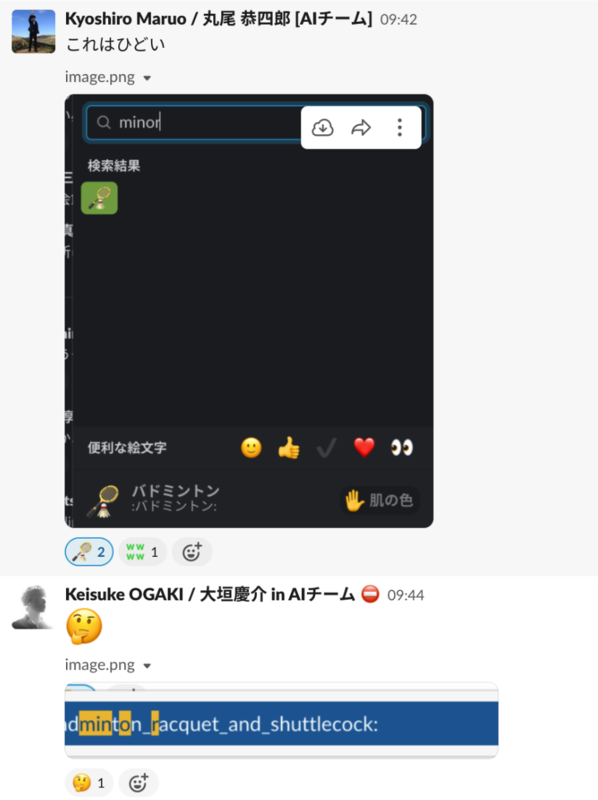
Slackの絵文字入力サジェストって意外と不思議な挙動をする。普通に部分一致だと思って入力しがちだけど、時々ハッと、あれなんでこの絵文字がサジェストされたんだ?って意外な挙動をすることがある。
例えば上記の会話では、なぜかminorって入力したら"バドミントン🏸"がサジェストされまてます💢*1*2 ここから、Slackの絵文字サジェスト面白いねって話になりました。
ってことで、今回は、Slackの絵文字サジェストアルゴリズムを機械学習で模倣する、ひいては、こういう、ブラックボックスな入出力システムがあったときに、機械学習でそれをコピーするってどうやってやるんだろ、って話をします。

こんにちは、AI・機械学習チームリーダーの大垣(@Hi_king)です。 これは エムスリー Advent Calendar 2022 の2日目の記事です。 前日は同じAI・機械学習チームの中村さん(po3rin)による、自作 Terraform Registry でした。
TL;DR
この記事でする話
- 決定的だがブラックボックスのアルゴリズムをリバースエンジニアリング的に学習ベースで再現する方法
- サジェスト・検索の機械学習方法
- 複数入力の機械学習モデルの構造を、複数モデル+内積計算に変換して高速化
この記事でしない話
- 結局Slackの絵文字サジェストはどういうアルゴリズムだったん
- 完全にSlackのサジェストと一致させるまで頑張って精度を上げる
機械学習してみよう
学習データとコードはGitHubで公開していますので、以下の議論を追って気になったら是非動かしてみてください。
STEP1: 学習可能な問題に落とし込む is_match()
機械学習をする上で、最も重要なのは、解ける形の問題に落とし込むことです。
今回やりたいことは、 minor と入力したら badminton_racquet_and_shuttlecock と出してくれる関数を作ることです。
素直に考えると、生成の問題設定と考えて generate("minor") -> "badminton_racquet_and_shuttlecock" というgenerate関数を学習したくなります。
しかし、本当にそうでしょうか?Slackの絵文字サジェストは、生成している訳ではありません。
"minor"の方は自由に入力できるのに対して、"badminton_racquet_and_shuttlecock"は絵文字候補の中から、最も適したものを選んでいるに過ぎない訳です。つまり、検索ですね。
検索の問題設定は、 distance("minor", "badminton_racquet_and_shuttlecock") -> 0.1 のような距離関数を学習して、最も距離の近いものを候補から選び出す、という問題にできます。
ただし、今回は距離はSlackのAPIから得ることができませんので、学習できるのは"サジェストされたかどうか"つまり is_match("minor", "badminton_racquet_and_shuttlecock") -> Trueという二値分類問題を学習します。

