はじめに
本記事はエムスリー Advent Calendar 2020の12日目の記事です。
エンジニアリンググループの西名(@mikesorae)です。
私のチームでは医療に関する様々なデータを集計して分析レポートの作成を行っています。
クライアントの要望に応じて条件や分析軸を変更するために、これまではRubyで動的にSQLを組み立てて集計を行っていましたが、条件が複雑なため出力されるSQLが3000行近くになり、デバッグやテストも困難なためメンテナンス工数が多くかかっていました。 また、データ数の増加に伴ってSQLの実行時間も次第に長くなり、このまま行くと継続的なサービス提供ができなくなるリスクがあったため、BigQuery + Google Cloud Dataflow + Scioによる作り直しを決断しました。
Google Cloud Dataflowの導入にあたって公式ドキュメント等を参照しましたが、テンプレートのデプロイ周りで特に分かりづらい点が多かったのと、Flexテンプレートに関する記事がまだ少なく苦労したので、本記事ではそのあたりを重点的に説明したいと思います。
- はじめに
- やりたかったこと
- Google Cloud Dataflowについて
- Apache Beamについて
- Apache Beam SDKとScioについて
- Dataflowジョブの実行方法
- ScioのFat JAR化
- Flexテンプレートのデプロイ
- Flexテンプレートの実行
- 動的なパイプライン実行
- まとめ
- We are Hiring!!!
- 参考にした記事
やりたかったこと

まず前提として、今回Google Cloud Dataflowはバッチ処理基板として利用しました。
基本的には同じ分析レポートを何度も使用するのですが、クライアントの要望に応じて分析軸を増やしたり、成果物を分割するため、ジョブの実行パラメータに応じて処理や出力先を変更できる必要がありました。 また、一日に何度も実行するのでテンプレート化したかったのですが、旧型のテンプレート(クラシックテンプレート)ではその要求が実現できなかったため、新しく追加されたFlexテンプレートを採用することにしました。
Google Cloud Dataflowについて
Google Cloud Dataflow(以下Dataflow)はGoogleが提供するフルマネージドなデータ処理基盤です。
Dataflowは具体的にはApache Beamというバッチ/ストリーミング処理の統合プログラミングモデルの実行環境であり、パイプラインの開発では基本的にApache Beam SDKを使用することになります。*1
Apache Beamについて
Apache Beamは前述の通り、バッチ処理とストリーミング処理の両方を統合的に扱うことができるプログラミングモデルです。
Apache Beamの基本的なデータ処理は Pipeline、PCollection、PTransform の3つの概念から成り立っています。
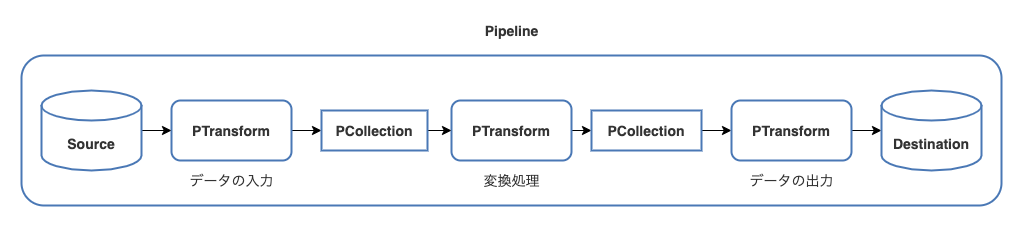
Pipeline はデータの入力・変換・データの出力を一つにまとめたもので、所謂ETLそのものです。
PCollection はPipeline中で扱う分散処理の対象となるデータセットです。
バッチ処理とストリーミング処理の大きな違いは入力データが有限か無限かという点であり、Apache Beamではこれらを両方とも同じ Collection として扱うことで統合的なプログラミングモデルを実現しています。
PTransform はPCollectionを別のPCollectionに変換するための処理です。
PTransformは更に内部で並列実行可能なParDoという処理単位を持っていますが、ここでは詳細な説明は割愛します。
Apache Beamの実行環境は、Dataflow以外にも Spark, Flink, Samza, Nemo などがあります。
Apache Beam SDKとScioについて
まずはじめに、Apache BeamはApache Beam SDKを提供しており、現在はJava、Python、Goの3言語に対応しています。
プロジェクト開始時点では、Python版では提供されてないAPIがあったことや、弊チームがJVM系言語寄りのスキルセットであったためJava版SDKを選択したのですが、Java版SDKだと記述が冗長になるためScioというラッパーライブラリを採用しました。
※ Kotlin + Apache Beamも検討しましたが、記述がそこまで簡単にならなかった他、一部動かないアノテーションがあったり、ジェネリクス周りでハマることが多かったため採用を見送りました。
ScioはSpotifyが提供しているScala製のApache Beam SDKラッパーです。 Apache Beam SDKで提供されているPipeline、PCollection、PTransformをラップし、map、filter、joinといった操作で簡単にパイプラインを構築できるようになっています。
