIに処理を追加および保守する場合の工数の高さ
- デプロイ起因以外での ECS タスク起動失敗を検知できない。
- 例:こちらの記事のようなケース www.m3tech.blog
そこで、当チームでは ECS タスクの異常発生時に EventBridge に届けられるイベントを元に、包括的に起動失敗を検知して通知する仕組みを実装することで解決することにしました。
今回は、その方法を terrafrom での実装例を交えて紹介したいと思います。
検知方法の仕組み図
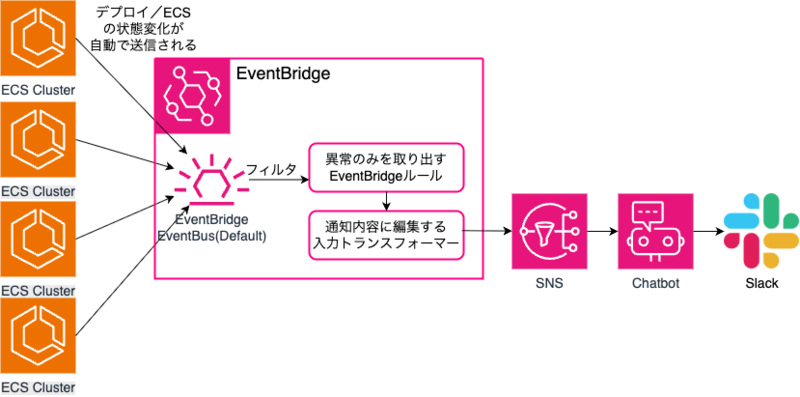
検知方法について
ECSタスクのデプロイが失敗および異常が発生した際のイベントを拾い上げる
AWSのEventBridgeには様々なリソースの変更などに応じてイベントが通知されます。その中でECSタスクの異常に関するものを拾い上げることを考えます。 使えそうなECSイベントタイプとしては次の2種類がありました。
- ECSサービスの状態変化を検知する「ECS Service Action」docs.aws.amazon.com
- ECSサービスデプロイ状態変更イベントを検知する「ECS Deployment State Change」docs.aws.amazon.com ※こちらはデプロイメントサーキットブレーカーが有効なECSサービスの場合に限り、異常を検知できます
またその中から平常状態を表すイベント(anything-butに記述されているもの)については除外することで通知することにしました。
resource "aws_cloudwatch_event_rule" "deploy_failure" { name = "deploy_failure" description = "notify alerts when a deployment fails" state = "ENABLED" event_pattern = jsonencode({ detail = { eventName = [{ anything-but = ["SERVICE_STEADY_STATE", "CAPACITY_PROVIDER_STEADY_STATE", "SERVICE_DEPLOYMENT_IN_PROGRESS", "SERVICE_DEPLOYMENT_COMPLETED"] }] } # サーキットブレーカありのものは「ECS Deployment State Change」、なしのものは「ECS Service Action」で検知する detail-type = ["ECS Service Action", "ECS Deployment State Change"] source = ["aws.ecs"] }) }
拾い上げたイベントをメッセージ用に整形して AWS SNS に送信
今度は EventBridge の Transformer 機能 を利用して、その EventBridge から受け取ったイベントを通知の形に整形させることを考えます。
detail.clusterArn キーが最有力の識別子となりますでしょうか。
ただし Transformer 機能では、 Arn 形式で渡される変数の中身を加工することは出来ないようです。 ECS のクラスタ名だけを抽出して表示したりコンソールへのリンクを生成したい場合は、別途 Lambda を挟んだ加工が必要になります。
今回は通知頻度が低い見込みのため、費用対効果を鑑みて Lambda を使わない範囲内でメッセージを加工して AWS SNS に送信することにしました。
resource "aws_cloudwatch_event_target" "notify_slack" { rule = aws_cloudwatch_event_rule.deploy_failure.name arn = aws_sns_topic.alert_slack.arn target_id = "${var.envname}-slack-notifications" role_arn = aws_iam_role.eventbridge_to_sns.arn input_transformer { input_paths = { "cluster_arn" = "$.detail.clusterArn” "event_name" = "$.detail.eventName" "region" = "$.region" } input_template = replace(replace(jsonencode({ content = { textType = "client-markdown" title = ":warning: ECSタスクのデプロイの異常を検知しました: <cluster_arn>" description = "タスクのステータス: <event_name> \n ECSへのリンク: https://<region>.console.aws.amazon.com/ecs/v2/clusters" } metadata = { threadId = "<cluster_arn>” #同一の対象から短期間に連続して通知が来た場合はスレッドにまとめる。 } source = "custom" version = "1.0" } ), "\\u003c", "<"), "\\u003e", ">") } } # AWS SNS Topic に送信するために必要な権限の付与 resource "aws_iam_role" "eventbridge_to_sns" { name = "eventbridge_to_sns" assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [ { Effect = "Allow" Principal = { Service = "events.amazonaws.com" } Action = "sts:AssumeRole" } ] }) } resource "aws_iam_policy" "eventbridge_to_sns_policy" { name = "eventbridge_to_sns_policy" policy = jsonencode({ Version = "2012-10-17" Statement = [ { Effect = "Allow" Action = "sns:Publish" Resource = aws_sns_topic.alert_slack.arn } ] }) } resource "aws_iam_policy_attachment" "eventbridge_to_sns_attachment" { name = "eventbridge_to_sns" roles = [aws_iam_role.eventbridge_to_sns.name] policy_arn = aws_iam_policy.eventbridge_to_sns_policy.arn }
AWS Chatbot の設定およびそれに送信する AWS SNS の設定