STEP2: 学習データはどう作る? query x emojiの全羅列
さて、Slackの絵文字サジェストを模倣して、is_match(query, target) -> bool 関数を学習するやり方までは決めたので、データを収集します。
targetの方は決まった絵文字集合なので問題ないのですが、queryは自由な入力がなされるので、どのようにデータを集めたら良いでしょうか。 美しいやり方としては、Slackのログを取って、サジェストに投げられたqueryを収集し続けることなのですが、さすがに大変そうです。
今回は[a-z0-9]の3文字までの組み合わせの総当たりとさせていただきました*3。 あとは、ひたすらWeb版Slackを使ってSeleniumでデータ収集しました。
| 全query数 | 26011 |
| 絵文字サジェストのあるquery数 | 3405 |
| 全サジェスト数 | 21836 |
| 1クエリあたり平均サジェスト | 6.41 |
| 1度でもサジェストされた絵文字数 | 1982 [*4] |
STEP3: 実際に学習する 2つの文字列を入力するモデル
さて、3文字までのすべてのqueryについて、それにマッチする is_match(query, target) -> boolとなる関数を学習しましょう。
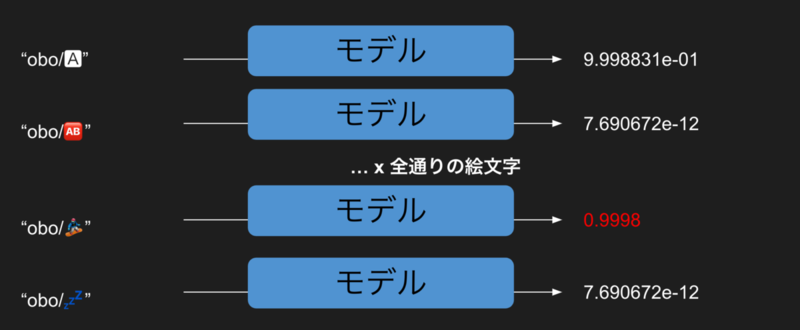
モデルへの入力方法は下記のように行います。もちろん他の方法もあるんですが、strをふたつ入力する関数を学習するとき、シンプルには、str1+区切り文字+str2として連結した文字列を入力する、という雑な方法が広く使われています。つまり下記のように、"obo"と"snowboarder"がマッチして欲しい場合、"obo/snowboarder"という文字列を入れて、1に近い値が出力されるように学習します。

もちろん正例だけではダメなので、負例として、"サジェストされなかった"組み合わせも入れます。
| postive | 全サジェスト | 26836 |
| negative | 絵文字サジェストのあるquery数 x 1度でもサジェストされた絵文字数 - positive | 6721874 |
学習は大雑把にはこんな感じでできます。ただし、もちろん細々したテクニックは必要で、特にこの手の学習で問題になるのは、positiveとnegativeの不均衡さです。ナイーブに学習してると、negativeばかりでいつまでもpositive周辺を学習してくれません。なので、positiveとnegativeのサンプリングのバランスを変える、一度分類を間違えたサンプルは重点的にもう一度学習する、適当なヒューリスティックでは一致する難しいサンプルは重点的に学習する*5などを行ってます。
さて、学習ができたので、最後に、推論するフェーズですが、これはシンプルにクエリに対して、すべての絵文字を試してみて、スコアが一定以上のものをサジェストとする、という形で行います。
STEP4: 性能検証 正解ペアの平均順位