以下はシェイクスピアの作品のテキストからすべての単語を抜き出して単語ごとの出現回数をカウントして出力するパイプラインの例です。 (Java版とScala版でなるべく等価になるよう元のサンプルコードから多少改変してあります。)
Java/Apache Beam版
// Pipelineの作成(optionsには実行時のオプションが渡される) Pipeline p = Pipeline.create(options); // GCSから作品テキストファイルを読み込み p.apply(TextIO.read().from("gs://apache-beam-samples/shakespeare/*")) // 作品テキストの一行を単語に分解する .apply( FlatMapElements .into(TypeDescriptors.strings()) .via((String line) -> Arrays.asList(line.split("[^a-zA-Z']+"))) ) // 空の単語を除外 .apply(Filter.by((String word) -> !word.isEmpty())) // 単語を集計して [Key: 単語、Value: カウント] のKeyValue型に変換 .apply(Count.perElement()) // "{単語名}: {個数}" の文字列に変換 .apply( MapElements.into(TypeDescriptors.strings()) .via( (KV<String, Long> wordCount) -> wordCount.getKey() + ": " + wordCount.getValue())) // 文字列をテキストファイルに書き出し .apply(TextIO.write().to("output"));
参考: beam/MinimalWordCount.java at master · apache/beam · GitHub
Java版ではPCollectionのapplyメソッドを使って各種変換を適用します。 filterやmapの変換を使いたいときは、用意されたクラスのスタティックメソッドを使ってTransformを作成します。 複雑な変換を自作したい場合はPTransformを継承したクラスを作る必要があったり、変換元と変換先のPCollectionの要素の型を明示する必要があったりでかなり記述量が多くなります。
Scala/Scio版
// Pipeline(ScioではScioContext)の作成 val sc = ScioContext(options) // GCSから作品テキストファイルを読み込み sc.textFile("gs://apache-beam-samples/shakespeare/*") .transform("split a line into words") { // 作品テキストの一行を単語に分解する _.flatMap(_.split("[^a-zA-Z']+")) } // 空の単語を除外 .filter(_.nonEmpty) // 単語を集計して (単語, カウント) のTupleに変換 .countByValue // "{単語名}: {個数}" の文字列に変換 .map(t => t._1 + ": " + t._2) .saveAsTextFile("output")
参考: scio/WordCount.scala at master · spotify/scio · GitHub
Scio版ではfilterやmapのような変換はSCollection(ScioでPCollectionクラスをラップしたクラス)のメソッドとして直接呼び出すことができます。
それ以外の変換もtransformメソッドに無名関数を渡すだけでよく、型推論も効くためシンプルに書くことができます。
更に、必要があれば SCollection.internal メソッドでPCollectionを取り出し、Apache Beam SDKの型を直接使うことも可能です。
Dataflowジョブの実行方法
Apache Beam SDKやScioでパイプラインを実装したら、Dataflowへデプロイしてジョブを実行することができます。 Dataflowの公式ドキュメントだと少しわかりづらいのですが、パイプラインをデプロイしてDataflowジョブを実行する方法は3種類あります。
- 直接実行(Dataflow Runner)
- クラシックテンプレート
- Flexテンプレート
直接実行(Dataflow Runner)
mvnコマンドのプロファイルでDataflowRunnerを指定するか、実行可能JARをビルドし、--runner=DataflowRunnerを指定してパイプラインを実行するとDataflowジョブが作成されます。(未指定の場合はデフォルトのDirectRunnerになり、ローカル環境で実行されます。)
実行のためにJavaのRuntimeが必要です。