resource "aws_sns_topic" "alert_slack" { name = "<任意の名前を設定してください>" } resource "aws_sns_topic_subscription" "alert_slack" { topic_arn = aws_sns_topic.alert_slack.arn protocol = "https" endpoint = "https://global.sns-api.chatbot.amazonaws.com" raw_message_delivery = false } resource "aws_chatbot_slack_channel_configuration" "slack" { configuration_name = "<任意の名前を設定してください>" iam_role_arn = aws_iam_role.slack_alert_role.arn slack_channel_id = "<SlackチャンネルIDを設定してください>" slack_team_id = "<SlackチームIDを設定してください>" sns_topic_arns = [aws_sns_topic.alert_slack.arn, aws_sns_topic.alert_slack_use1.arn] guardrail_policy_arns = ["arn:aws:iam::aws:policy/CloudWatchReadOnlyAccess"] } # AWS SNS からAWS ChatBot に送信するのに必要な権限について resource "aws_iam_role" "slack_alert_role" { name = "<任意の名前を設定してください>" assume_role_policy = jsonencode({ Version = "2012-10-17", Statement = [ { Action = "sts:AssumeRole" Effect = "Allow" Sid = "" Principal = { Service = "chatbot.amazonaws.com" } }, ] }) } # CloudWatch Logs の ReadOnly 権限をつける # https://repost.aws/ja/knowledge-center/sns-aws-chatbot-message-troubleshooting resource "aws_iam_role_policy_attachment" "slack_alert_role_attachment" { role = aws_iam_role.slack_alert_role.name policy_arn = aws_iam_policy.slack_alert_policy.arn } resource "aws_iam_policy" "slack_alert_policy" { name = "<任意の名前を設定してください>" policy = data.aws_iam_policy_document.chatbot_notifications_only_policy.json } # CloudWatch の権限をつける # https://docs.aws.amazon.com/chatbot/latest/adminguide/chatbot-iam-policies.html#read-only-notifications-policy data "aws_iam_policy_document" "chatbot_notifications_only_policy" { statement { actions = ["cloudwatch:Describe*", "cloudwatch:Get*", "cloudwatch:List*"] effect = "Allow" resources = ["*"] } }
おまけ: 通知システム自体の失敗検知
最後にもしこの通知システム自体の実行が失敗したときにそれに気づけるよう、システム自体の失敗検知を行う CloudWatch Alarm を作成しました。
- eventBridge側での処理失敗を検知する。
resource "aws_cloudwatch_metric_alarm" "deploy_failure_invocation" { alarm_name = "deploy_failure_invocation_alarm" alarm_description = "デプロイ失敗通知(deploy_failure)Eventbridgeの実行に失敗しています。設定を確認してください" comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = 1 metric_name = "FailedInvocations" namespace = "AWS/Events" period = 60 statistic = "Sum" threshold = 1 dimensions = { RuleName = aws_cloudwatch_event_rule.deploy_failure.name } alarm_actions = [aws_sns_topic.alert_slack.arn] }
- AWS Chatbot側で受け取ったメッセージを正常にSlackに送信できなかったケースを検知する。
# AWS Chatbotはus-east-1リージョンにあるので、リージョンの違いを考慮する必要がある。 resource "aws_cloudwatch_metric_alarm" "unsupported_events_invocation" { provider = aws.use1 alarm_name = "unsupported_events_invocation_alarm" alarm_description = "AWS ChatbotのSlack通知でサポートされていない形式のメッセージが受信されたため、Slack通知に失敗しています。設定を確認してください" comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = 1 metric_name = "UnsuporoortedEvents" namespace = "AWS/Chatbot" period = 60 statistic = "Sum" threshold = 1 alarm_actions = [aws_sns_topic.alert_slack_use1.arn] } resource "aws_sns_topic" "alert_slack_use1" { provider = aws.use1 name = "<任意の名前を設定してください>" } provider "aws" { alias = "use1" region = "us-east-1" }
まとめ
この方法の優れている点:
- 1つの AWS アカウント共通で 各ECS サービスに適用されるため、ECS サービスで統一されて運用されている場合は設定運用コストが低いです。
- CI側でデプロイが正常に行われたか確認するまで待つ必要がないため、CIの実行時間に依存するコストを抑えられます。
この方法の問題点:
- ECS タスク起動失敗とCI実行を直接は紐づけられないため、誰が CI を実行したかの自動確認は難しいです。
- 失敗頻度が十分に低くて確認の手間がほぼ増大しない場合、もしくは確認担当者が CI 実行と無関係に特定の人になる場合は許容しやすいと思います。
- GCP など他のクラウドサービスと併用して共通化できない場合やアカウントが多岐に分散されている場合は、保守工数が高くなります。
当チームの場合
- ほとんどのサービスを AWS ECS を利用して展開していたため、これにより一括で全サービスのデプロイ失敗を検知ができるようになりました。
- 一方で CI によるデプロイ失敗検知が既に導入されていたサービスについては、開発ペースが速く検証環境でのデプロイ失敗が頻発しやすい状況で、失敗時にはCI 実行者に直接メンションする仕組みが引き続き便利でした。そのため主要なサービスについては廃止することなく引き続きCI によるデプロイ失敗検知も併用することにしました。
We are hiring!
エムスリーでは日々新しいサービスや機能の開発に勤しんでおります。それに伴い、多種多様に連携し合うサービスをより効率的に運用し可用性を高めていくことに興味のある SRE も募集しております。少しでもご興味をお持ちの方は、以下ページよりカジュアル面談等にお申し込みください! jobs.m3.com