忘れてはいけない性能検証方法を決めます。問題に落とし込むのと同じくらい、評価方法を決めることは、機械学習やっていく上で重要な点だと考えています *6。
今まで議論したように、(query, target) -> サジェストされるか否かと言う問題を解いているので、例えば、全target x 全target全てに0/1を予測して、その正解率を出せばいいようにも思いますが、今回の問題だと、以下の理由の通り、正解率の評価はあまり適していないです。
- 圧倒的にnegativeが多い問題であり (1800絵文字に対して、サジェストされる=正解は数個)、絶対候補に出てこないもの、をFalseにするだけで容易に90%以上正解してしまう。
- 外している場合にも、どの程度外しているのかを評価したい。似ているものがサジェストされてるなら大きな問題にはならない
サジェストの目的に立ち戻ると、1つ1つのサジェストがあっているかも重要ですが、サジェスト候補上位に出てきているものがあっているか、つまり予測上位のものと正解が群として一致していることが重要と考えられます。 今回は、SlackのAPIが返したものが、学習したモデルの推論でも上位になっているという点に着目した評価を行いました。 具体的には、下図のように、"正解に含まれるペアが、そのクエリでの予測では何番目になったか"の全クエリ/正解ペアでの平均値を評価としました。
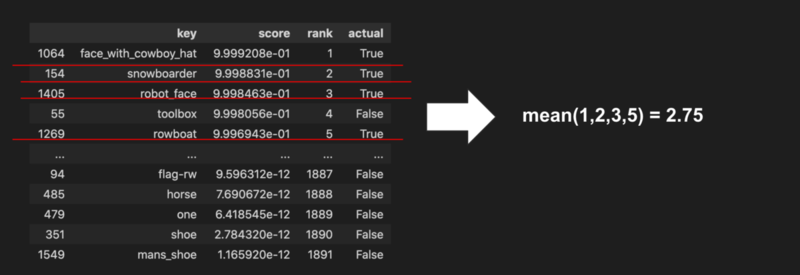
この例では、oboに対するモデルのサジェストが[face_with_cowboy_hat, snowboarder, robot_face, toolbox, rowboat, ...]と並んでおり、そのうち、実際にSlackが返してたのは[face_with_cowboy_hat, snowboarder, robot_face, rowboat]の4つですので*7 、1,2,3,5番目が正解ってことで平均の2.75点です。これらをすべてのkeyについて平均取ったものを全体評価としました。 完全に答えを知っている場合、つまりSlackのサジェスト順をそのままモデル出力した場合の、この評価値の最小値は7.7位でした*8。
ぼくの考えた最強のアルゴリズム
さて、評価方法ができたので、学習結果の良さを評価するためにも、対戦相手として、筆者が想像で作成した3つのアルゴリズムをエントリさせてみます!
評価結果
| 評価(正解例の平均予測順位) | |
|---|---|
| 理論最小値 | 7.7位 |
| 学習 | |
| アルゴリズムC | 14.94位 |
| アルゴリズムB | 17.29位 |
| アルゴリズムA | 59.65位 |
無事に?筆者のアルゴリズムを学習ベースが倒してくれました!
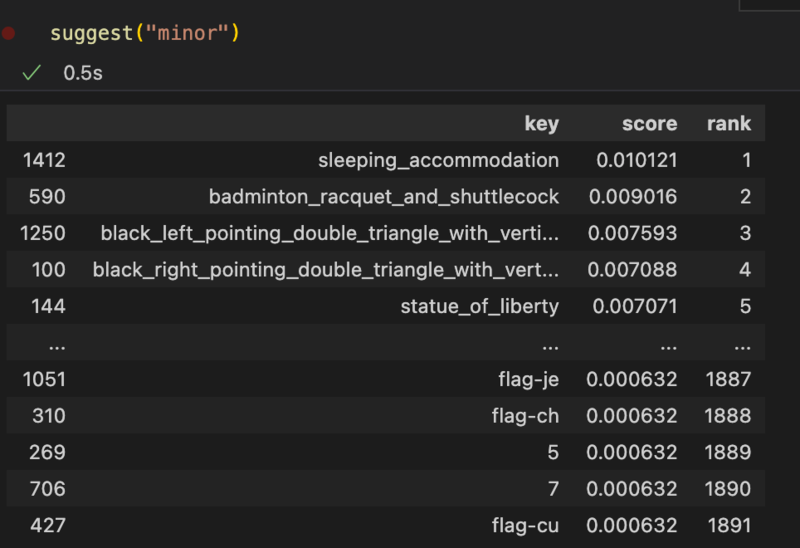
ちなみに、最初の問題であった、minor -> badminton_racquet_and_shuttlecockを理解するモデルも生まれてました。
さらなる高みへ: queryとtargetの独立エンコード
学習ベースの問題点は?