また、実行のたびにコンパイルやファイルのステージングが発生するため待ち時間が長くなります。
Dataflow公式クイックスタートより
mvn -Pdataflow-runner compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--project=<PROJECT_ID> \
--stagingLocation=gs://<STORAGE_BUCKET>/staging/ \
--output=gs://<STORAGE_BUCKET>/output \
--runner=DataflowRunner \
--region=<REGION>"
クラシックテンプレート
クラシックテンプレートは、繰り返し実行やスケジュール実行が必要な定形のパイプラインを配布するための仕組みです。 実行用のJarファイルやジョブのメタ情報一式をテンプレートとしてGCSに保存し、テンプレートから簡単にDataflowジョブを作成することができます。
今までは単純にテンプレートと呼ばれていましたが、後述のFlexテンプレートが正式リリースされたためクラシックテンプレートという名称に変わりました。
クラシックテンプレートでジョブのパラメータを渡すためには、パラメータをValueProviderでラップする必要があります。
// クラシックテンプレートを使わない場合 trait MyOptions extends DataflowPipelineOptions { def getMyValue(): String } // クラシックテンプレートを使う場合 trait MyOptions extends DataflowPipelineOptions { def getMyValue(): ValueProvider[String] }
ValueProviderに包まれた値はPipeline実行中しか取り出せないため、ジョブの実行パラメータを使って動的にパイプラインを組み立てることができません。 そのため、クラシックテンプレートではテンプレート作成時にどのようなパイプラインが実行されるかを厳密に決める必要がありました。
また、BigQueryIOやTextIOのようなIOの引数で実行パラメータを扱う場合、ValueProviderに対応したInterfaceが必要でした。
Flexテンプレートではこれらの問題が解消したため、今後はFlexテンプレートを使うことが推奨されています。*2
Flexテンプレート
Flexテンプレートは、Dataflow Runnerの実行環境をDockerイメージ化することにより、クラシックテンプレートよりも自由度の高いテンプレートを配布できるようにしたものです。 このテンプレートの採用を決めたときにはbeta版でしたが*3、ジョブの実行パラメータに応じてパイプラインを動的に組み立てたかったため、Flexテンプレートを選択しました。
Flexテンプレートでは、Googleが提供するDockerイメージを使ってテンプレートを作成します。 Dockerイメージ上で実行されるのは通常のDataflow Runnerと同じなので、クラシックテンプレートと違ってValueProviderを使うことなくジョブの実行パラメータを渡すことができます。
ただし、DockerイメージがJarを呼び出す仕組みはブラックボックスになっており、DockerイメージにはFat JARを渡す必要があります。
Mavenビルドの場合はデフォルトのmaven clean packageでFat Jarが作成されますが、Scioを使う場合は自前でFat Jarをビルドする必要があります。
ScioのFat JAR化
結論から書くと、Scioを使う場合はsbt-assemblyを使ってFat JAR化します。
Scioの公式FAQによると、sbt-assemblyではなくsbt-packやsbt-native-packagerを使うことが推奨されていますが、これらはFat JARではなくディレクトリ配下に依存JARを配置します。(元々FlexテンプレートがなかったときのFAQのため)
sbt-assemblyのビルド設定で苦労しそうだったのですが、よく見ると公式のサンプルのbuild.sbtではsbt-assemblyが使われていたため、この設定をそのまま流用しました。
project/plugin.sbt
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.10")
build.sbt
lazy val assemblySettings = Seq(
test in assembly := {},
assemblyMergeStrategy in assembly ~= { old =>
{
case s if s.endsWith(".properties") => MergeStrategy.filterDistinctLines
case s if s.endsWith("public-suffix-list.txt") => MergeStrategy.filterDistinctLines