さて、無事に理想に近い値を出してくれるモデルができた、めでたい、というところなのですが、実はこのモデル、このままサービスインするには多少問題があります。
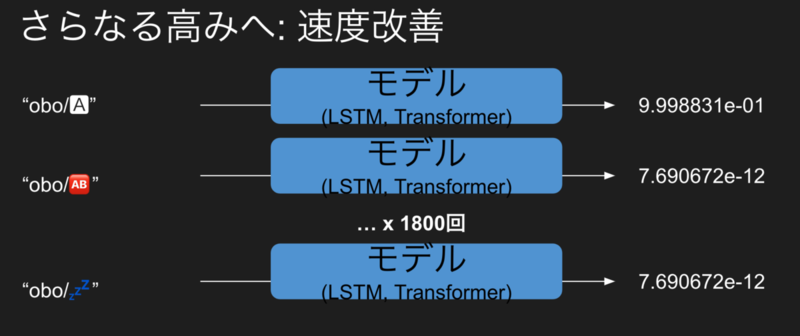
勘のいい読者ならお気づきかと思いますが、ニューラルネットワークベースのアルゴリズムをこういうライトな用途に使うには、計算が多過ぎ、遅い、です。 特に、このモデルでは、すでに説明したように、推論時には候補の絵文字の数だけ推論を実行する必要があります。
1982絵文字を対象とした場合、大体1秒程度かかりました(1絵文字あたりだと0.001秒ってことなので思っていたよりは早かった)。
独立エンコードモデルの学習と推論
ということで、最後に実用化のための高速化の実装を紹介します。
前節で書いたように、結局問題なのは、query x target分だけ推論しなきゃいけない、推論回数が多い、ということです。ですので、リクエストごとに一回の推論で済む方法を考えます。
ここで使えるアイディアとして、queryは毎回変わるけど、targetのemojiはそんな頻繁に変わらないよねというところに注目します。
つまり、targetの側を何らか先に計算しておくことができれば良いわけです。
残念ながら先のモデルでそのままこのアイディアを導入することは難しいので、学習自体をやり直します。
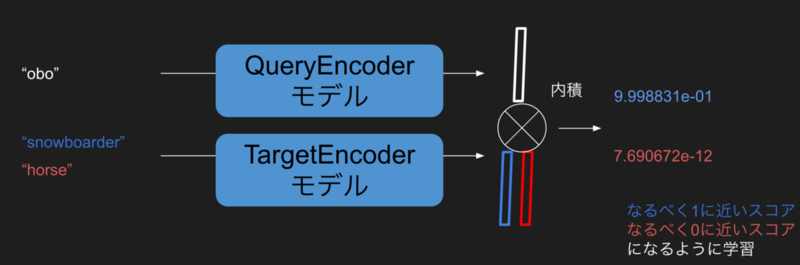
先のモデルでは一つのニューラルネットワークだったところを、ここでは、QueryEncoderとTargetEncoderに分解します。それぞれのEncoderはqueryとtargetの文字列からベクトルを出力するものです。QueryEncoder("obo").dot(TargetEncoder("snowboarder")) -> 1という感じですね。学習時は先のモデルと同様、二つを入力としてEnd-to-endで1/0の二値分類として学習しますが、推論時にはただの内積ですので、QueryEncoderとTargetEncoderは別々に計算しておくことができ、下図のように、サジェストの推論は、queryについてQueryEncoderを実行し、そのあとすべての絵文字ベクトルとの内積を取ればいいだけ、そしてこれは1つの行列との内積として計算できる、という美しい話になります。
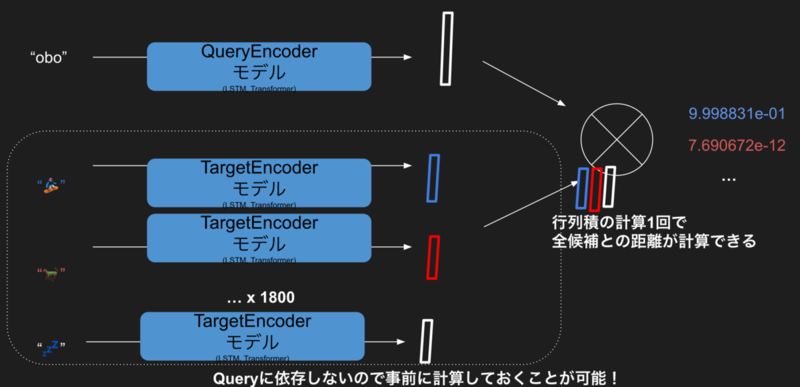
これにはさらに重要な点があって、性能のボトルネックをニューラルネットワークから、大規模な内積の計算に移せます。ベクトルの内積を高速に取る検索テクニック群は広く研究・開発されてるので、そこに接続することができるのは大きなメリットです。ElasticSearchなどの検索エンジンに乗せたり、圧縮して高速近似計算したりなど、応用の幅が広がります*9*10*11。
学習を行い、評価と実行時間計測をした結果が以下です。 予定通り実行時間は決定的なアルゴリズム群と遜色なく、0.01秒台で実行できたのですが、評価はアルゴリズムAレベルになってしまいました。 残念ながらこれだとアルゴリズムCを用いた方がよさそうですね。
評価値が下がった原因としては、素直に学習が難しくなったことがあると思います。単一モデルだと、モデルはqueryとtargetの両方を見て判断をすることができるのですが、独立エンコードモデルだと、queryだけ、targetだけの情報から、うまく特徴を作らなきゃいけないため、より難しいタスクになります。まぁ、とはいえ理論上できない話ではないので、あくまで筆者の頑張りが足りなかった、程度であり、速度も精度も最高のものをこの方針で作るのは可能だと思います。