case s if s.endsWith("pom.xml") => MergeStrategy.last
case s if s.endsWith(".class") => MergeStrategy.last
case s if s.endsWith(".proto") => MergeStrategy.last
case s if s.endsWith("libjansi.jnilib") => MergeStrategy.last
case s if s.endsWith("jansi.dll") => MergeStrategy.rename
case s if s.endsWith("libjansi.so") => MergeStrategy.rename
case s if s.endsWith("libsnappyjava.jnilib") => MergeStrategy.last
case s if s.endsWith("libsnappyjava.so") => MergeStrategy.last
case s if s.endsWith("snappyjava_snappy.dll") => MergeStrategy.last
case s if s.endsWith("reflection-config.json") => MergeStrategy.rename
case s if s.endsWith(".dtd") => MergeStrategy.rename
case s if s.endsWith(".xsd") => MergeStrategy.rename
case PathList("META-INF", "services", "org.apache.hadoop.fs.FileSystem") =>
MergeStrategy.filterDistinctLines
case s => old(s)
}
}
)
sbtの設定に上記を追加した後 sbt clean assembly を実行すると、target/scala-{scalaVersion}/{projectName}-assembly-{version}.jar にFat JARが作成されます。
これを後述のデプロイ手順でDockerイメージに渡します。
Flexテンプレートのデプロイ
後は公式ドキュメントの通りに進めるだけでFlexテンプレートをデプロイすることができます。 大まかな流れとしては以下の通りです。 (簡単のためgcloudやgsutilコマンドはインストール済みとして話を進めます。)
1. テンプレートファイル格納用GCSバケットの作成(初回のみ)
Dataflowテンプレートでは、メタ情報などのファイルを配置するためのGCSバケットが必要なため、事前にテンプレート格納用のバケットを作成します。
export BUCKET="my-storage-bucket" gsutil mb gs://$BUCKET
2. Fat JARの作成
前の章で説明したとおり、sbt clean assemblyでFat JARを作成します。
3. metadata.jsonの作成
metadata.jsonはFlexテンプレートの情報を記入するためのファイルです。 ファイル自体無くても問題なく動作しますが、書いておくとGUIからテンプレートを選択したときに説明が表示されたり、ジョブのパラメータに制約をつけられたりします。
metadata.jsonの書き方については詳しく調べていないので、気になる方はこの辺りをご参照ください。
4. Flexテンプレートの仕様ファイルパスの設定
Flexテンプレートの実体はmeta情報が書かれたjsonファイルです。デプロイコマンドの実行前に、jsonファイルを配置するGCSパスを指定してください。
export TEMPLATE_PATH="gs://$BUCKET/samples/dataflow/templates/streaming-beam-sql.json"
5. DockerイメージURLの設定
Flexテンプレート用のDockerイメージをPushするGCRのURLを指定してください。
export TEMPLATE_IMAGE="gcr.io/$PROJECT/samples/dataflow/streaming-beam-sql:latest"
6. Flexテンプレートのデプロイ
後はここまでに作成・設定した成果物を指定して以下のコマンドを実行します。
gcloud dataflow flex-template build $TEMPLATE_PATH \
--image-gcr-path "$TEMPLATE_IMAGE" \
--sdk-language "JAVA" \
--flex-template-base-image JAVA11 \
--metadata-file "metadata.json" \
--jar "path/to/fat.jar" \