| 評価 | 実行時間 | |
|---|---|---|
| 理論最小値 | 7.7位 | |
| 単一モデル | 1s | |
| QueryEncoder+内積 | ||
| アルゴリズムC | 14.94位 | 0.008s |
| アルゴリズムB | 17.29位 | 0.008s |
| アルゴリズムA | 59.65位 | 0.008s |
と、いう感じでこの設計は面白く、綺麗に締めたいのですが、少し余談を。もし、絵文字候補自体が全く変わらないと仮定できるなら、そもそも二入力関数として考える必要がなく、queryを入力して、"どの絵文字を出すか"の分類問題としてシンプルに解けます。実際のところ、これが業務だったら私はこの方法をとって、絵文字が増えるたびに再学習する、という泥臭い対応をするでしょう!
まとめると、サジェスト問題設定の学習パタンには
- 2入力のスコアリングモデルとして学習する -> 柔軟で精度も高いが遅い
- 1入力の分類モデルとして学習する -> 高速で学習が簡単だが、サジェスト候補を変えるたびに学習し直す必要がある
- 1入力のモデルをqueryとtargetの二つ学習する -> 高速な上に柔軟だが、精度を上げるには学習がちょっと大変
というバリエーションがあることがわかります。
We are hiring!
エムスリーでは、シンプルに見える問題からも、いろいろな解き方の機械学習の問題に落とせて、最適な解決策を使えるMLエンジニアを募集しています。
もちろんMLエンジニア以外にも、基盤を使ったシステムの開発や施策により世の中にインパクトを与える機会が多数ありますので、是非我こそは!という方はカジュアル面談、ご応募お待ちしています!
また、AI・機械学習チームでは通年でインターンの募集も行っていますので、こちらも是非応募ください!
*1:badmintonにはなんの恨みもありません。筆者も昔やってました
*2:英語UIにしてるとbadminton_racquet_and_shuttlecockなのでまぁわかりはするが、それでも面白い
*3:当然、4文字以上の入力に対しての性能を保証できなくなるので、まだまだ不足です
*4:エムスリーのワークスペースだと10299も絵文字があってちょっと面倒だったので、デフォルトの絵文字だけのワークスペースを作って実験しました
*5:queryがtargetの部分文字列だがサジェストには入らないもの、というヒューリスティックを使いました
*6: 見かけのAUCは高いけど、実際には最上位の精度が重要なので使い物にならない、とかがよく発生する
*7:toolboxも入っててもおかしくないように思いますけどね...
*8:1つのクエリあたりでサジェストが平均5.77個、最大25個あるので、理想的に出しても平均順位は7.7位になる
*9:https://speakerdeck.com/matsui_528/jin-si-zui-jin-bang-tan-suo-falsezui-qian-xian など参照
*10:AI・機械学習チームの中村さんの別の記事でも触れてます https://www.m3tech.blog/entry/vald-sentence-bert
*11:ESで待望のknnが使えるようになったのは最近ですが、嬉しい!