--env FLEX_TEMPLATE_JAVA_MAIN_CLASS="org.apache.beam.samples.StreamingBeamSQL"
※ beta版ではJARやメインクラスを指定したDockerfileを作成して自前で gcloud build した後、 gcloud beta dataflow flex-template を呼び出す必要があったのですが、GAでgcloud dataflow flex-template に統合されたようです。
Flexテンプレートの実行
以上でFlexテンプレートの実行準備ができました。詳しい説明は割愛しますが、ジョブの実行は以下の方法から選択することができます。
- gcloudコマンド
- REST API(curlコマンド等)
- Google Cloud API(google-cloud-ruby、google-cloud-goなど)
- Google Cloudコンソール
gcloudコマンドの例
export REGION="us-central1"
gcloud dataflow flex-template run "streaming-beam-sql-`date +%Y%m%d-%H%M%S`" \
--template-file-gcs-location "$TEMPLATE_PATH" \
--parameters inputSubscription="$SUBSCRIPTION" \
--parameters outputTable="$PROJECT:$DATASET.$TABLE" \
--region "$REGION"
動的なパイプライン実行
Flexテンプレートを使うことで、パイプライン実行前にジョブの実行パラメータを受け取り、動的にパイプラインを構築することができるようになりました。
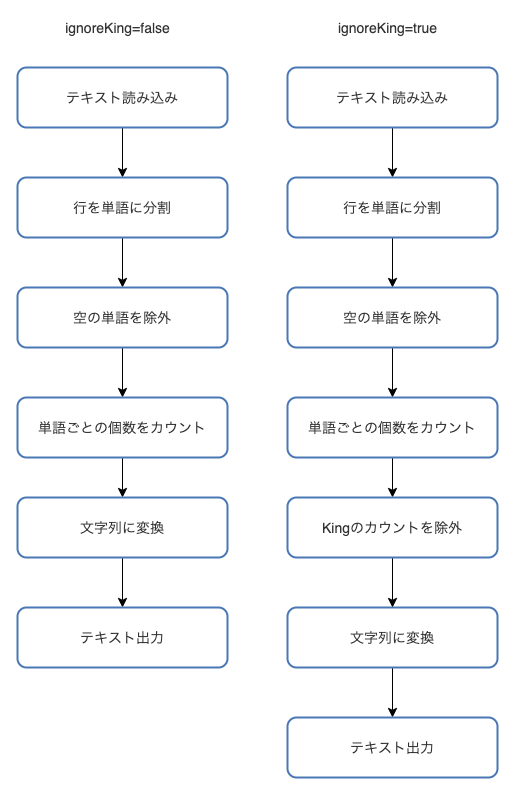
以下は先程のWordCountのサンプルを少し変更したもので、ignoreKing というパラメータがtrueのときだけKingという単語のカウントを除外するようなパイプラインを構築します。
// Pipeline(ScioではScioContext)の作成 val sc = ScioContext(options) // GCSから作品テキストファイルを読み込み val wordCounts = sc.textFile("gs://apache-beam-samples/shakespeare/*") .transform("split a line into words") { // 作品テキストの一行を単語に分解する _.flatMap(_.split("[^a-zA-Z']+")) } // 空の単語を除外 .filter(_.nonEmpty) // 単語を集計して (単語, カウント) のTupleに変換 .countByValue // 引数のignoreKing=trueなら単語がkingのカウントを除外する val filteredWordCounts = if (options.getIgnoreKing) { wordCounts.filter(_._1 != "king") } else { wordCounts } filteredWordCounts // "{単語名}: {個数}" の文字列に変換 .map(t => t._1 + ": " + t._2) .saveAsTextFile("output")
コードだとわかりにくいので図にすると、ignoreKingがfalseの場合とtrueの場合でそれぞれの以下のようなジョブグラフになります。
まとめ
色々とハマりどころはありましたが、Dataflow Flexテンプレート + Scioによってスケーラブルかつタイプセーフなパイプラインを動的に実現することができました。
以前のRubyスクリプトであれば、1ヶ月もすると全く読めなくなり、ちょっとした修正もドキドキしながらリリースしていましたが、Scioでは基本的に型でイン・アウトが保証されている上、function単位やPipeline単位でのテストが書けるため変更時のストレスもかなり少なくなりました。
運用についても特に目立った問題は発生していないので、今後もさらに適用箇所を増やしていければと考えています。
We are Hiring!!!
エムスリーでは技術で顧客や運用の課題をガシガシ解決できるエンジニアを募集しています。 カジュアル面談もあるので、お気軽にお問い合わせください。
参考にした記事
*1:Scioのようなサードパーティのラッパライブラリを使うことも可能
*2:https://cloud.google.com/blog/ja/products/data-analytics/create-templates-from-any-dataflow-pipeline
*3:2020/09/30にめでたくGAになりました。https://cloud.google.com/dataflow/docs/resources/release-notes-service